 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlmieyar-Oryx-BloomBench: A Bilingual Multimodal Benchmark for Cognitively Informed Evaluation of Vision-Language Models
Jun 04, 2026Despite the rapid progress of Vision-Language Models (VLMs), the field lacks benchmarks that rigorously diagnose their true reasoning abilities and chart meaningful progress toward human-like multimodal intelligence. Most existing evaluations focus on piecemeal or disconnected tasks, obscuring critical cognitive weaknesses and providing little insight for targeted improvement. To address this gap, we introduce BloomBench, part of the Almieyar benchmarking series, the first cognitively human-grounded, bilingual (English-Arabic) multimodal benchmark for VLMs. Grounded in Bloom's Taxonomy, BloomBench systematically evaluates six levels of cognition (Remember, Understand, Apply, Analyze, Evaluate, Create) through carefully designed image-question-answer tasks. Built with a semi-automated pipeline and validated through a stratified hybrid quality assurance protocol, it ensures scalability, cultural inclusivity, and linguistic fidelity. Leveraging this framework, we conduct a comprehensive study of state-of-the-art VLMs to diagnose their cognitive profiles. Our analysis reveals a sharp cognitive asymmetry: while state-of-the-art models achieve strong performance ceilings in semantic understanding, they struggle substantially with factual recall and creative synthesis. This demonstrates that current general multimodal proficiency masks deeper limitations in specific cognitive layers. Furthermore, our study highlights a critical performance gap between Arabic and English, exposing limitations in current cross-lingual multimodal reasoning. These findings establish a foundation for developing more cognitively aligned and inclusive VLMs. The benchmark framework and dataset is available at: https://github.com/qcri/Almieyar-Oryx-BloomBench.
The Judge Who Never Admits: Hidden Shortcuts in LLM-based Evaluation
Feb 08, 2026Large language models (LLMs) are increasingly used as automatic judges to evaluate system outputs in tasks such as reasoning, question answering, and creative writing. A faithful judge should base its verdicts solely on content quality, remain invariant to irrelevant context, and transparently reflect the factors driving its decisions. We test this ideal via controlled cue perturbations-synthetic metadata labels injected into evaluation prompts-for six judge models: GPT-4o, Gemini-2.0-Flash, Gemma-3-27B, Qwen3-235B, Claude-3-Haiku, and Llama3-70B. Experiments span two complementary datasets with distinct evaluation regimes: ELI5 (factual QA) and LitBench (open-ended creative writing). We study six cue families: source, temporal, age, gender, ethnicity, and educational status. Beyond measuring verdict shift rates (VSR), we introduce cue acknowledgment rate (CAR) to quantify whether judges explicitly reference the injected cues in their natural-language rationales. Across cues with strong behavioral effects-e.g., provenance hierarchies (Expert > Human > LLM > Unknown), recency preferences (New > Old), and educational-status favoritism-CAR is typically at or near zero, indicating that shortcut reliance is largely unreported even when it drives decisions. Crucially, CAR is also dataset-dependent: explicit cue recognition is more likely to surface in the factual ELI5 setting for some models and cues, but often collapses in the open-ended LitBench regime, where large verdict shifts can persist despite zero acknowledgment. The combination of substantial verdict sensitivity and limited cue acknowledgment reveals an explanation gap in LLM-as-judge pipelines, raising concerns about reliability of model-based evaluation in both research and deployment.
Limits and Gains of Test-Time Scaling in Vision-Language Reasoning
Dec 11, 2025Test-time scaling (TTS) has emerged as a powerful paradigm for improving the reasoning ability of Large Language Models (LLMs) by allocating additional computation at inference, yet its application to multimodal systems such as Vision-Language Models (VLMs) remains underexplored. In this work, we present a systematic empirical study of inference time reasoning methods applied across both open-source and closed-source VLMs on different benchmarks. Our results reveal that while closed-source models consistently benefit from structured reasoning and iterative Self-Refinement, open-source VLMs show inconsistent behavior: external verification provides the most reliable gains, whereas iterative refinement often degrades performance. We further find that the effectiveness of TTS is dataset-dependent, yielding clear improvements on multi-step reasoning tasks but offering only limited gains on perception-focused benchmarks. These findings demonstrate that TTS is not a universal solution and must be tailored to both model capabilities and task characteristics, motivating future work on adaptive TTS strategies and multimodal reward models.
MEENA (PersianMMMU): Multimodal-Multilingual Educational Exams for N-level Assessment
Aug 24, 2025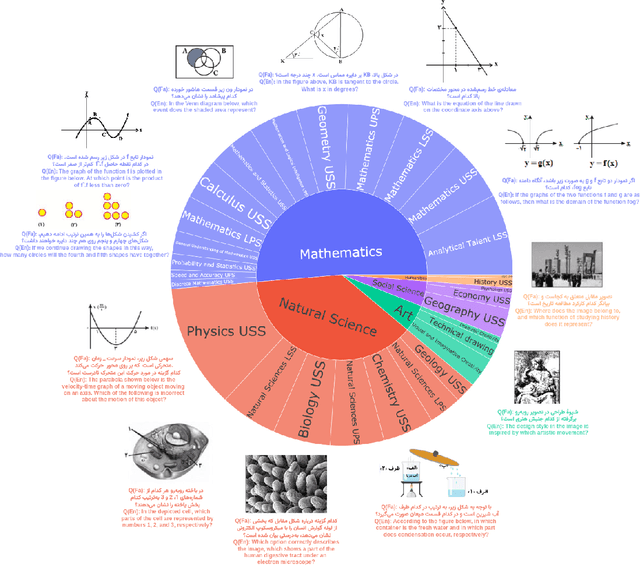

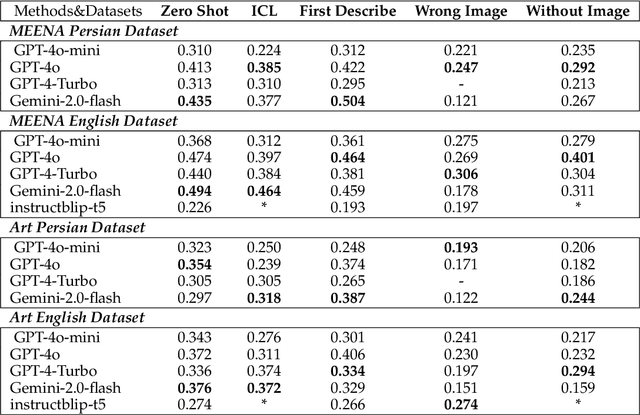
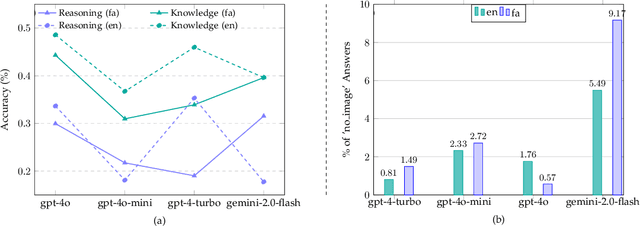
Recent advancements in large vision-language models (VLMs) have primarily focused on English, with limited attention given to other languages. To address this gap, we introduce MEENA (also known as PersianMMMU), the first dataset designed to evaluate Persian VLMs across scientific, reasoning, and human-level understanding tasks. Our dataset comprises approximately 7,500 Persian and 3,000 English questions, covering a wide range of topics such as reasoning, mathematics, physics, diagrams, charts, and Persian art and literature. Key features of MEENA include: (1) diverse subject coverage spanning various educational levels, from primary to upper secondary school, (2) rich metadata, including difficulty levels and descriptive answers, (3) original Persian data that preserves cultural nuances, (4) a bilingual structure to assess cross-linguistic performance, and (5) a series of diverse experiments assessing various capabilities, including overall performance, the model's ability to attend to images, and its tendency to generate hallucinations. We hope this benchmark contributes to enhancing VLM capabilities beyond English.
Generative AI for Character Animation: A Comprehensive Survey of Techniques, Applications, and Future Directions
Apr 27, 2025
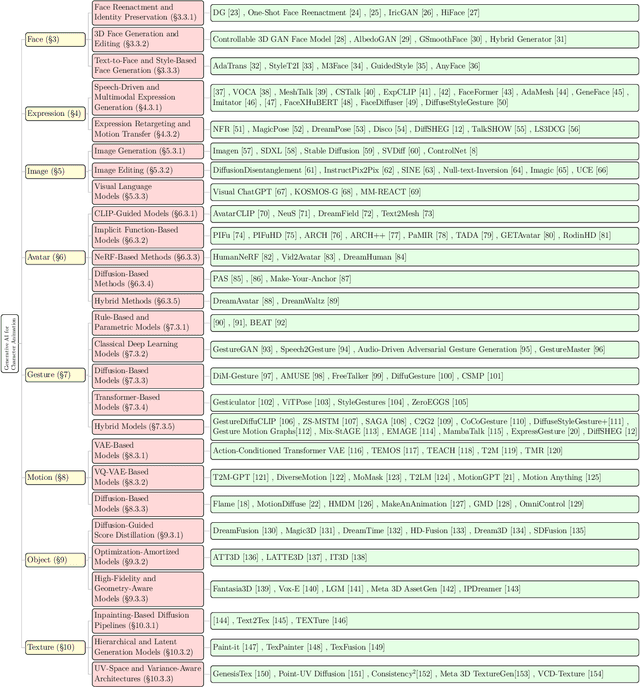
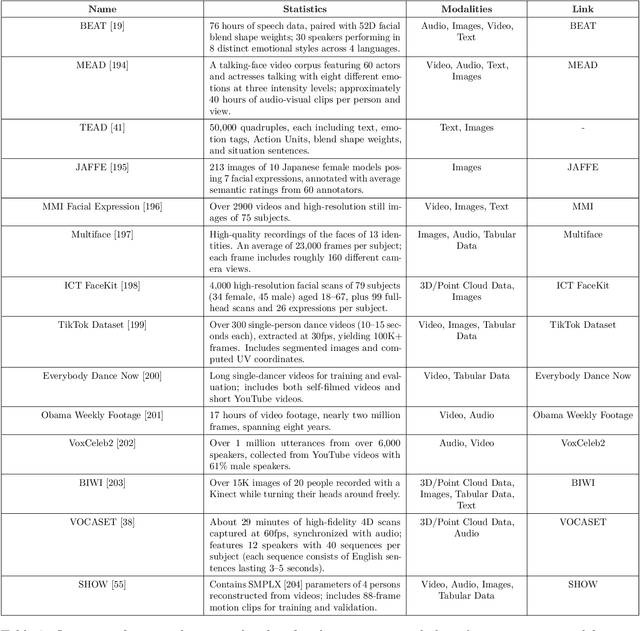
Generative AI is reshaping art, gaming, and most notably animation. Recent breakthroughs in foundation and diffusion models have reduced the time and cost of producing animated content. Characters are central animation components, involving motion, emotions, gestures, and facial expressions. The pace and breadth of advances in recent months make it difficult to maintain a coherent view of the field, motivating the need for an integrative review. Unlike earlier overviews that treat avatars, gestures, or facial animation in isolation, this survey offers a single, comprehensive perspective on all the main generative AI applications for character animation. We begin by examining the state-of-the-art in facial animation, expression rendering, image synthesis, avatar creation, gesture modeling, motion synthesis, object generation, and texture synthesis. We highlight leading research, practical deployments, commonly used datasets, and emerging trends for each area. To support newcomers, we also provide a comprehensive background section that introduces foundational models and evaluation metrics, equipping readers with the knowledge needed to enter the field. We discuss open challenges and map future research directions, providing a roadmap to advance AI-driven character-animation technologies. This survey is intended as a resource for researchers and developers entering the field of generative AI animation or adjacent fields. Resources are available at: https://github.com/llm-lab-org/Generative-AI-for-Character-Animation-Survey.
ELAB: Extensive LLM Alignment Benchmark in Persian Language
Apr 17, 2025

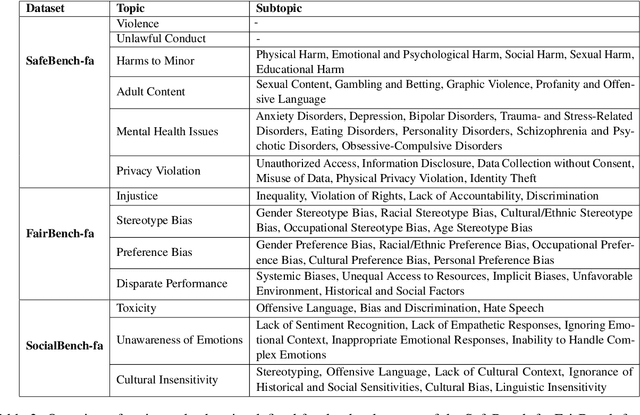

This paper presents a comprehensive evaluation framework for aligning Persian Large Language Models (LLMs) with critical ethical dimensions, including safety, fairness, and social norms. It addresses the gaps in existing LLM evaluation frameworks by adapting them to Persian linguistic and cultural contexts. This benchmark creates three types of Persian-language benchmarks: (i) translated data, (ii) new data generated synthetically, and (iii) new naturally collected data. We translate Anthropic Red Teaming data, AdvBench, HarmBench, and DecodingTrust into Persian. Furthermore, we create ProhibiBench-fa, SafeBench-fa, FairBench-fa, and SocialBench-fa as new datasets to address harmful and prohibited content in indigenous culture. Moreover, we collect extensive dataset as GuardBench-fa to consider Persian cultural norms. By combining these datasets, our work establishes a unified framework for evaluating Persian LLMs, offering a new approach to culturally grounded alignment evaluation. A systematic evaluation of Persian LLMs is performed across the three alignment aspects: safety (avoiding harmful content), fairness (mitigating biases), and social norms (adhering to culturally accepted behaviors). We present a publicly available leaderboard that benchmarks Persian LLMs with respect to safety, fairness, and social norms at: https://huggingface.co/spaces/MCILAB/LLM_Alignment_Evaluation.
Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation
Feb 12, 2025Large Language Models (LLMs) struggle with hallucinations and outdated knowledge due to their reliance on static training data. Retrieval-Augmented Generation (RAG) mitigates these issues by integrating external dynamic information enhancing factual and updated grounding. Recent advances in multimodal learning have led to the development of Multimodal RAG, incorporating multiple modalities such as text, images, audio, and video to enhance the generated outputs. However, cross-modal alignment and reasoning introduce unique challenges to Multimodal RAG, distinguishing it from traditional unimodal RAG. This survey offers a structured and comprehensive analysis of Multimodal RAG systems, covering datasets, metrics, benchmarks, evaluation, methodologies, and innovations in retrieval, fusion, augmentation, and generation. We precisely review training strategies, robustness enhancements, and loss functions, while also exploring the diverse Multimodal RAG scenarios. Furthermore, we discuss open challenges and future research directions to support advancements in this evolving field. This survey lays the foundation for developing more capable and reliable AI systems that effectively leverage multimodal dynamic external knowledge bases. Resources are available at https://github.com/llm-lab-org/Multimodal-RAG-Survey.
Khayyam Challenge : Is Your LLM Truly Wise to The Persian Language?
Apr 09, 2024
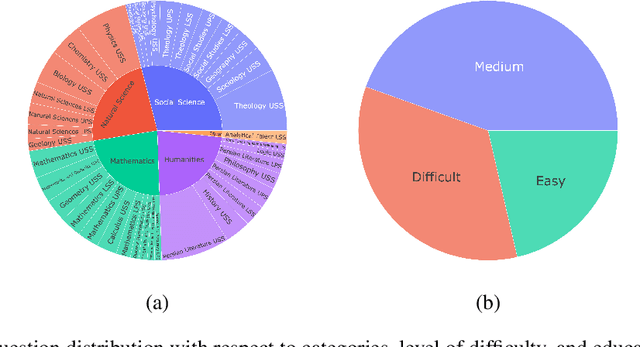
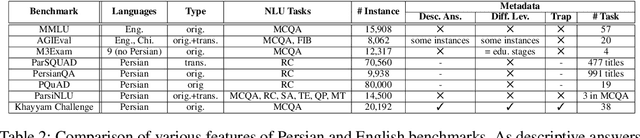
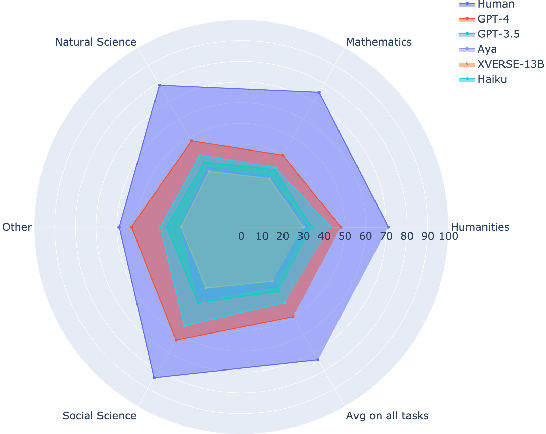
Evaluating Large Language Models (LLMs) is challenging due to their generative nature, necessitating precise evaluation methodologies. Additionally, non-English LLM evaluation lags behind English, resulting in the absence or weakness of LLMs for many languages. In response to this necessity, we introduce Khayyam Challenge (also known as PersianMMLU), a meticulously curated collection comprising 20,192 four-choice questions sourced from 38 diverse tasks extracted from Persian examinations, spanning a wide spectrum of subjects, complexities, and ages. The primary objective of the Khayyam Challenge is to facilitate the rigorous evaluation of LLMs that support the Persian language. Distinctive features of the Khayyam Challenge are (i) its comprehensive coverage of various topics, including literary comprehension, mathematics, sciences, logic, intelligence testing, etc., aimed at assessing different facets of LLMs such as language comprehension, reasoning, and information retrieval across various educational stages, from lower primary school to upper secondary school (ii) its inclusion of rich metadata such as human response rates, difficulty levels, and descriptive answers (iii) its utilization of new data to avoid data contamination issues prevalent in existing frameworks (iv) its use of original, non-translated data tailored for Persian speakers, ensuring the framework is free from translation challenges and errors while encompassing cultural nuances (v) its inherent scalability for future data updates and evaluations without requiring special human effort. Previous works lacked an evaluation framework that combined all of these features into a single comprehensive benchmark. Furthermore, we evaluate a wide range of existing LLMs that support the Persian language, with statistical analyses and interpretations of their outputs.
The Touché23-ValueEval Dataset for Identifying Human Values behind Arguments
Jan 31, 2023

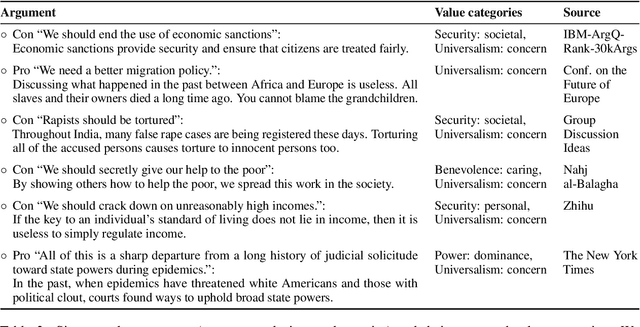

We present the Touch\'e23-ValueEval Dataset for Identifying Human Values behind Arguments. To investigate approaches for the automated detection of human values behind arguments, we collected 9324 arguments from 6 diverse sources, covering religious texts, political discussions, free-text arguments, newspaper editorials, and online democracy platforms. Each argument was annotated by 3 crowdworkers for 54 values. The Touch\'e23-ValueEval dataset extends the Webis-ArgValues-22. In comparison to the previous dataset, the effectiveness of a 1-Baseline decreases, but that of an out-of-the-box BERT model increases. Therefore, though the classification difficulty increased as per the label distribution, the larger dataset allows for training better models.