 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Language Models Reliable Argument Quality Annotators?
Apr 15, 2024

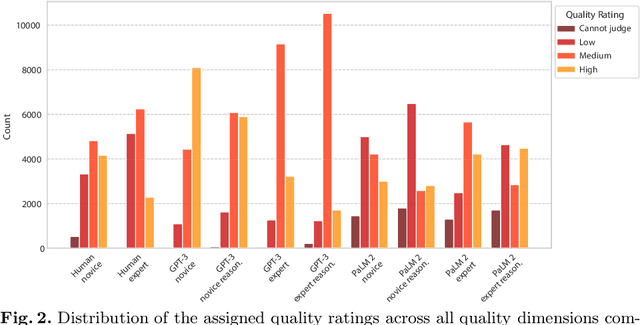
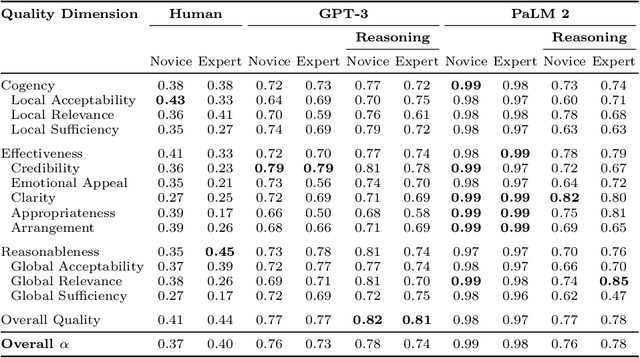
Evaluating the quality of arguments is a crucial aspect of any system leveraging argument mining. However, it is a challenge to obtain reliable and consistent annotations regarding argument quality, as this usually requires domain-specific expertise of the annotators. Even among experts, the assessment of argument quality is often inconsistent due to the inherent subjectivity of this task. In this paper, we study the potential of using state-of-the-art large language models (LLMs) as proxies for argument quality annotators. To assess the capability of LLMs in this regard, we analyze the agreement between model, human expert, and human novice annotators based on an established taxonomy of argument quality dimensions. Our findings highlight that LLMs can produce consistent annotations, with a moderately high agreement with human experts across most of the quality dimensions. Moreover, we show that using LLMs as additional annotators can significantly improve the agreement between annotators. These results suggest that LLMs can serve as a valuable tool for automated argument quality assessment, thus streamlining and accelerating the evaluation of large argument datasets.
The Touché23-ValueEval Dataset for Identifying Human Values behind Arguments
Jan 31, 2023We present the Touch\'e23-ValueEval Dataset for Identifying Human Values behind Arguments. To investigate approaches for the automated detection of human values behind arguments, we collected 9324 arguments from 6 diverse sources, covering religious texts, political discussions, free-text arguments, newspaper editorials, and online democracy platforms. Each argument was annotated by 3 crowdworkers for 54 values. The Touch\'e23-ValueEval dataset extends the Webis-ArgValues-22. In comparison to the previous dataset, the effectiveness of a 1-Baseline decreases, but that of an out-of-the-box BERT model increases. Therefore, though the classification difficulty increased as per the label distribution, the larger dataset allows for training better models.