 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Generative Ad Hoc Information Retrieval
Nov 08, 2023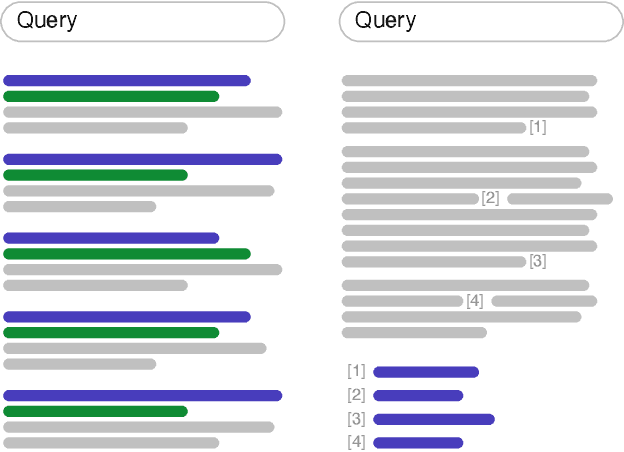

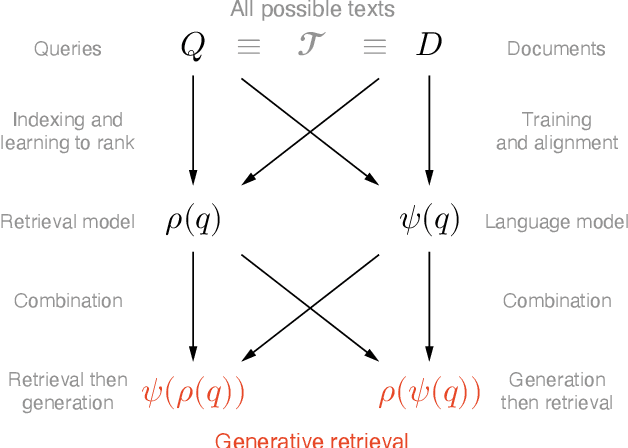
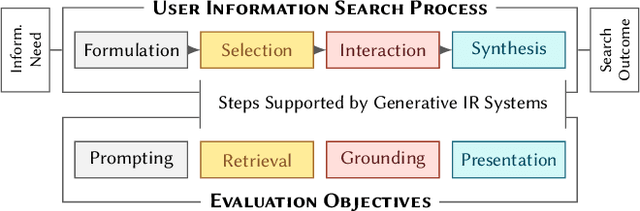
Recent advances in large language models have enabled the development of viable generative information retrieval systems. A generative retrieval system returns a grounded generated text in response to an information need instead of the traditional document ranking. Quantifying the utility of these types of responses is essential for evaluating generative retrieval systems. As the established evaluation methodology for ranking-based ad hoc retrieval may seem unsuitable for generative retrieval, new approaches for reliable, repeatable, and reproducible experimentation are required. In this paper, we survey the relevant information retrieval and natural language processing literature, identify search tasks and system architectures in generative retrieval, develop a corresponding user model, and study its operationalization. This theoretical analysis provides a foundation and new insights for the evaluation of generative ad hoc retrieval systems.
The Touché23-ValueEval Dataset for Identifying Human Values behind Arguments
Jan 31, 2023

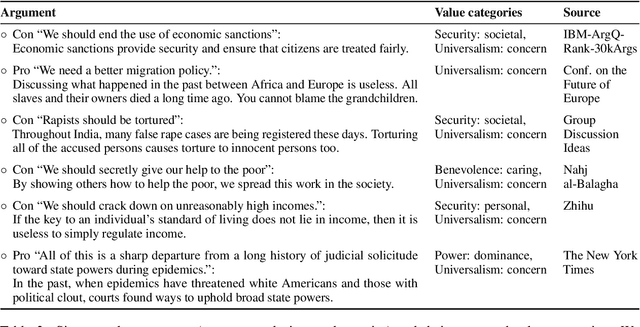

We present the Touch\'e23-ValueEval Dataset for Identifying Human Values behind Arguments. To investigate approaches for the automated detection of human values behind arguments, we collected 9324 arguments from 6 diverse sources, covering religious texts, political discussions, free-text arguments, newspaper editorials, and online democracy platforms. Each argument was annotated by 3 crowdworkers for 54 values. The Touch\'e23-ValueEval dataset extends the Webis-ArgValues-22. In comparison to the previous dataset, the effectiveness of a 1-Baseline decreases, but that of an out-of-the-box BERT model increases. Therefore, though the classification difficulty increased as per the label distribution, the larger dataset allows for training better models.
Topic Ontologies for Arguments
Jan 23, 2023
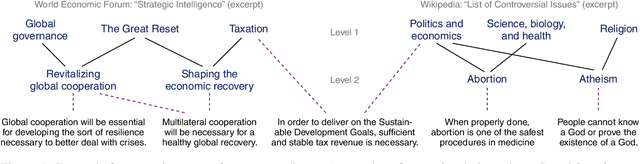


Many computational argumentation tasks, like stance classification, are topic-dependent: the effectiveness of approaches to these tasks significantly depends on whether the approaches were trained on arguments from the same topics as those they are tested on. So, which are these topics that researchers train approaches on? This paper contributes the first comprehensive survey of topic coverage, assessing 45 argument corpora. For the assessment, we take the first step towards building an argument topic ontology, consulting three diverse authoritative sources: the World Economic Forum, the Wikipedia list of controversial topics, and Debatepedia. Comparing the topic sets between the authoritative sources and corpora, our analysis shows that the corpora topics-which are mostly those frequently discussed in public online fora - are covered well by the sources. However, other topics from the sources are less extensively covered by the corpora of today, revealing interesting future directions for corpus construction.
The Infinite Index: Information Retrieval on Generative Text-To-Image Models
Dec 14, 2022The text-to-image model Stable Diffusion has recently become very popular. Only weeks after its open source release, millions are experimenting with image generation. This is due to its ease of use, since all it takes is a brief description of the desired image to "prompt" the generative model. Rarely do the images generated for a new prompt immediately meet the user's expectations. Usually, an iterative refinement of the prompt ("prompt engineering") is necessary for satisfying images. As a new perspective, we recast image prompt engineering as interactive image retrieval - on an "infinite index". Thereby, a prompt corresponds to a query and prompt engineering to query refinement. Selected image-prompt pairs allow direct relevance feedback, as the model can modify an image for the refined prompt. This is a form of one-sided interactive retrieval, where the initiative is on the user side, whereas the server side remains stateless. In light of an extensive literature review, we develop these parallels in detail and apply the findings to a case study of a creative search task on such a model. We note that the uncertainty in searching an infinite index is virtually never-ending. We also discuss future research opportunities related to retrieval models specialized for generative models and interactive generative image retrieval. The application of IR technology, such as query reformulation and relevance feedback, will contribute to improved workflows when using generative models, while the notion of an infinite index raises new challenges in IR research.
SCAI-QReCC Shared Task on Conversational Question Answering
Jan 26, 2022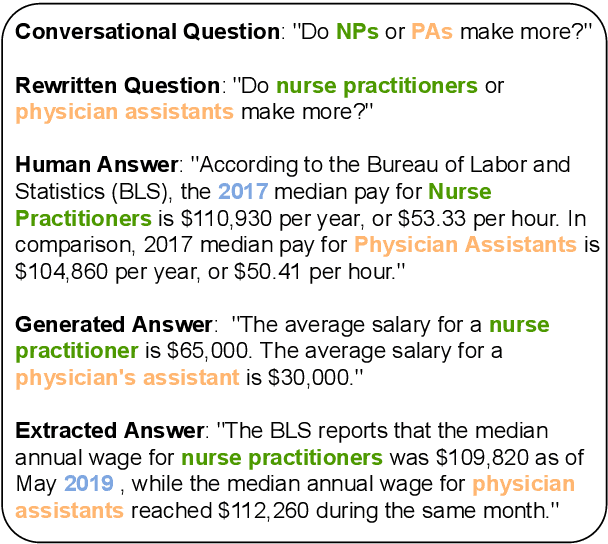
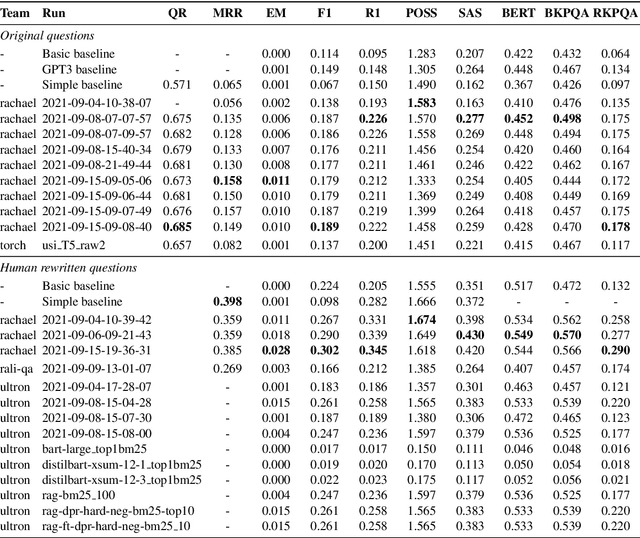
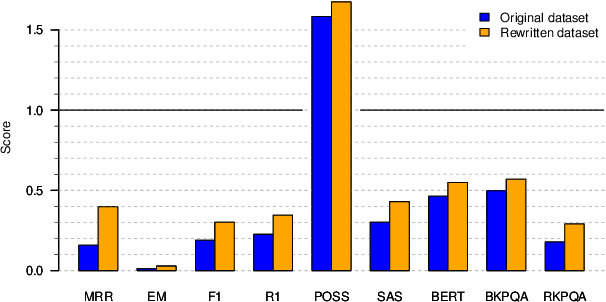
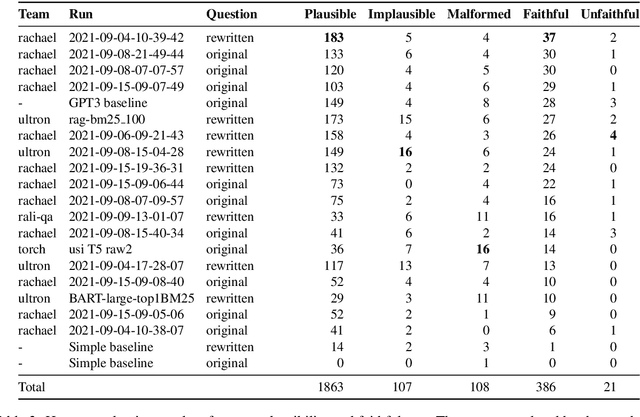
Search-Oriented Conversational AI (SCAI) is an established venue that regularly puts a spotlight upon the recent work advancing the field of conversational search. SCAI'21 was organised as an independent on-line event and featured a shared task on conversational question answering. Since all of the participant teams experimented with answer generation models for this task, we identified evaluation of answer correctness in this settings as the major challenge and a current research gap. Alongside the automatic evaluation, we conducted two crowdsourcing experiments to collect annotations for answer plausibility and faithfulness. As a result of this shared task, the original conversational QA dataset used for evaluation was further extended with alternative correct answers produced by the participant systems.
A Stylometric Inquiry into Hyperpartisan and Fake News
Feb 18, 2017
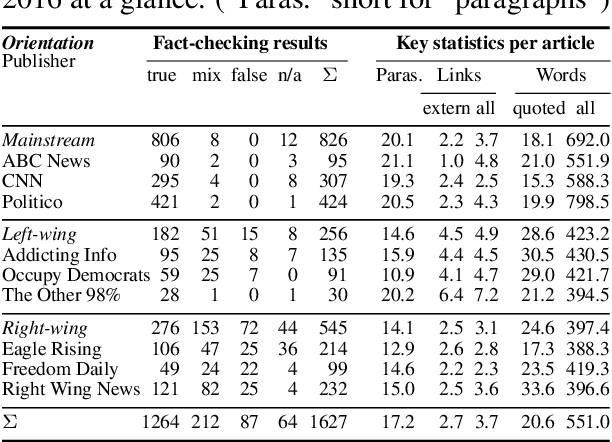
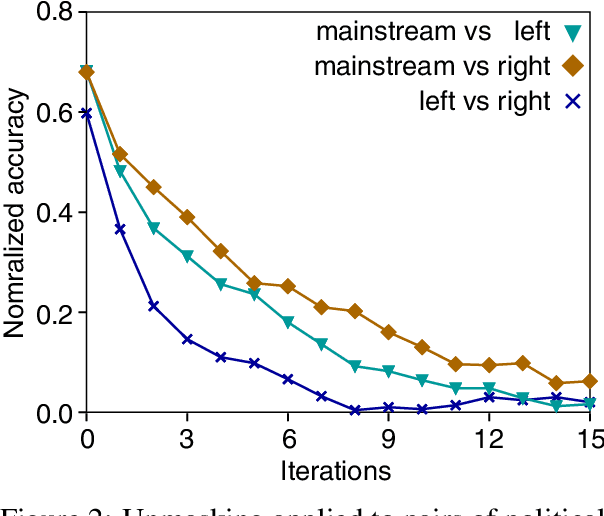
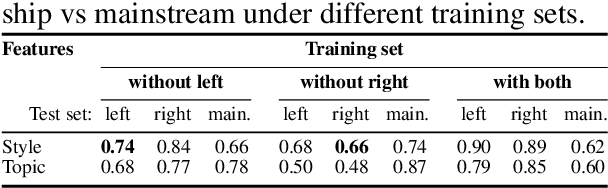
This paper reports on a writing style analysis of hyperpartisan (i.e., extremely one-sided) news in connection to fake news. It presents a large corpus of 1,627 articles that were manually fact-checked by professional journalists from BuzzFeed. The articles originated from 9 well-known political publishers, 3 each from the mainstream, the hyperpartisan left-wing, and the hyperpartisan right-wing. In sum, the corpus contains 299 fake news, 97% of which originated from hyperpartisan publishers. We propose and demonstrate a new way of assessing style similarity between text categories via Unmasking---a meta-learning approach originally devised for authorship verification---, revealing that the style of left-wing and right-wing news have a lot more in common than any of the two have with the mainstream. Furthermore, we show that hyperpartisan news can be discriminated well by its style from the mainstream (F1=0.78), as can be satire from both (F1=0.81). Unsurprisingly, style-based fake news detection does not live up to scratch (F1=0.46). Nevertheless, the former results are important to implement pre-screening for fake news detectors.