 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic-Specific Classifiers are Better Relevance Judges than Prompted LLMs
Oct 06, 2025The unjudged document problem, where pooled test collections have incomplete relevance judgments for evaluating new retrieval systems, is a key obstacle to the reusability of test collections in information retrieval. While the de facto standard to deal with the problem is to treat unjudged documents as non-relevant, many alternatives have been proposed, including the use of large language models (LLMs) as a relevance judge (LLM-as-a-judge). However, this has been criticized as circular, since the same LLM can be used as a judge and as a ranker at the same time. We propose to train topic-specific relevance classifiers instead: By finetuning monoT5 with independent LoRA weight adaptation on the judgments of a single assessor for a single topic's pool, we align it to that assessor's notion of relevance for the topic. The system rankings obtained through our classifier's relevance judgments achieve a Spearmans' $\rho$ correlation of $>0.95$ with ground truth system rankings. As little as 128 initial human judgments per topic suffice to improve the comparability of models, compared to treating unjudged documents as non-relevant, while achieving more reliability than existing LLM-as-a-judge approaches. Topic-specific relevance classifiers thus are a lightweight and straightforward way to tackle the unjudged document problem, while maintaining human judgments as the gold standard for retrieval evaluation. Code, models, and data are made openly available.
The Viability of Crowdsourcing for RAG Evaluation
Apr 22, 2025



How good are humans at writing and judging responses in retrieval-augmented generation (RAG) scenarios? To answer this question, we investigate the efficacy of crowdsourcing for RAG through two complementary studies: response writing and response utility judgment. We present the Crowd RAG Corpus 2025 (CrowdRAG-25), which consists of 903 human-written and 903 LLM-generated responses for the 301 topics of the TREC RAG'24 track, across the three discourse styles 'bulleted list', 'essay', and 'news'. For a selection of 65 topics, the corpus further contains 47,320 pairwise human judgments and 10,556 pairwise LLM judgments across seven utility dimensions (e.g., coverage and coherence). Our analyses give insights into human writing behavior for RAG and the viability of crowdsourcing for RAG evaluation. Human pairwise judgments provide reliable and cost-effective results compared to LLM-based pairwise or human/LLM-based pointwise judgments, as well as automated comparisons with human-written reference responses. All our data and tools are freely available.
Learning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins
Jul 31, 2024
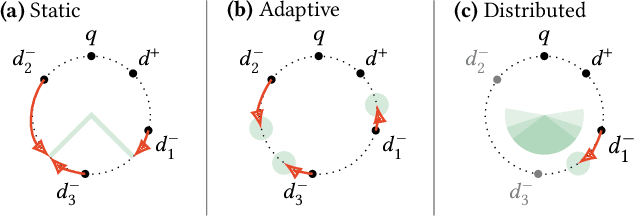

Representation-based retrieval models, so-called biencoders, estimate the relevance of a document to a query by calculating the similarity of their respective embeddings. Current state-of-the-art biencoders are trained using an expensive training regime involving knowledge distillation from a teacher model and batch-sampling. Instead of relying on a teacher model, we contribute a novel parameter-free loss function for self-supervision that exploits the pre-trained language modeling capabilities of the encoder model as a training signal, eliminating the need for batch sampling by performing implicit hard negative mining. We investigate the capabilities of our proposed approach through extensive ablation studies, demonstrating that self-distillation can match the effectiveness of teacher distillation using only 13.5% of the data, while offering a speedup in training time between 3x and 15x compared to parametrized losses. Code and data is made openly available.
Evaluating Generative Ad Hoc Information Retrieval
Nov 08, 2023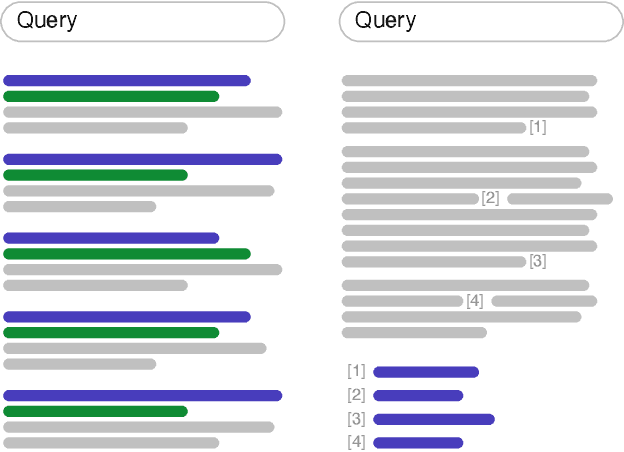

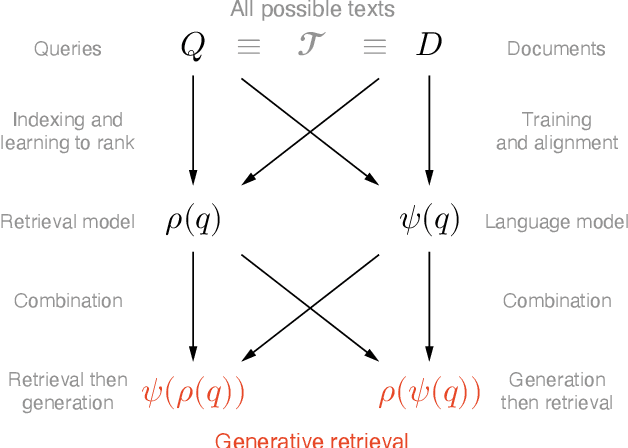
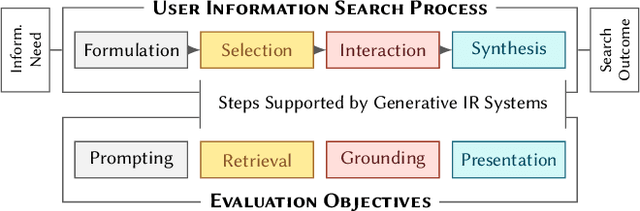
Recent advances in large language models have enabled the development of viable generative information retrieval systems. A generative retrieval system returns a grounded generated text in response to an information need instead of the traditional document ranking. Quantifying the utility of these types of responses is essential for evaluating generative retrieval systems. As the established evaluation methodology for ranking-based ad hoc retrieval may seem unsuitable for generative retrieval, new approaches for reliable, repeatable, and reproducible experimentation are required. In this paper, we survey the relevant information retrieval and natural language processing literature, identify search tasks and system architectures in generative retrieval, develop a corresponding user model, and study its operationalization. This theoretical analysis provides a foundation and new insights for the evaluation of generative ad hoc retrieval systems.
The Archive Query Log: Mining Millions of Search Result Pages of Hundreds of Search Engines from 25 Years of Web Archives
Apr 02, 2023



The Archive Query Log (AQL) is a previously unused, comprehensive query log collected at the Internet Archive over the last 25 years. Its first version includes 356 million queries, 166 million search result pages, and 1.7 billion search results across 550 search providers. Although many query logs have been studied in the literature, the search providers that own them generally do not publish their logs to protect user privacy and vital business data. Of the few query logs publicly available, none combines size, scope, and diversity. The AQL is the first to do so, enabling research on new retrieval models and (diachronic) search engine analyses. Provided in a privacy-preserving manner, it promotes open research as well as more transparency and accountability in the search industry.
SMAuC -- The Scientific Multi-Authorship Corpus
Nov 04, 2022



With an ever-growing number of new publications each day, scientific writing poses an interesting domain for authorship analysis of both single-author and multi-author documents. Unfortunately, most existing corpora lack either material from the science domain or the required metadata. Hence, we present SMAuC, a new metadata-rich corpus designed specifically for authorship analysis in scientific writing. With more than three million publications from various scientific disciplines, SMAuC is the largest openly available corpus for authorship analysis to date. It combines a wide and diverse range of scientific texts from the humanities and natural sciences with rich and curated metadata, including unique and carefully disambiguated author IDs. We hope SMAuC will contribute significantly to advancing the field of authorship analysis in the science domain.
Sparse Pairwise Re-ranking with Pre-trained Transformers
Jul 10, 2022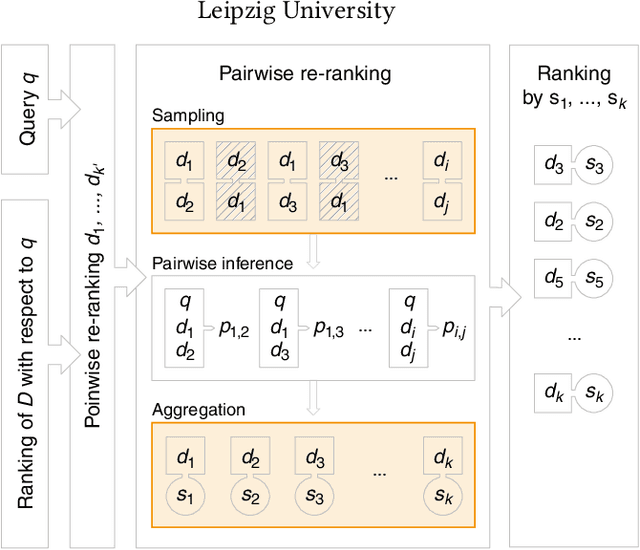
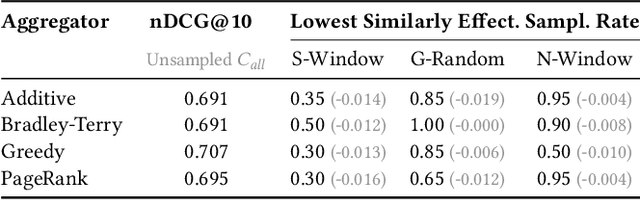

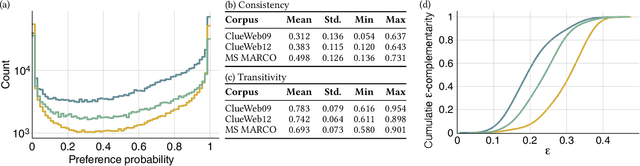
Pairwise re-ranking models predict which of two documents is more relevant to a query and then aggregate a final ranking from such preferences. This is often more effective than pointwise re-ranking models that directly predict a relevance value for each document. However, the high inference overhead of pairwise models limits their practical application: usually, for a set of $k$ documents to be re-ranked, preferences for all $k^2-k$ comparison pairs excluding self-comparisons are aggregated. We investigate whether the efficiency of pairwise re-ranking can be improved by sampling from all pairs. In an exploratory study, we evaluate three sampling methods and five preference aggregation methods. The best combination allows for an order of magnitude fewer comparisons at an acceptable loss of retrieval effectiveness, while competitive effectiveness is already achieved with about one third of the comparisons.
Tracking Discourse Influence in Darknet Forums
Feb 04, 2022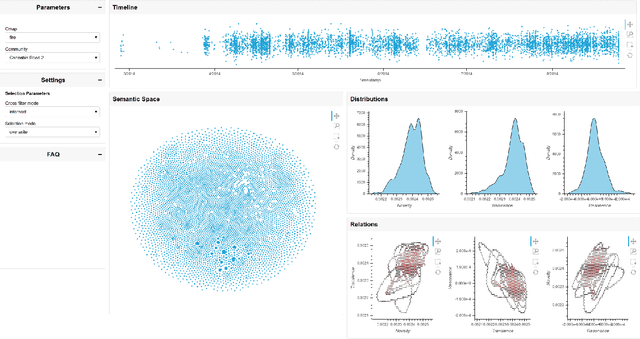
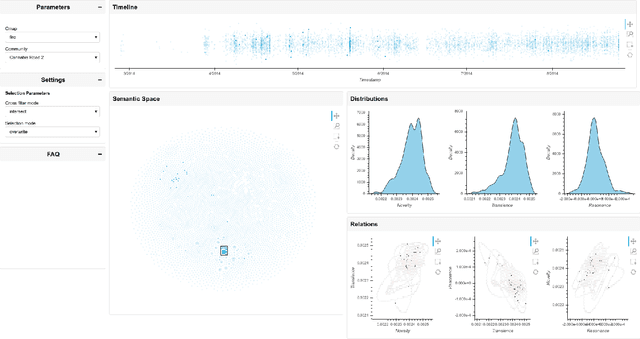

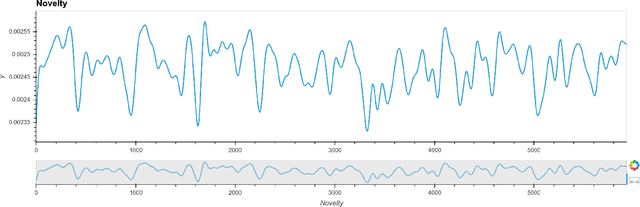
This technical report documents our efforts in addressing the tasks set forth by the 2021 AMoC (Advanced Modelling of Cyber Criminal Careers) Hackathon. Our main contribution is a joint visualisation of semantic and temporal features, generating insight into the supplied data on darknet cybercrime through the aspects of novelty, transience, and resonance, which describe the potential impact a message might have on the overall discourse in darknet communities. All code and data produced by us as part of this hackathon is publicly available.
STEREO: Scientific Text Reuse in Open Access Publications
Dec 22, 2021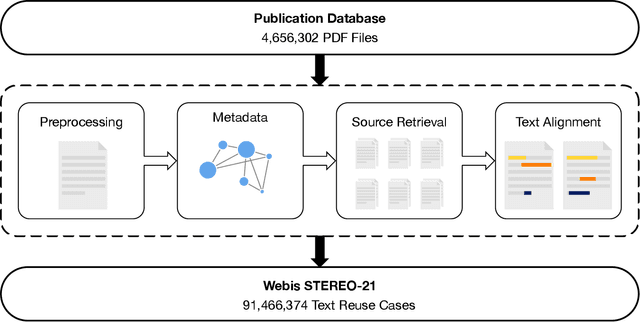
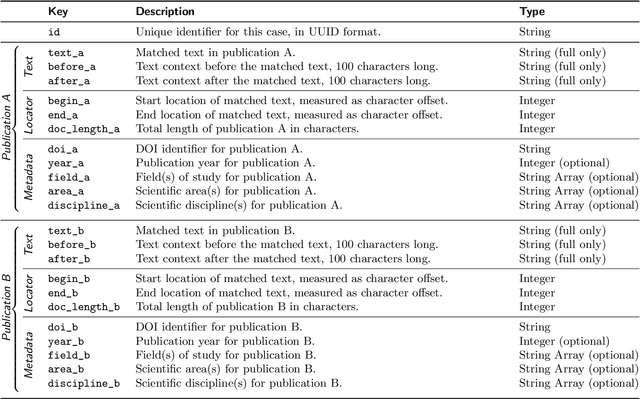

We present the Webis-STEREO-21 dataset, a massive collection of Scientific Text Reuse in Open-access publications. It contains more than 91 million cases of reused text passages found in 4.2 million unique open-access publications. Featuring a high coverage of scientific disciplines and varieties of reuse, as well as comprehensive metadata to contextualize each case, our dataset addresses the most salient shortcomings of previous ones on scientific writing. Webis-STEREO-21 allows for tackling a wide range of research questions from different scientific backgrounds, facilitating both qualitative and quantitative analysis of the phenomenon as well as a first-time grounding on the base rate of text reuse in scientific publications.
The Impact of Main Content Extraction on Near-Duplicate Detection
Nov 21, 2021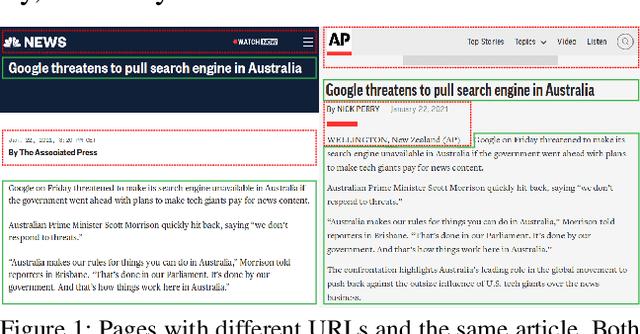

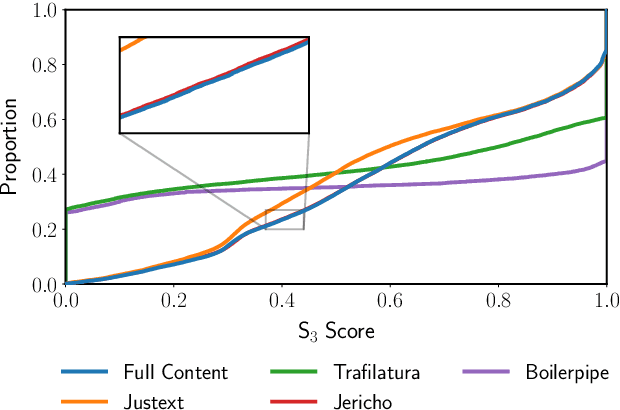
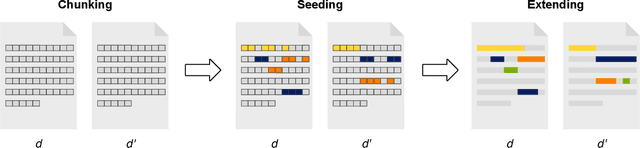
Commercial web search engines employ near-duplicate detection to ensure that users see each relevant result only once, albeit the underlying web crawls typically include (near-)duplicates of many web pages. We revisit the risks and potential of near-duplicates with an information retrieval focus, motivating that current efforts toward an open and independent European web search infrastructure should maintain metadata on duplicate and near-duplicate documents in its index. Near-duplicate detection implemented in an open web search infrastructure should provide a suitable similarity threshold, a difficult choice since identical pages may substantially differ in parts of a page that are irrelevant to searchers (templates, advertisements, etc.). We study this problem by comparing the similarity of pages for five (main) content extraction methods in two studies on the ClueWeb crawls. We find that the full content of pages serves precision-oriented near-duplicate-detection, while main content extraction is more recall-oriented.