 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTL;DR Progress: Multi-faceted Literature Exploration in Text Summarization
Feb 10, 2024



This paper presents TL;DR Progress, a new tool for exploring the literature on neural text summarization. It organizes 514~papers based on a comprehensive annotation scheme for text summarization approaches and enables fine-grained, faceted search. Each paper was manually annotated to capture aspects such as evaluation metrics, quality dimensions, learning paradigms, challenges addressed, datasets, and document domains. In addition, a succinct indicative summary is provided for each paper, consisting of automatically extracted contextual factors, issues, and proposed solutions. The tool is available online at https://www.tldr-progress.de, a demo video at https://youtu.be/uCVRGFvXUj8
Citance-Contextualized Summarization of Scientific Papers
Nov 13, 2023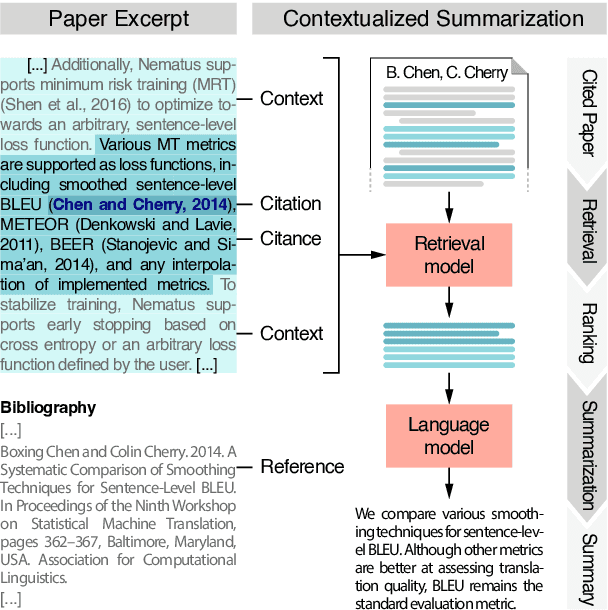
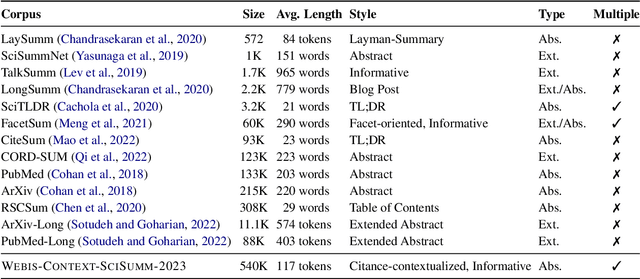

Current approaches to automatic summarization of scientific papers generate informative summaries in the form of abstracts. However, abstracts are not intended to show the relationship between a paper and the references cited in it. We propose a new contextualized summarization approach that can generate an informative summary conditioned on a given sentence containing the citation of a reference (a so-called "citance"). This summary outlines the content of the cited paper relevant to the citation location. Thus, our approach extracts and models the citances of a paper, retrieves relevant passages from cited papers, and generates abstractive summaries tailored to each citance. We evaluate our approach using $\textbf{Webis-Context-SciSumm-2023}$, a new dataset containing 540K~computer science papers and 4.6M~citances therein.
Evaluating Generative Ad Hoc Information Retrieval
Nov 08, 2023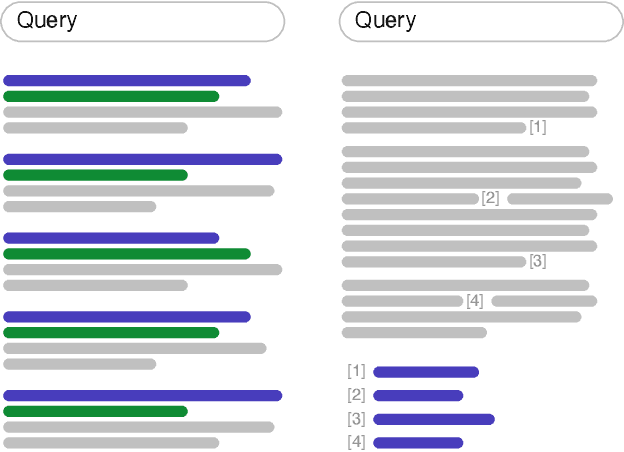

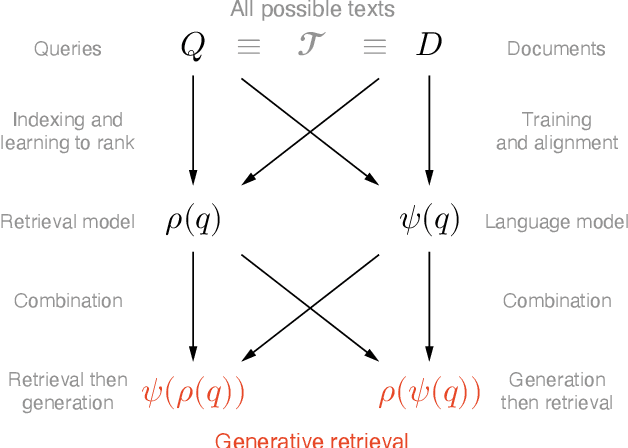
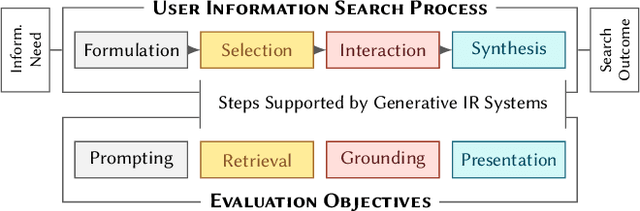
Recent advances in large language models have enabled the development of viable generative information retrieval systems. A generative retrieval system returns a grounded generated text in response to an information need instead of the traditional document ranking. Quantifying the utility of these types of responses is essential for evaluating generative retrieval systems. As the established evaluation methodology for ranking-based ad hoc retrieval may seem unsuitable for generative retrieval, new approaches for reliable, repeatable, and reproducible experimentation are required. In this paper, we survey the relevant information retrieval and natural language processing literature, identify search tasks and system architectures in generative retrieval, develop a corresponding user model, and study its operationalization. This theoretical analysis provides a foundation and new insights for the evaluation of generative ad hoc retrieval systems.
Indicative Summarization of Long Discussions
Nov 03, 2023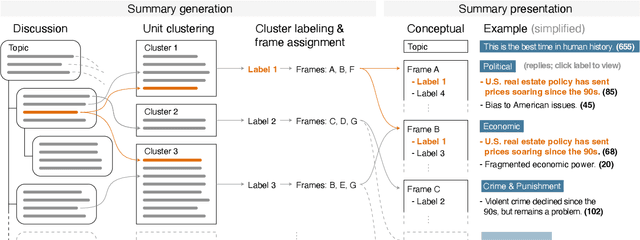
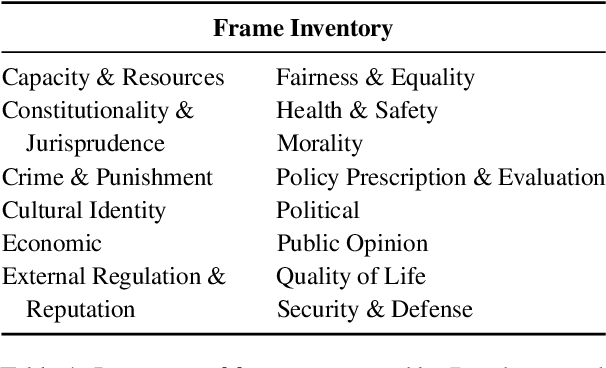
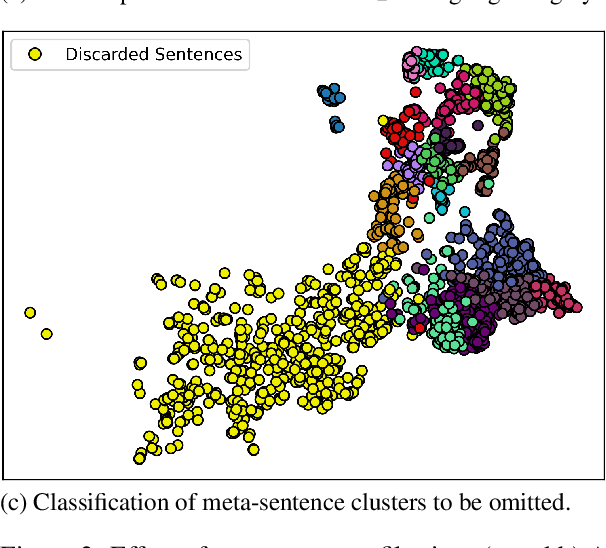

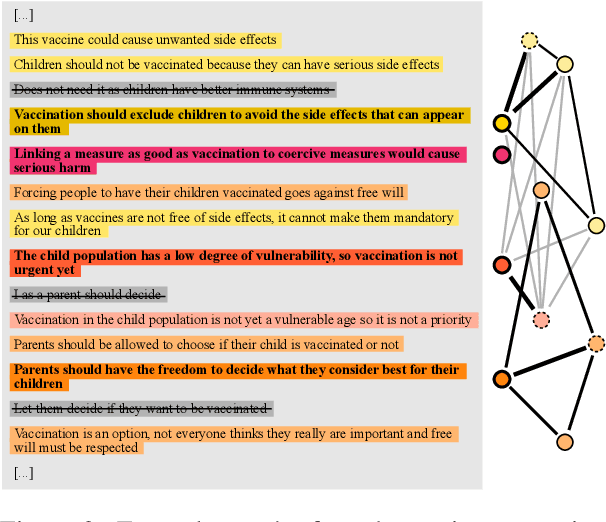
Online forums encourage the exchange and discussion of different stances on many topics. Not only do they provide an opportunity to present one's own arguments, but may also gather a broad cross-section of others' arguments. However, the resulting long discussions are difficult to overview. This paper presents a novel unsupervised approach using large language models (LLMs) to generating indicative summaries for long discussions that basically serve as tables of contents. Our approach first clusters argument sentences, generates cluster labels as abstractive summaries, and classifies the generated cluster labels into argumentation frames resulting in a two-level summary. Based on an extensively optimized prompt engineering approach, we evaluate 19~LLMs for generative cluster labeling and frame classification. To evaluate the usefulness of our indicative summaries, we conduct a purpose-driven user study via a new visual interface called Discussion Explorer: It shows that our proposed indicative summaries serve as a convenient navigation tool to explore long discussions.
Modeling Appropriate Language in Argumentation
May 24, 2023



Online discussion moderators must make ad-hoc decisions about whether the contributions of discussion participants are appropriate or should be removed to maintain civility. Existing research on offensive language and the resulting tools cover only one aspect among many involved in such decisions. The question of what is considered appropriate in a controversial discussion has not yet been systematically addressed. In this paper, we operationalize appropriate language in argumentation for the first time. In particular, we model appropriateness through the absence of flaws, grounded in research on argument quality assessment, especially in aspects from rhetoric. From these, we derive a new taxonomy of 14 dimensions that determine inappropriate language in online discussions. Building on three argument quality corpora, we then create a corpus of 2191 arguments annotated for the 14 dimensions. Empirical analyses support that the taxonomy covers the concept of appropriateness comprehensively, showing several plausible correlations with argument quality dimensions. Moreover, results of baseline approaches to assessing appropriateness suggest that all dimensions can be modeled computationally on the corpus.
Summary Workbench: Unifying Application and Evaluation of Text Summarization Models
Oct 18, 2022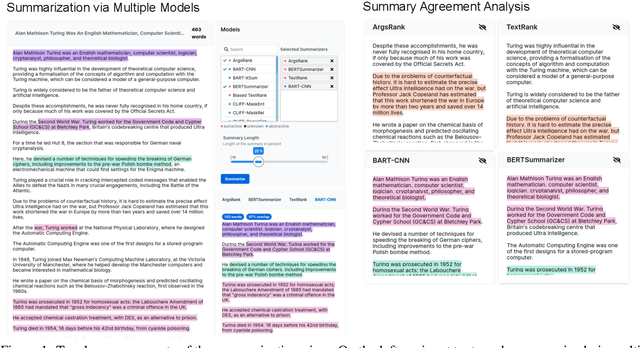
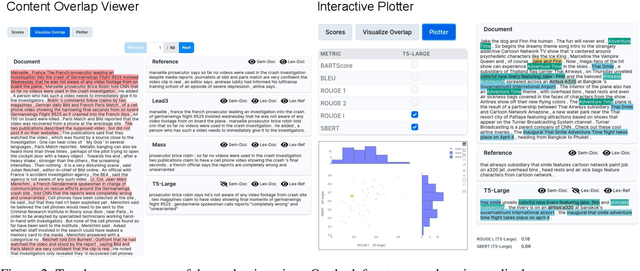

This paper presents Summary Workbench, a new tool for developing and evaluating text summarization models. New models and evaluation measures can be easily integrated as Docker-based plugins, allowing to examine the quality of their summaries against any input and to evaluate them using various evaluation measures. Visual analyses combining multiple measures provide insights into the models' strengths and weaknesses. The tool is hosted at \url{https://tldr.demo.webis.de} and also supports local deployment for private resources.
Key Point Analysis via Contrastive Learning and Extractive Argument Summarization
Sep 30, 2021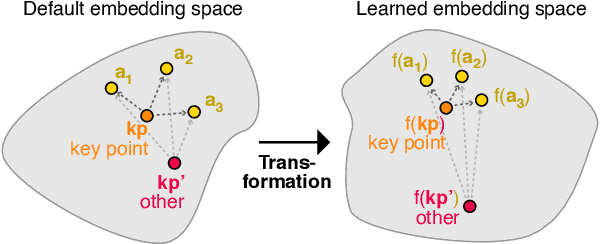


Key point analysis is the task of extracting a set of concise and high-level statements from a given collection of arguments, representing the gist of these arguments. This paper presents our proposed approach to the Key Point Analysis shared task, collocated with the 8th Workshop on Argument Mining. The approach integrates two complementary components. One component employs contrastive learning via a siamese neural network for matching arguments to key points; the other is a graph-based extractive summarization model for generating key points. In both automatic and manual evaluation, our approach was ranked best among all submissions to the shared task.
Summary Explorer: Visualizing the State of the Art in Text Summarization
Aug 04, 2021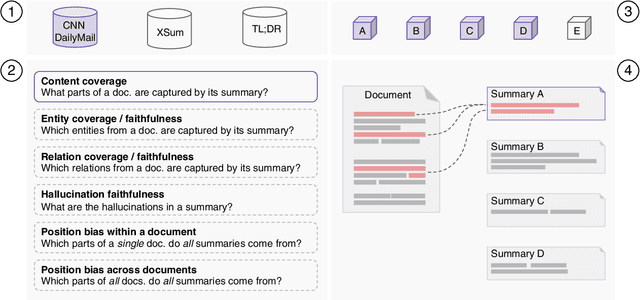
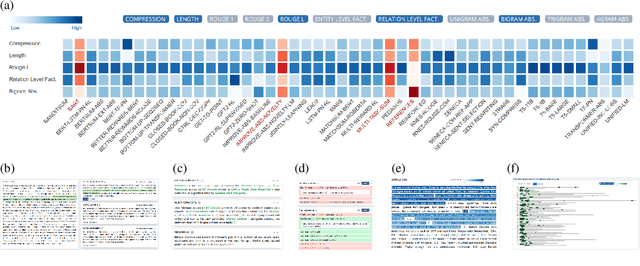

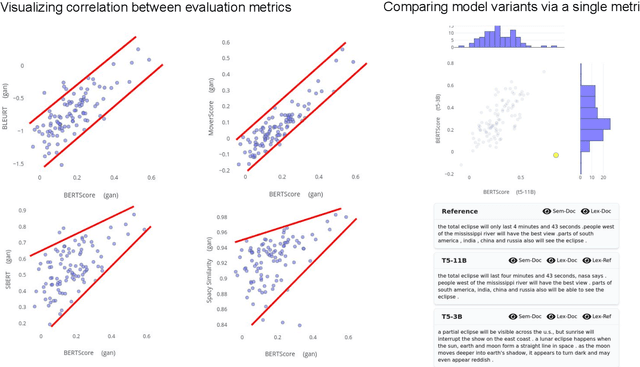
This paper introduces Summary Explorer, a new tool to support the manual inspection of text summarization systems by compiling the outputs of 55~state-of-the-art single document summarization approaches on three benchmark datasets, and visually exploring them during a qualitative assessment. The underlying design of the tool considers three well-known summary quality criteria (coverage, faithfulness, and position bias), encapsulated in a guided assessment based on tailored visualizations. The tool complements existing approaches for locally debugging summarization models and improves upon them. The tool is available at https://tldr.webis.de/
Generating Informative Conclusions for Argumentative Texts
Jun 02, 2021
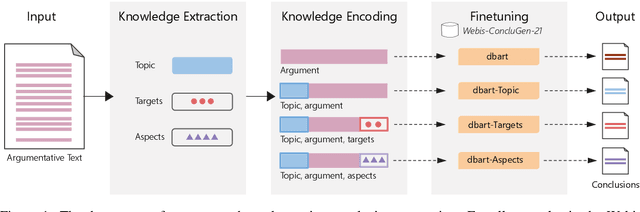

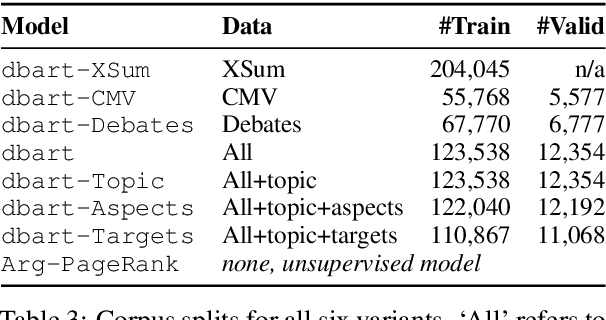
The purpose of an argumentative text is to support a certain conclusion. Yet, they are often omitted, expecting readers to infer them rather. While appropriate when reading an individual text, this rhetorical device limits accessibility when browsing many texts (e.g., on a search engine or on social media). In these scenarios, an explicit conclusion makes for a good candidate summary of an argumentative text. This is especially true if the conclusion is informative, emphasizing specific concepts from the text. With this paper we introduce the task of generating informative conclusions: First, Webis-ConcluGen-21 is compiled, a large-scale corpus of 136,996 samples of argumentative texts and their conclusions. Second, two paradigms for conclusion generation are investigated; one extractive, the other abstractive in nature. The latter exploits argumentative knowledge that augment the data via control codes and finetuning the BART model on several subsets of the corpus. Third, insights are provided into the suitability of our corpus for the task, the differences between the two generation paradigms, the trade-off between informativeness and conciseness, and the impact of encoding argumentative knowledge. The corpus, code, and the trained models are publicly available.
Argument Undermining: Counter-Argument Generation by Attacking Weak Premises
May 31, 2021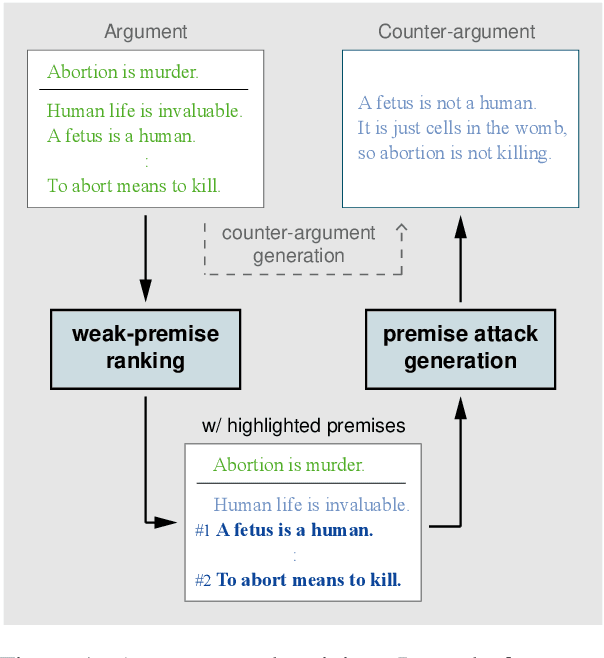
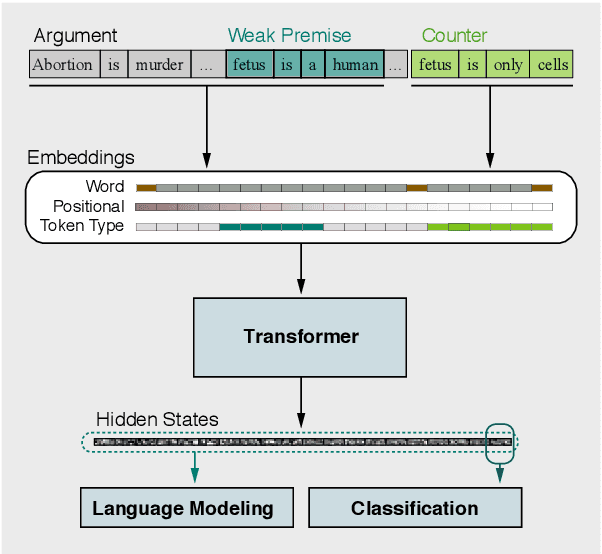


Text generation has received a lot of attention in computational argumentation research as of recent. A particularly challenging task is the generation of counter-arguments. So far, approaches primarily focus on rebutting a given conclusion, yet other ways to counter an argument exist. In this work, we go beyond previous research by exploring argument undermining, that is, countering an argument by attacking one of its premises. We hypothesize that identifying the argument's weak premises is key to effective countering. Accordingly, we propose a pipeline approach that first assesses the premises' strength and then generates a counter-argument targeting the weak ones. On the one hand, both manual and automatic evaluation proves the importance of identifying weak premises in counter-argument generation. On the other hand, when considering correctness and content richness, human annotators favored our approach over state-of-the-art counter-argument generation.