 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGUS: Seeing the Influence of Narrative Features on Persuasion in Argumentative Texts
Feb 27, 2026Can narratives make arguments more persuasive? And to this end, which narrative features matter most? Although stories are often seen as powerful tools for persuasion, their specific role in online, unstructured argumentation remains underexplored. To address this gap, we present ARGUS, a framework for studying the impact of narration on persuasion in argumentative discourse. ARGUS introduces a new ChangeMyView corpus annotated for story presence and six key narrative features, integrating insights from two established theoretical frameworks that capture both textual narrative features and their effects on recipients. Leveraging both encoder-based classifiers and zero-shot large language models (LLMs), ARGUS identifies stories and narrative features and applies them at scale to examine how different narrative dimensions influence persuasion success in online argumentation.
Toward Reasonable Parrots: Why Large Language Models Should Argue with Us by Design
May 08, 2025

In this position paper, we advocate for the development of conversational technology that is inherently designed to support and facilitate argumentative processes. We argue that, at present, large language models (LLMs) are inadequate for this purpose, and we propose an ideal technology design aimed at enhancing argumentative skills. This involves re-framing LLMs as tools to exercise our critical thinking rather than replacing them. We introduce the concept of 'reasonable parrots' that embody the fundamental principles of relevance, responsibility, and freedom, and that interact through argumentative dialogical moves. These principles and moves arise out of millennia of work in argumentation theory and should serve as the starting point for LLM-based technology that incorporates basic principles of argumentation.
Language is Scary when Over-Analyzed: Unpacking Implied Misogynistic Reasoning with Argumentation Theory-Driven Prompts
Sep 04, 2024



We propose misogyny detection as an Argumentative Reasoning task and we investigate the capacity of large language models (LLMs) to understand the implicit reasoning used to convey misogyny in both Italian and English. The central aim is to generate the missing reasoning link between a message and the implied meanings encoding the misogyny. Our study uses argumentation theory as a foundation to form a collection of prompts in both zero-shot and few-shot settings. These prompts integrate different techniques, including chain-of-thought reasoning and augmented knowledge. Our findings show that LLMs fall short on reasoning capabilities about misogynistic comments and that they mostly rely on their implicit knowledge derived from internalized common stereotypes about women to generate implied assumptions, rather than on inductive reasoning.
TL;DR Progress: Multi-faceted Literature Exploration in Text Summarization
Feb 10, 2024



This paper presents TL;DR Progress, a new tool for exploring the literature on neural text summarization. It organizes 514~papers based on a comprehensive annotation scheme for text summarization approaches and enables fine-grained, faceted search. Each paper was manually annotated to capture aspects such as evaluation metrics, quality dimensions, learning paradigms, challenges addressed, datasets, and document domains. In addition, a succinct indicative summary is provided for each paper, consisting of automatically extracted contextual factors, issues, and proposed solutions. The tool is available online at https://www.tldr-progress.de, a demo video at https://youtu.be/uCVRGFvXUj8
Citance-Contextualized Summarization of Scientific Papers
Nov 13, 2023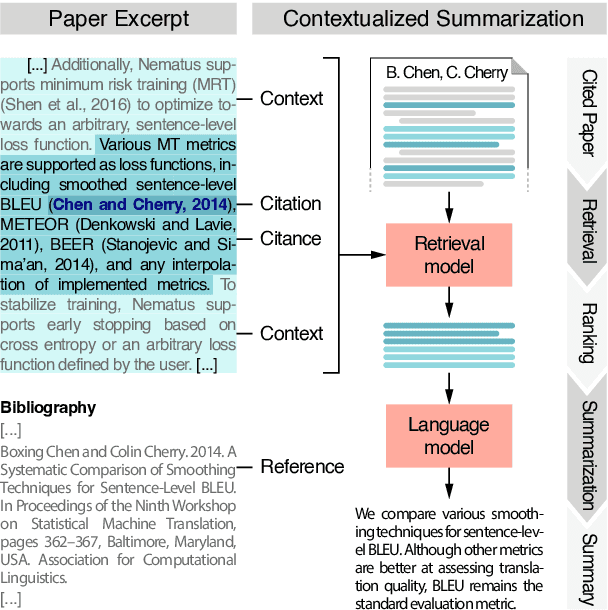
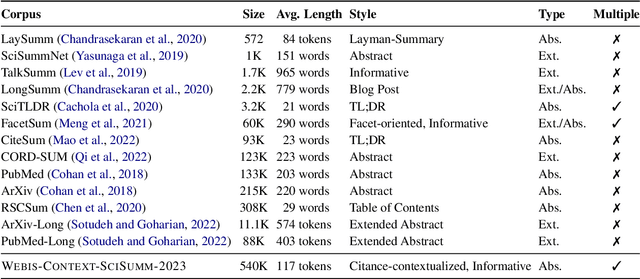

Current approaches to automatic summarization of scientific papers generate informative summaries in the form of abstracts. However, abstracts are not intended to show the relationship between a paper and the references cited in it. We propose a new contextualized summarization approach that can generate an informative summary conditioned on a given sentence containing the citation of a reference (a so-called "citance"). This summary outlines the content of the cited paper relevant to the citation location. Thus, our approach extracts and models the citances of a paper, retrieves relevant passages from cited papers, and generates abstractive summaries tailored to each citance. We evaluate our approach using $\textbf{Webis-Context-SciSumm-2023}$, a new dataset containing 540K~computer science papers and 4.6M~citances therein.
Indicative Summarization of Long Discussions
Nov 03, 2023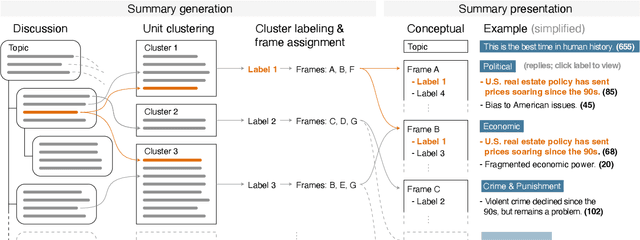
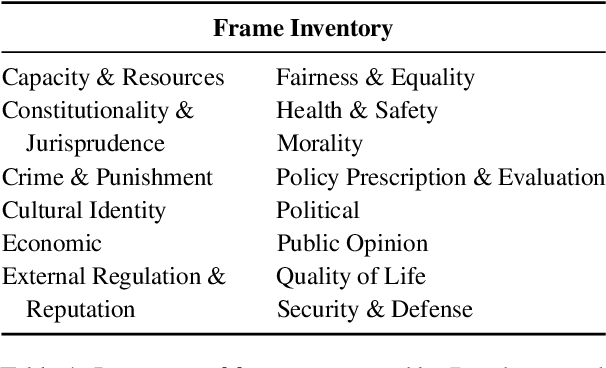

Online forums encourage the exchange and discussion of different stances on many topics. Not only do they provide an opportunity to present one's own arguments, but may also gather a broad cross-section of others' arguments. However, the resulting long discussions are difficult to overview. This paper presents a novel unsupervised approach using large language models (LLMs) to generating indicative summaries for long discussions that basically serve as tables of contents. Our approach first clusters argument sentences, generates cluster labels as abstractive summaries, and classifies the generated cluster labels into argumentation frames resulting in a two-level summary. Based on an extensively optimized prompt engineering approach, we evaluate 19~LLMs for generative cluster labeling and frame classification. To evaluate the usefulness of our indicative summaries, we conduct a purpose-driven user study via a new visual interface called Discussion Explorer: It shows that our proposed indicative summaries serve as a convenient navigation tool to explore long discussions.
Differential Bias: On the Perceptibility of Stance Imbalance in Argumentation
Oct 13, 2022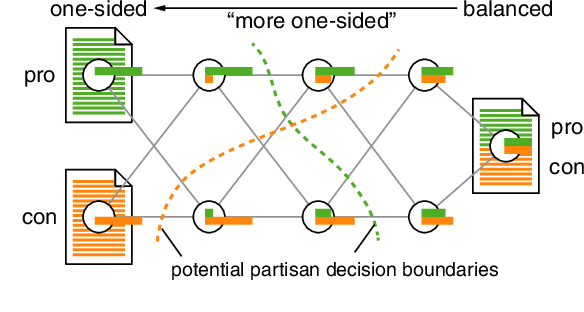
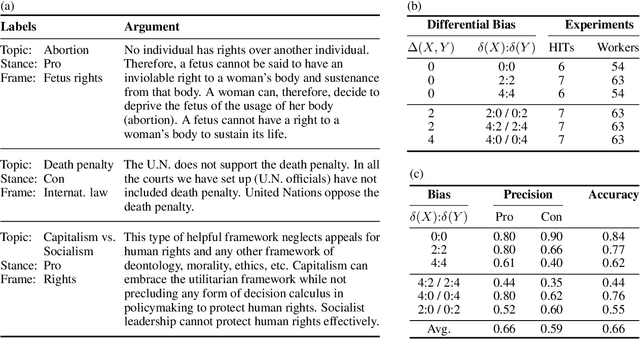
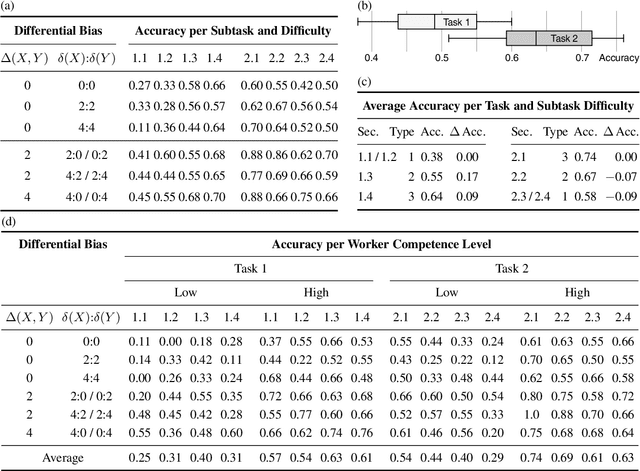
Most research on natural language processing treats bias as an absolute concept: Based on a (probably complex) algorithmic analysis, a sentence, an article, or a text is classified as biased or not. Given the fact that for humans the question of whether a text is biased can be difficult to answer or is answered contradictory, we ask whether an "absolute bias classification" is a promising goal at all. We see the problem not in the complexity of interpreting language phenomena but in the diversity of sociocultural backgrounds of the readers, which cannot be handled uniformly: To decide whether a text has crossed the proverbial line between non-biased and biased is subjective. By asking "Is text X more [less, equally] biased than text Y?" we propose to analyze a simpler problem, which, by its construction, is rather independent of standpoints, views, or sociocultural aspects. In such a model, bias becomes a preference relation that induces a partial ordering from least biased to most biased texts without requiring a decision on where to draw the line. A prerequisite for this kind of bias model is the ability of humans to perceive relative bias differences in the first place. In our research, we selected a specific type of bias in argumentation, the stance bias, and designed a crowdsourcing study showing that differences in stance bias are perceptible when (light) support is provided through training or visual aid.
Controlled Neural Sentence-Level Reframing of News Articles
Sep 10, 2021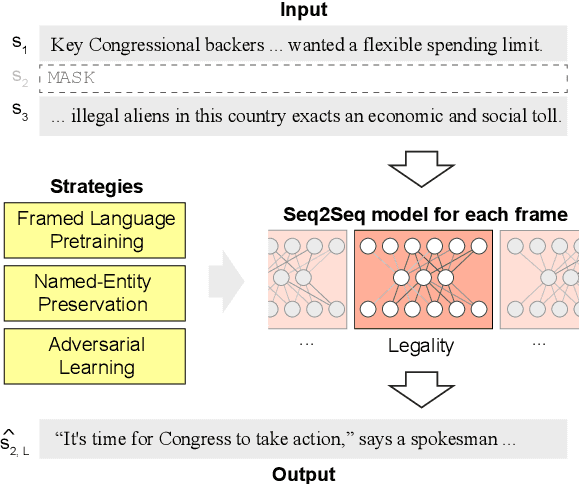

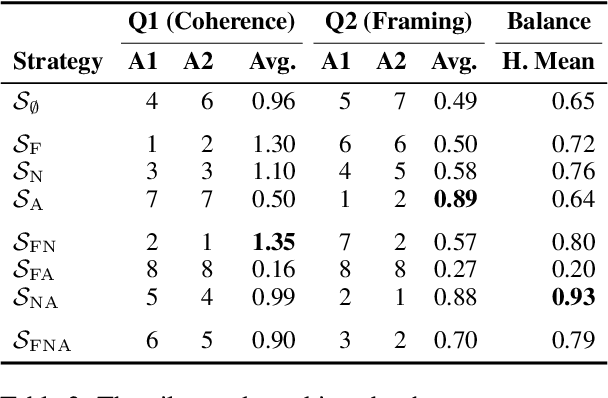
Framing a news article means to portray the reported event from a specific perspective, e.g., from an economic or a health perspective. Reframing means to change this perspective. Depending on the audience or the submessage, reframing can become necessary to achieve the desired effect on the readers. Reframing is related to adapting style and sentiment, which can be tackled with neural text generation techniques. However, it is more challenging since changing a frame requires rewriting entire sentences rather than single phrases. In this paper, we study how to computationally reframe sentences in news articles while maintaining their coherence to the context. We treat reframing as a sentence-level fill-in-the-blank task for which we train neural models on an existing media frame corpus. To guide the training, we propose three strategies: framed-language pretraining, named-entity preservation, and adversarial learning. We evaluate respective models automatically and manually for topic consistency, coherence, and successful reframing. Our results indicate that generating properly-framed text works well but with tradeoffs.
Summary Explorer: Visualizing the State of the Art in Text Summarization
Aug 04, 2021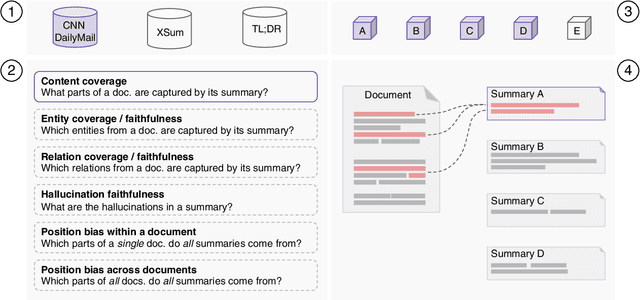
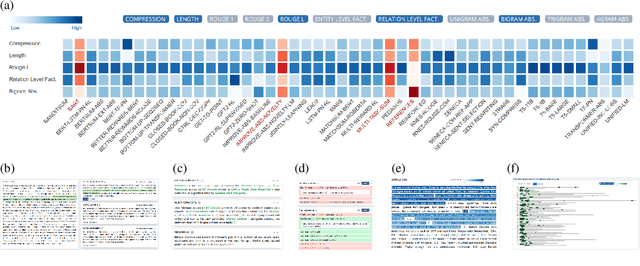

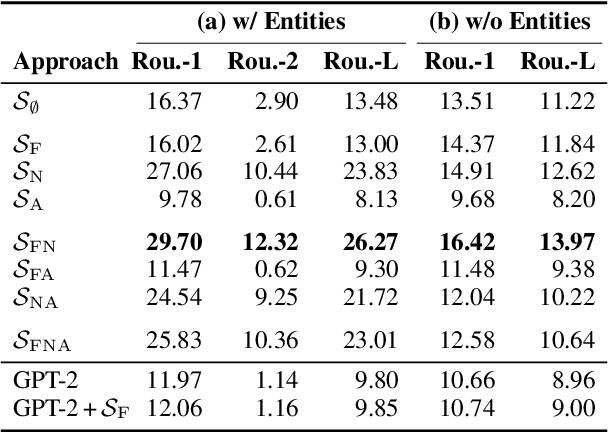
This paper introduces Summary Explorer, a new tool to support the manual inspection of text summarization systems by compiling the outputs of 55~state-of-the-art single document summarization approaches on three benchmark datasets, and visually exploring them during a qualitative assessment. The underlying design of the tool considers three well-known summary quality criteria (coverage, faithfulness, and position bias), encapsulated in a guided assessment based on tailored visualizations. The tool complements existing approaches for locally debugging summarization models and improves upon them. The tool is available at https://tldr.webis.de/
Generating Informative Conclusions for Argumentative Texts
Jun 02, 2021
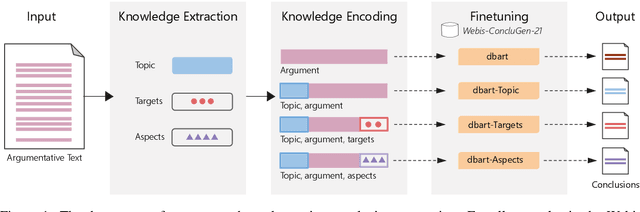

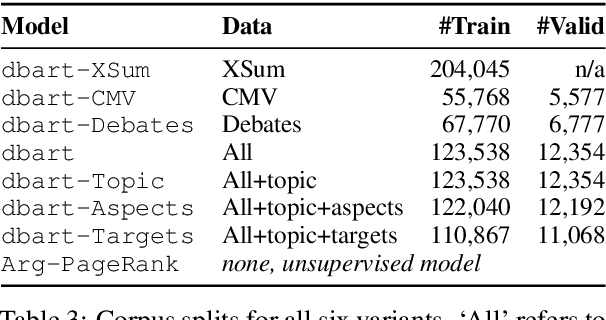
The purpose of an argumentative text is to support a certain conclusion. Yet, they are often omitted, expecting readers to infer them rather. While appropriate when reading an individual text, this rhetorical device limits accessibility when browsing many texts (e.g., on a search engine or on social media). In these scenarios, an explicit conclusion makes for a good candidate summary of an argumentative text. This is especially true if the conclusion is informative, emphasizing specific concepts from the text. With this paper we introduce the task of generating informative conclusions: First, Webis-ConcluGen-21 is compiled, a large-scale corpus of 136,996 samples of argumentative texts and their conclusions. Second, two paradigms for conclusion generation are investigated; one extractive, the other abstractive in nature. The latter exploits argumentative knowledge that augment the data via control codes and finetuning the BART model on several subsets of the corpus. Third, insights are provided into the suitability of our corpus for the task, the differences between the two generation paradigms, the trade-off between informativeness and conciseness, and the impact of encoding argumentative knowledge. The corpus, code, and the trained models are publicly available.