 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled Neural Sentence-Level Reframing of News Articles
Sep 10, 2021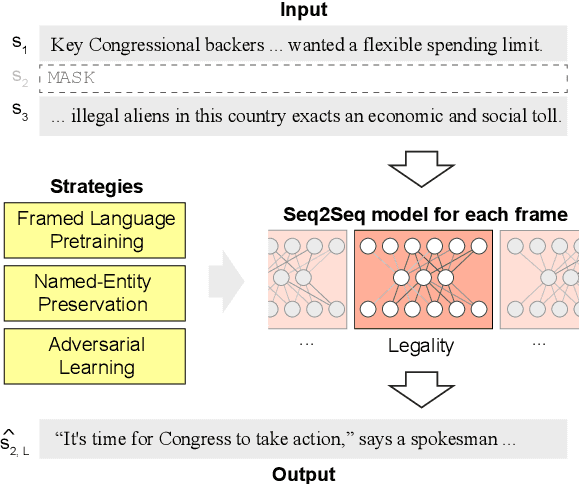

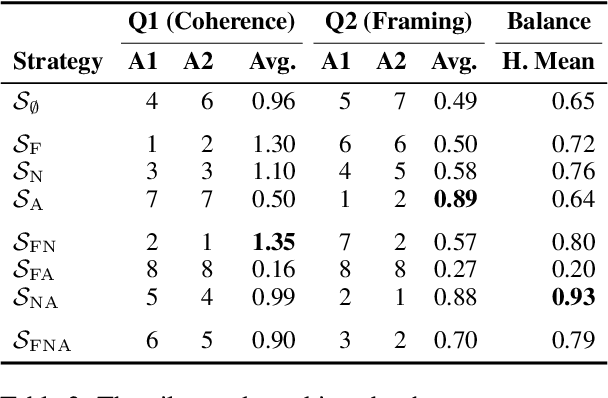
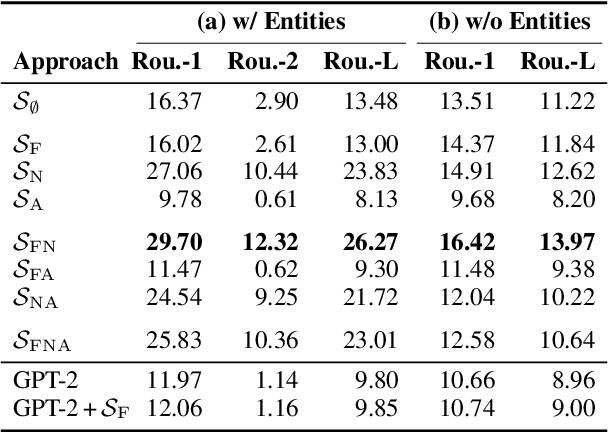
Framing a news article means to portray the reported event from a specific perspective, e.g., from an economic or a health perspective. Reframing means to change this perspective. Depending on the audience or the submessage, reframing can become necessary to achieve the desired effect on the readers. Reframing is related to adapting style and sentiment, which can be tackled with neural text generation techniques. However, it is more challenging since changing a frame requires rewriting entire sentences rather than single phrases. In this paper, we study how to computationally reframe sentences in news articles while maintaining their coherence to the context. We treat reframing as a sentence-level fill-in-the-blank task for which we train neural models on an existing media frame corpus. To guide the training, we propose three strategies: framed-language pretraining, named-entity preservation, and adversarial learning. We evaluate respective models automatically and manually for topic consistency, coherence, and successful reframing. Our results indicate that generating properly-framed text works well but with tradeoffs.
Belief-based Generation of Argumentative Claims
Jan 26, 2021

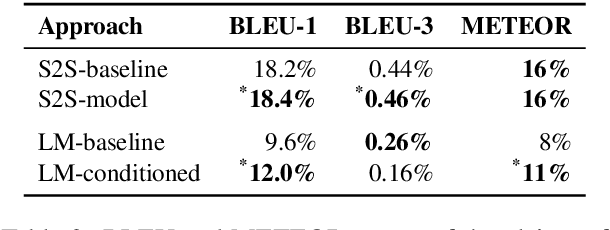
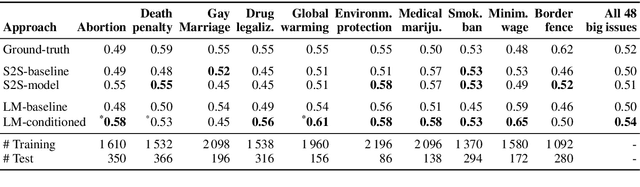
When engaging in argumentative discourse, skilled human debaters tailor claims to the beliefs of the audience, to construct effective arguments. Recently, the field of computational argumentation witnessed extensive effort to address the automatic generation of arguments. However, existing approaches do not perform any audience-specific adaptation. In this work, we aim to bridge this gap by studying the task of belief-based claim generation: Given a controversial topic and a set of beliefs, generate an argumentative claim tailored to the beliefs. To tackle this task, we model the people's prior beliefs through their stances on controversial topics and extend state-of-the-art text generation models to generate claims conditioned on the beliefs. Our automatic evaluation confirms the ability of our approach to adapt claims to a set of given beliefs. In a manual study, we additionally evaluate the generated claims in terms of informativeness and their likelihood to be uttered by someone with a respective belief. Our results reveal the limitations of modeling users' beliefs based on their stances, but demonstrate the potential of encoding beliefs into argumentative texts, laying the ground for future exploration of audience reach.
Analyzing Political Bias and Unfairness in News Articles at Different Levels of Granularity
Oct 20, 2020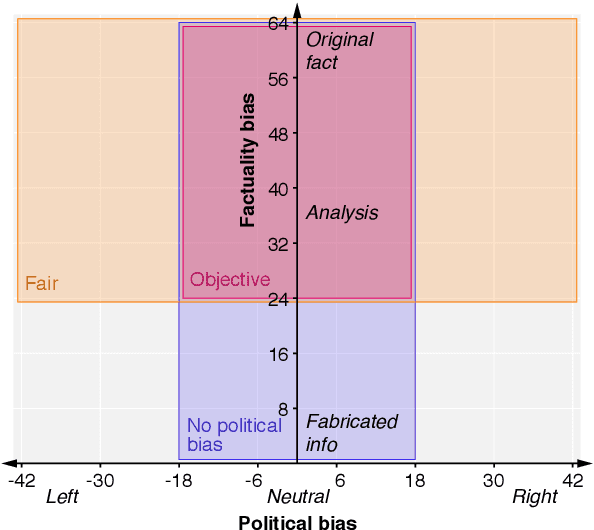
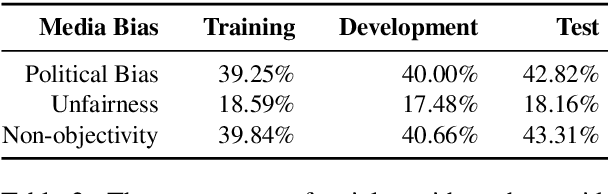

Media organizations bear great reponsibility because of their considerable influence on shaping beliefs and positions of our society. Any form of media can contain overly biased content, e.g., by reporting on political events in a selective or incomplete manner. A relevant question hence is whether and how such form of imbalanced news coverage can be exposed. The research presented in this paper addresses not only the automatic detection of bias but goes one step further in that it explores how political bias and unfairness are manifested linguistically. In this regard we utilize a new corpus of 6964 news articles with labels derived from adfontesmedia.com and develop a neural model for bias assessment. By analyzing this model on article excerpts, we find insightful bias patterns at different levels of text granularity, from single words to the whole article discourse.
Detecting Media Bias in News Articles using Gaussian Bias Distributions
Oct 20, 2020


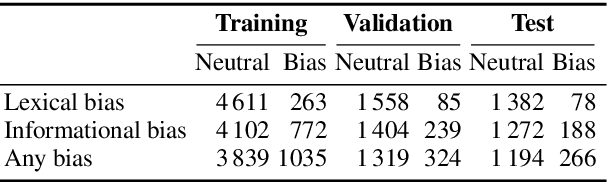
Media plays an important role in shaping public opinion. Biased media can influence people in undesirable directions and hence should be unmasked as such. We observe that featurebased and neural text classification approaches which rely only on the distribution of low-level lexical information fail to detect media bias. This weakness becomes most noticeable for articles on new events, where words appear in new contexts and hence their "bias predictiveness" is unclear. In this paper, we therefore study how second-order information about biased statements in an article helps to improve detection effectiveness. In particular, we utilize the probability distributions of the frequency, positions, and sequential order of lexical and informational sentence-level bias in a Gaussian Mixture Model. On an existing media bias dataset, we find that the frequency and positions of biased statements strongly impact article-level bias, whereas their exact sequential order is secondary. Using a standard model for sentence-level bias detection, we provide empirical evidence that article-level bias detectors that use second-order information clearly outperform those without.
Abstractive Snippet Generation
Mar 15, 2020



An abstractive snippet is an originally created piece of text to summarize a web page on a search engine results page. Compared to the conventional extractive snippets, which are generated by extracting phrases and sentences verbatim from a web page, abstractive snippets circumvent copyright issues; even more interesting is the fact that they open the door for personalization. Abstractive snippets have been evaluated as equally powerful in terms of user acceptance and expressiveness---but the key question remains: Can abstractive snippets be automatically generated with sufficient quality? This paper introduces a new approach to abstractive snippet generation: We identify the first two large-scale sources for distant supervision, namely anchor contexts and web directories. By mining the entire ClueWeb09 and ClueWeb12 for anchor contexts and by utilizing the DMOZ Open Directory Project, we compile the Webis Abstractive Snippet Corpus 2020, comprising more than 3.5 million triples of the form $\langle$query, snippet, document$\rangle$ as training examples, where the snippet is either an anchor context or a web directory description in lieu of a genuine query-biased abstractive snippet of the web document. We propose a bidirectional abstractive snippet generation model and assess the quality of both our corpus and the generated abstractive snippets with standard measures, crowdsourcing, and in comparison to the state of the art. The evaluation shows that our novel data sources along with the proposed model allow for producing usable query-biased abstractive snippets while minimizing text reuse.
UTCNN: a Deep Learning Model of Stance Classificationon on Social Media Text
Nov 11, 2016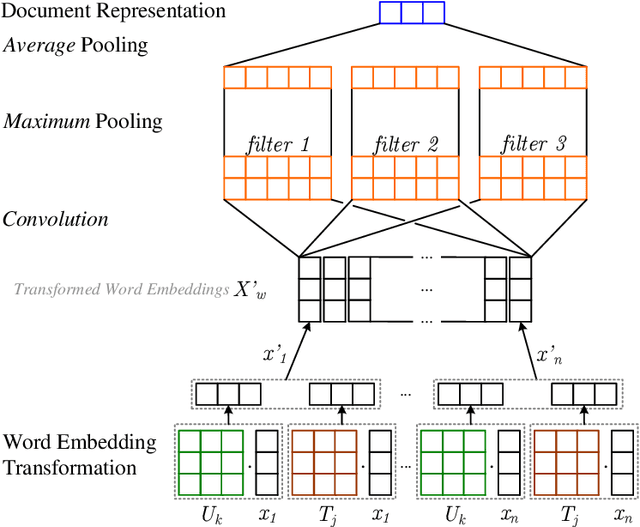



Most neural network models for document classification on social media focus on text infor-mation to the neglect of other information on these platforms. In this paper, we classify post stance on social media channels and develop UTCNN, a neural network model that incorporates user tastes, topic tastes, and user comments on posts. UTCNN not only works on social media texts, but also analyzes texts in forums and message boards. Experiments performed on Chinese Facebook data and English online debate forum data show that UTCNN achieves a 0.755 macro-average f-score for supportive, neutral, and unsupportive stance classes on Facebook data, which is significantly better than models in which either user, topic, or comment information is withheld. This model design greatly mitigates the lack of data for the minor class without the use of oversampling. In addition, UTCNN yields a 0.842 accuracy on English online debate forum data, which also significantly outperforms results from previous work as well as other deep learning models, showing that UTCNN performs well regardless of language or platform.