 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgInstruct: Specialized Instruction Fine-Tuning for Computational Argumentation
May 28, 2025Training large language models (LLMs) to follow instructions has significantly enhanced their ability to tackle unseen tasks. However, despite their strong generalization capabilities, instruction-following LLMs encounter difficulties when dealing with tasks that require domain knowledge. This work introduces a specialized instruction fine-tuning for the domain of computational argumentation (CA). The goal is to enable an LLM to effectively tackle any unseen CA tasks while preserving its generalization capabilities. Reviewing existing CA research, we crafted natural language instructions for 105 CA tasks to this end. On this basis, we developed a CA-specific benchmark for LLMs that allows for a comprehensive evaluation of LLMs' capabilities in solving various CA tasks. We synthesized 52k CA-related instructions, adapting the self-instruct process to train a CA-specialized instruction-following LLM. Our experiments suggest that CA-specialized instruction fine-tuning significantly enhances the LLM on both seen and unseen CA tasks. At the same time, performance on the general NLP tasks of the SuperNI benchmark remains stable.
Toward Reasonable Parrots: Why Large Language Models Should Argue with Us by Design
May 08, 2025

In this position paper, we advocate for the development of conversational technology that is inherently designed to support and facilitate argumentative processes. We argue that, at present, large language models (LLMs) are inadequate for this purpose, and we propose an ideal technology design aimed at enhancing argumentative skills. This involves re-framing LLMs as tools to exercise our critical thinking rather than replacing them. We introduce the concept of 'reasonable parrots' that embody the fundamental principles of relevance, responsibility, and freedom, and that interact through argumentative dialogical moves. These principles and moves arise out of millennia of work in argumentation theory and should serve as the starting point for LLM-based technology that incorporates basic principles of argumentation.
Investigating Co-Constructive Behavior of Large Language Models in Explanation Dialogues
Apr 25, 2025The ability to generate explanations that are understood by explainees is the quintessence of explainable artificial intelligence. Since understanding depends on the explainee's background and needs, recent research has focused on co-constructive explanation dialogues, where the explainer continuously monitors the explainee's understanding and adapts explanations dynamically. We investigate the ability of large language models (LLMs) to engage as explainers in co-constructive explanation dialogues. In particular, we present a user study in which explainees interact with LLMs, of which some have been instructed to explain a predefined topic co-constructively. We evaluate the explainees' understanding before and after the dialogue, as well as their perception of the LLMs' co-constructive behavior. Our results indicate that current LLMs show some co-constructive behaviors, such as asking verification questions, that foster the explainees' engagement and can improve understanding of a topic. However, their ability to effectively monitor the current understanding and scaffold the explanations accordingly remains limited.
Towards a Perspectivist Turn in Argument Quality Assessment
Feb 20, 2025The assessment of argument quality depends on well-established logical, rhetorical, and dialectical properties that are unavoidably subjective: multiple valid assessments may exist, there is no unequivocal ground truth. This aligns with recent paths in machine learning, which embrace the co-existence of different perspectives. However, this potential remains largely unexplored in NLP research on argument quality. One crucial reason seems to be the yet unexplored availability of suitable datasets. We fill this gap by conducting a systematic review of argument quality datasets. We assign them to a multi-layered categorization targeting two aspects: (a) What has been annotated: we collect the quality dimensions covered in datasets and consolidate them in an overarching taxonomy, increasing dataset comparability and interoperability. (b) Who annotated: we survey what information is given about annotators, enabling perspectivist research and grounding our recommendations for future actions. To this end, we discuss datasets suitable for developing perspectivist models (i.e., those containing individual, non-aggregated annotations), and we showcase the importance of a controlled selection of annotators in a pilot study.
Adaptive Prompting: Ad-hoc Prompt Composition for Social Bias Detection
Feb 10, 2025Recent advances on instruction fine-tuning have led to the development of various prompting techniques for large language models, such as explicit reasoning steps. However, the success of techniques depends on various parameters, such as the task, language model, and context provided. Finding an effective prompt is, therefore, often a trial-and-error process. Most existing approaches to automatic prompting aim to optimize individual techniques instead of compositions of techniques and their dependence on the input. To fill this gap, we propose an adaptive prompting approach that predicts the optimal prompt composition ad-hoc for a given input. We apply our approach to social bias detection, a highly context-dependent task that requires semantic understanding. We evaluate it with three large language models on three datasets, comparing compositions to individual techniques and other baselines. The results underline the importance of finding an effective prompt composition. Our approach robustly ensures high detection performance, and is best in several settings. Moreover, first experiments on other tasks support its generalizability.
Disentangling Dialect from Social Bias via Multitask Learning to Improve Fairness
Jun 14, 2024Dialects introduce syntactic and lexical variations in language that occur in regional or social groups. Most NLP methods are not sensitive to such variations. This may lead to unfair behavior of the methods, conveying negative bias towards dialect speakers. While previous work has studied dialect-related fairness for aspects like hate speech, other aspects of biased language, such as lewdness, remain fully unexplored. To fill this gap, we investigate performance disparities between dialects in the detection of five aspects of biased language and how to mitigate them. To alleviate bias, we present a multitask learning approach that models dialect language as an auxiliary task to incorporate syntactic and lexical variations. In our experiments with African-American English dialect, we provide empirical evidence that complementing common learning approaches with dialect modeling improves their fairness. Furthermore, the results suggest that multitask learning achieves state-of-the-art performance and helps to detect properties of biased language more reliably.
LLM-based Rewriting of Inappropriate Argumentation using Reinforcement Learning from Machine Feedback
Jun 05, 2024Ensuring that online discussions are civil and productive is a major challenge for social media platforms. Such platforms usually rely both on users and on automated detection tools to flag inappropriate arguments of other users, which moderators then review. However, this kind of post-hoc moderation is expensive and time-consuming, and moderators are often overwhelmed by the amount and severity of flagged content. Instead, a promising alternative is to prevent negative behavior during content creation. This paper studies how inappropriate language in arguments can be computationally mitigated. We propose a reinforcement learning-based rewriting approach that balances content preservation and appropriateness based on existing classifiers, prompting an instruction-finetuned large language model (LLM) as our initial policy. Unlike related style transfer tasks, rewriting inappropriate arguments allows deleting and adding content permanently. It is therefore tackled on document level rather than sentence level. We evaluate different weighting schemes for the reward function in both absolute and relative human assessment studies. Systematic experiments on non-parallel data provide evidence that our approach can mitigate the inappropriateness of arguments while largely preserving their content. It significantly outperforms competitive baselines, including few-shot learning, prompting, and humans.
Exploring LLM Prompting Strategies for Joint Essay Scoring and Feedback Generation
Apr 24, 2024
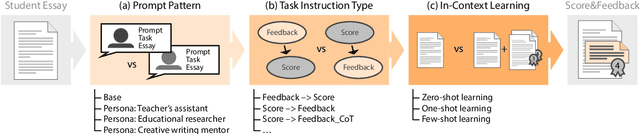


Individual feedback can help students improve their essay writing skills. However, the manual effort required to provide such feedback limits individualization in practice. Automatically-generated essay feedback may serve as an alternative to guide students at their own pace, convenience, and desired frequency. Large language models (LLMs) have demonstrated strong performance in generating coherent and contextually relevant text. Yet, their ability to provide helpful essay feedback is unclear. This work explores several prompting strategies for LLM-based zero-shot and few-shot generation of essay feedback. Inspired by Chain-of-Thought prompting, we study how and to what extent automated essay scoring (AES) can benefit the quality of generated feedback. We evaluate both the AES performance that LLMs can achieve with prompting only and the helpfulness of the generated essay feedback. Our results suggest that tackling AES and feedback generation jointly improves AES performance. However, while our manual evaluation emphasizes the quality of the generated essay feedback, the impact of essay scoring on the generated feedback remains low ultimately.
A School Student Essay Corpus for Analyzing Interactions of Argumentative Structure and Quality
Apr 03, 2024Learning argumentative writing is challenging. Besides writing fundamentals such as syntax and grammar, learners must select and arrange argument components meaningfully to create high-quality essays. To support argumentative writing computationally, one step is to mine the argumentative structure. When combined with automatic essay scoring, interactions of the argumentative structure and quality scores can be exploited for comprehensive writing support. Although studies have shown the usefulness of using information about the argumentative structure for essay scoring, no argument mining corpus with ground-truth essay quality annotations has been published yet. Moreover, none of the existing corpora contain essays written by school students specifically. To fill this research gap, we present a German corpus of 1,320 essays from school students of two age groups. Each essay has been manually annotated for argumentative structure and quality on multiple levels of granularity. We propose baseline approaches to argument mining and essay scoring, and we analyze interactions between both tasks, thereby laying the ground for quality-oriented argumentative writing support.
Argument Quality Assessment in the Age of Instruction-Following Large Language Models
Mar 24, 2024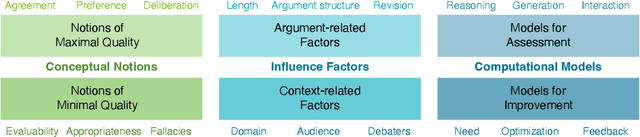

The computational treatment of arguments on controversial issues has been subject to extensive NLP research, due to its envisioned impact on opinion formation, decision making, writing education, and the like. A critical task in any such application is the assessment of an argument's quality - but it is also particularly challenging. In this position paper, we start from a brief survey of argument quality research, where we identify the diversity of quality notions and the subjectiveness of their perception as the main hurdles towards substantial progress on argument quality assessment. We argue that the capabilities of instruction-following large language models (LLMs) to leverage knowledge across contexts enable a much more reliable assessment. Rather than just fine-tuning LLMs towards leaderboard chasing on assessment tasks, they need to be instructed systematically with argumentation theories and scenarios as well as with ways to solve argument-related problems. We discuss the real-world opportunities and ethical issues emerging thereby.