 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: Automated Corpus Creation for Enthymeme Detection and Reconstruction in Learner Arguments
Oct 27, 2023Writing strong arguments can be challenging for learners. It requires to select and arrange multiple argumentative discourse units (ADUs) in a logical and coherent way as well as to decide which ADUs to leave implicit, so called enthymemes. However, when important ADUs are missing, readers might not be able to follow the reasoning or understand the argument's main point. This paper introduces two new tasks for learner arguments: to identify gaps in arguments (enthymeme detection) and to fill such gaps (enthymeme reconstruction). Approaches to both tasks may help learners improve their argument quality. We study how corpora for these tasks can be created automatically by deleting ADUs from an argumentative text that are central to the argument and its quality, while maintaining the text's naturalness. Based on the ICLEv3 corpus of argumentative learner essays, we create 40,089 argument instances for enthymeme detection and reconstruction. Through manual studies, we provide evidence that the proposed corpus creation process leads to the desired quality reduction, and results in arguments that are similarly natural to those written by learners. Finally, first baseline approaches to enthymeme detection and reconstruction demonstrate the corpus' usefulness.
EvoLearner: Learning Description Logics with Evolutionary Algorithms
Nov 08, 2021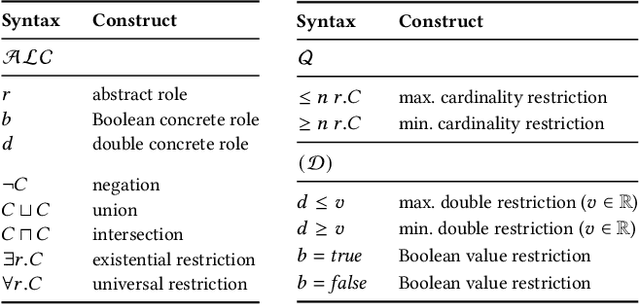
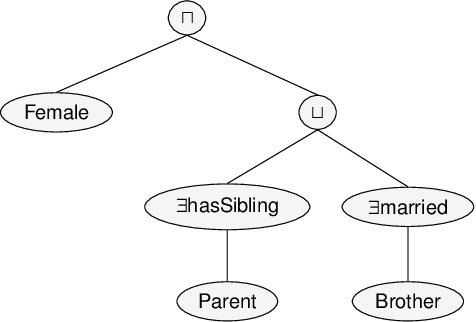
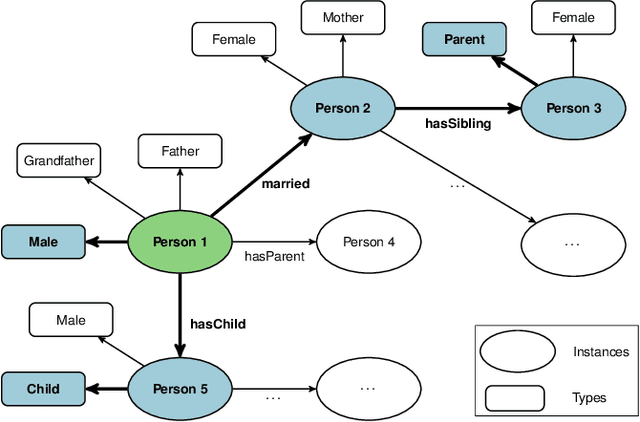
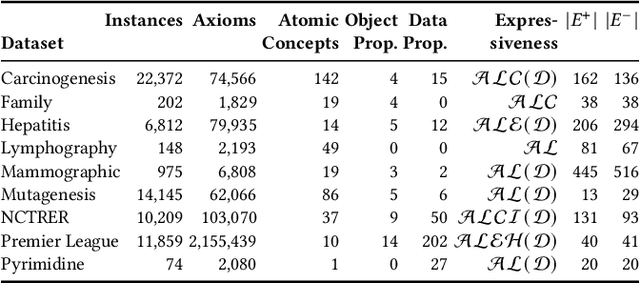
Classifying nodes in knowledge graphs is an important task, e.g., predicting missing types of entities, predicting which molecules cause cancer, or predicting which drugs are promising treatment candidates. While black-box models often achieve high predictive performance, they are only post-hoc and locally explainable and do not allow the learned model to be easily enriched with domain knowledge. Towards this end, learning description logic concepts from positive and negative examples has been proposed. However, learning such concepts often takes a long time and state-of-the-art approaches provide limited support for literal data values, although they are crucial for many applications. In this paper, we propose EvoLearner - an evolutionary approach to learn ALCQ(D), which is the attributive language with complement (ALC) paired with qualified cardinality restrictions (Q) and data properties (D). We contribute a novel initialization method for the initial population: starting from positive examples (nodes in the knowledge graph), we perform biased random walks and translate them to description logic concepts. Moreover, we improve support for data properties by maximizing information gain when deciding where to split the data. We show that our approach significantly outperforms the state of the art on the benchmarking framework SML-Bench for structured machine learning. Our ablation study confirms that this is due to our novel initialization method and support for data properties.