 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Chain Of Thoughts Prompts for Predicting Entities, Relations, and even Literals on Knowledge Graphs
Apr 14, 2026Knowledge graph embedding (KGE) models perform well on link prediction but struggle with unseen entities, relations, and especially literals, limiting their use in dynamic, heterogeneous graphs. In contrast, pretrained large language models (LLMs) generalize effectively through prompting. We reformulate link prediction as a prompt learning problem and introduce RALP, which learns string-based chain-of-thought (CoT) prompts as scoring functions for triples. Using Bayesian Optimization through MIPRO algorithm, RALP identifies effective prompts from fewer than 30 training examples without gradient access. At inference, RALP predicts missing entities, relations or whole triples and assigns confidence scores based on the learned prompt. We evaluate on transductive, numerical, and OWL instance retrieval benchmarks. RALP improves state-of-the-art KGE models by over 5% MRR across datasets and enhances generalization via high-quality inferred triples. On OWL reasoning tasks with complex class expressions (e.g., $\exists hasChild.Female$, $\geq 5 \; hasChild.Female$), it achieves over 88% Jaccard similarity. These results highlight prompt-based LLM reasoning as a flexible alternative to embedding-based methods. We release our implementation, training, and evaluation pipeline as open source: https://github.com/dice-group/RALP .
Neural Reasoning for Robust Instance Retrieval in $\mathcal{SHOIQ}$
Oct 23, 2025Concept learning exploits background knowledge in the form of description logic axioms to learn explainable classification models from knowledge bases. Despite recent breakthroughs in neuro-symbolic concept learning, most approaches still cannot be deployed on real-world knowledge bases. This is due to their use of description logic reasoners, which are not robust against inconsistencies nor erroneous data. We address this challenge by presenting a novel neural reasoner dubbed EBR. Our reasoner relies on embeddings to approximate the results of a symbolic reasoner. We show that EBR solely requires retrieving instances for atomic concepts and existential restrictions to retrieve or approximate the set of instances of any concept in the description logic $\mathcal{SHOIQ}$. In our experiments, we compare EBR with state-of-the-art reasoners. Our results suggest that EBR is robust against missing and erroneous data in contrast to existing reasoners.
Inference over Unseen Entities, Relations and Literals on Knowledge Graphs
Oct 09, 2024
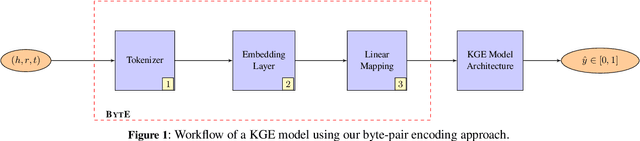

In recent years, knowledge graph embedding models have been successfully applied in the transductive setting to tackle various challenging tasks including link prediction, and query answering. Yet, the transductive setting does not allow for reasoning over unseen entities, relations, let alone numerical or non-numerical literals. Although increasing efforts are put into exploring inductive scenarios, inference over unseen entities, relations, and literals has yet to come. This limitation prohibits the existing methods from handling real-world dynamic knowledge graphs involving heterogeneous information about the world. Here, we propose a remedy to this limitation. We propose the attentive byte-pair encoding layer (BytE) to construct a triple embedding from a sequence of byte-pair encoded subword units of entities and relations. Compared to the conventional setting, BytE leads to massive feature reuse via weight tying, since it forces a knowledge graph embedding model to learn embeddings for subword units instead of entities and relations directly. Consequently, the size of the embedding matrices are not anymore bound to the unique number of entities and relations of a knowledge graph. Experimental results show that BytE improves the link prediction performance of 4 knowledge graph embedding models on datasets where the syntactic representations of triples are semantically meaningful. However, benefits of training a knowledge graph embedding model with BytE dissipate on knowledge graphs where entities and relations are represented with plain numbers or URIs. We provide an open source implementation of BytE to foster reproducible research.
Performance Evaluation of Knowledge Graph Embedding Approaches under Non-adversarial Attacks
Jul 09, 2024



Knowledge Graph Embedding (KGE) transforms a discrete Knowledge Graph (KG) into a continuous vector space facilitating its use in various AI-driven applications like Semantic Search, Question Answering, or Recommenders. While KGE approaches are effective in these applications, most existing approaches assume that all information in the given KG is correct. This enables attackers to influence the output of these approaches, e.g., by perturbing the input. Consequently, the robustness of such KGE approaches has to be addressed. Recent work focused on adversarial attacks. However, non-adversarial attacks on all attack surfaces of these approaches have not been thoroughly examined. We close this gap by evaluating the impact of non-adversarial attacks on the performance of 5 state-of-the-art KGE algorithms on 5 datasets with respect to attacks on 3 attack surfaces-graph, parameter, and label perturbation. Our evaluation results suggest that label perturbation has a strong effect on the KGE performance, followed by parameter perturbation with a moderate and graph with a low effect.
Adaptive Stochastic Weight Averaging
Jun 27, 2024



Ensemble models often improve generalization performances in challenging tasks. Yet, traditional techniques based on prediction averaging incur three well-known disadvantages: the computational overhead of training multiple models, increased latency, and memory requirements at test time. To address these issues, the Stochastic Weight Averaging (SWA) technique maintains a running average of model parameters from a specific epoch onward. Despite its potential benefits, maintaining a running average of parameters can hinder generalization, as an underlying running model begins to overfit. Conversely, an inadequately chosen starting point can render SWA more susceptible to underfitting compared to an underlying running model. In this work, we propose Adaptive Stochastic Weight Averaging (ASWA) technique that updates a running average of model parameters, only when generalization performance is improved on the validation dataset. Hence, ASWA can be seen as a combination of SWA with the early stopping technique, where the former accepts all updates on a parameter ensemble model and the latter rejects any update on an underlying running model. We conducted extensive experiments ranging from image classification to multi-hop reasoning over knowledge graphs. Our experiments over 11 benchmark datasets with 7 baseline models suggest that ASWA leads to a statistically better generalization across models and datasets
Embedding Knowledge Graphs in Degenerate Clifford Algebras
Feb 06, 2024Clifford algebras are a natural generalization of the real numbers, the complex numbers, and the quaternions. So far, solely Clifford algebras of the form $Cl_{p,q}$ (i.e., algebras without nilpotent base vectors) have been studied in the context of knowledge graph embeddings. We propose to consider nilpotent base vectors with a nilpotency index of two. In these spaces, denoted $Cl_{p,q,r}$, allows generalizing over approaches based on dual numbers (which cannot be modelled using $Cl_{p,q}$) and capturing patterns that emanate from the absence of higher-order interactions between real and complex parts of entity embeddings. We design two new models for the discovery of the parameters $p$, $q$, and $r$. The first model uses a greedy search to optimize $p$, $q$, and $r$. The second predicts $(p, q,r)$ based on an embedding of the input knowledge graph computed using neural networks. The results of our evaluation on seven benchmark datasets suggest that nilpotent vectors can help capture embeddings better. Our comparison against the state of the art suggests that our approach generalizes better than other approaches on all datasets w.r.t. the MRR it achieves on validation data. We also show that a greedy search suffices to discover values of $p$, $q$ and $r$ that are close to optimal.
Universal Knowledge Graph Embeddings
Oct 23, 2023A variety of knowledge graph embedding approaches have been developed. Most of them obtain embeddings by learning the structure of the knowledge graph within a link prediction setting. As a result, the embeddings reflect only the semantics of a single knowledge graph, and embeddings for different knowledge graphs are not aligned, e.g., they cannot be used to find similar entities across knowledge graphs via nearest neighbor search. However, knowledge graph embedding applications such as entity disambiguation require a more global representation, i.e., a representation that is valid across multiple sources. We propose to learn universal knowledge graph embeddings from large-scale interlinked knowledge sources. To this end, we fuse large knowledge graphs based on the owl:sameAs relation such that every entity is represented by a unique identity. We instantiate our idea by computing universal embeddings based on DBpedia and Wikidata yielding embeddings for about 180 million entities, 15 thousand relations, and 1.2 billion triples. Moreover, we develop a convenient API to provide embeddings as a service. Experiments on link prediction show that universal knowledge graph embeddings encode better semantics compared to embeddings computed on a single knowledge graph. For reproducibility purposes, we provide our source code and datasets open access at https://github.com/dice-group/Universal_Embeddings
LitCQD: Multi-Hop Reasoning in Incomplete Knowledge Graphs with Numeric Literals
Apr 28, 2023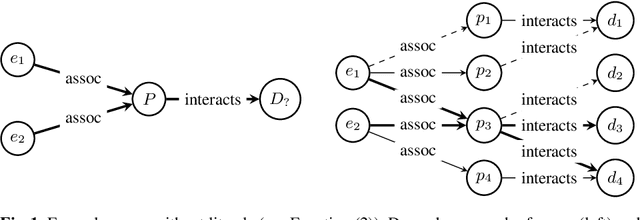
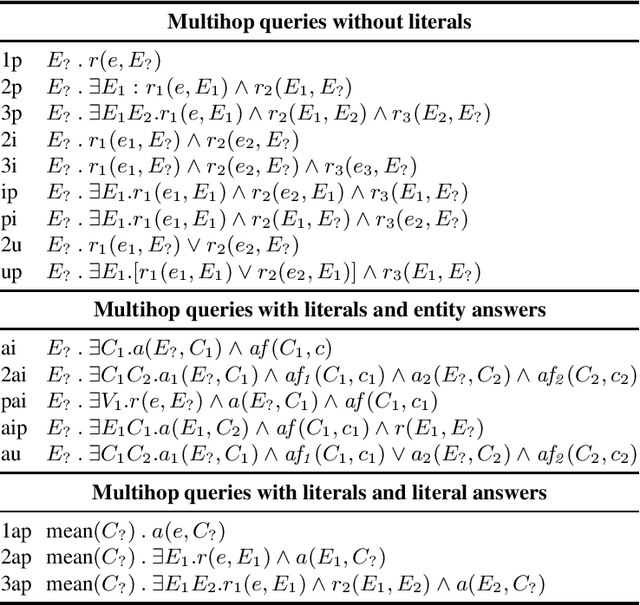
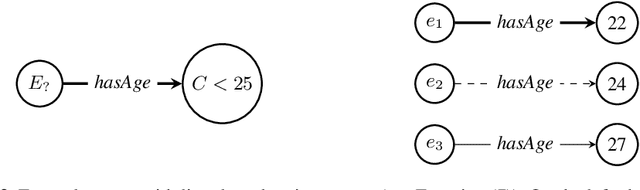
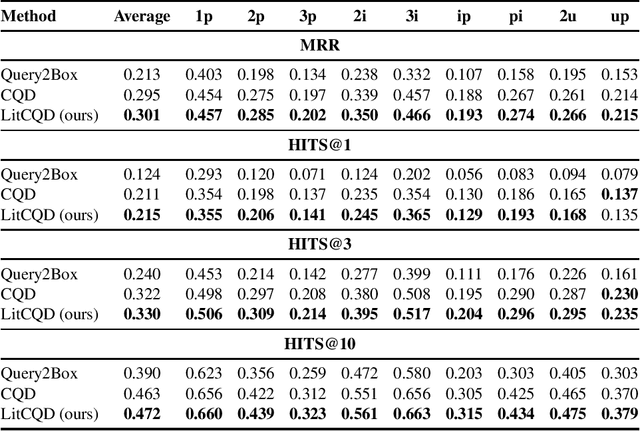
Most real-world knowledge graphs, including Wikidata, DBpedia, and Yago are incomplete. Answering queries on such incomplete graphs is an important, but challenging problem. Recently, a number of approaches, including complex query decomposition (CQD), have been proposed to answer complex, multi-hop queries with conjunctions and disjunctions on such graphs. However, all state-of-the-art approaches only consider graphs consisting of entities and relations, neglecting literal values. In this paper, we propose LitCQD -- an approach to answer complex, multi-hop queries where both the query and the knowledge graph can contain numeric literal values: LitCQD can answer queries having numerical answers or having entity answers satisfying numerical constraints. For example, it allows to query (1)~persons living in New York having a certain age, and (2)~the average age of persons living in New York. We evaluate LitCQD on query types with and without literal values. To evaluate LitCQD, we generate complex, multi-hop queries and their expected answers on a version of the FB15k-237 dataset that was extended by literal values.
Learning Permutation-Invariant Embeddings for Description Logic Concepts
Mar 03, 2023Concept learning deals with learning description logic concepts from a background knowledge and input examples. The goal is to learn a concept that covers all positive examples, while not covering any negative examples. This non-trivial task is often formulated as a search problem within an infinite quasi-ordered concept space. Although state-of-the-art models have been successfully applied to tackle this problem, their large-scale applications have been severely hindered due to their excessive exploration incurring impractical runtimes. Here, we propose a remedy for this limitation. We reformulate the learning problem as a multi-label classification problem and propose a neural embedding model (NERO) that learns permutation-invariant embeddings for sets of examples tailored towards predicting $F_1$ scores of pre-selected description logic concepts. By ranking such concepts in descending order of predicted scores, a possible goal concept can be detected within few retrieval operations, i.e., no excessive exploration. Importantly, top-ranked concepts can be used to start the search procedure of state-of-the-art symbolic models in multiple advantageous regions of a concept space, rather than starting it in the most general concept $\top$. Our experiments on 5 benchmark datasets with 770 learning problems firmly suggest that NERO significantly (p-value <1%) outperforms the state-of-the-art models in terms of $F_1$ score, the number of explored concepts, and the total runtime. We provide an open-source implementation of our approach.
Hardware-agnostic Computation for Large-scale Knowledge Graph Embeddings
Jul 18, 2022
Knowledge graph embedding research has mainly focused on learning continuous representations of knowledge graphs towards the link prediction problem. Recently developed frameworks can be effectively applied in research related applications. Yet, these frameworks do not fulfill many requirements of real-world applications. As the size of the knowledge graph grows, moving computation from a commodity computer to a cluster of computers in these frameworks becomes more challenging. Finding suitable hyperparameter settings w.r.t. time and computational budgets are left to practitioners. In addition, the continual learning aspect in knowledge graph embedding frameworks is often ignored, although continual learning plays an important role in many real-world (deep) learning-driven applications. Arguably, these limitations explain the lack of publicly available knowledge graph embedding models for large knowledge graphs. We developed a framework based on the frameworks DASK, Pytorch Lightning and Hugging Face to compute embeddings for large-scale knowledge graphs in a hardware-agnostic manner, which is able to address real-world challenges pertaining to the scale of real application. We provide an open-source version of our framework along with a hub of pre-trained models having more than 11.4 B parameters.