 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan You Tell the Difference? Contrastive Explanations for ABox Entailments
Nov 14, 2025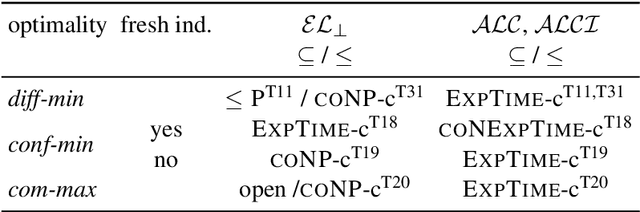
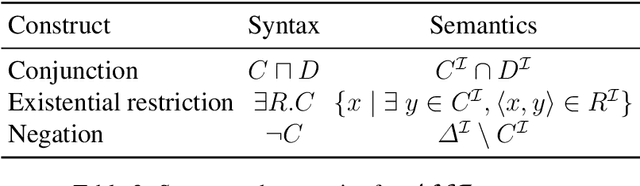


We introduce the notion of contrastive ABox explanations to answer questions of the type "Why is a an instance of C, but b is not?". While there are various approaches for explaining positive entailments (why is C(a) entailed by the knowledge base) as well as missing entailments (why is C(b) not entailed) in isolation, contrastive explanations consider both at the same time, which allows them to focus on the relevant commonalities and differences between a and b. We develop an appropriate notion of contrastive explanations for the special case of ABox reasoning with description logic ontologies, and analyze the computational complexity for different variants under different optimality criteria, considering lightweight as well as more expressive description logics. We implemented a first method for computing one variant of contrastive explanations, and evaluated it on generated problems for realistic knowledge bases.
Neural Reasoning for Robust Instance Retrieval in $\mathcal{SHOIQ}$
Oct 23, 2025Concept learning exploits background knowledge in the form of description logic axioms to learn explainable classification models from knowledge bases. Despite recent breakthroughs in neuro-symbolic concept learning, most approaches still cannot be deployed on real-world knowledge bases. This is due to their use of description logic reasoners, which are not robust against inconsistencies nor erroneous data. We address this challenge by presenting a novel neural reasoner dubbed EBR. Our reasoner relies on embeddings to approximate the results of a symbolic reasoner. We show that EBR solely requires retrieving instances for atomic concepts and existential restrictions to retrieve or approximate the set of instances of any concept in the description logic $\mathcal{SHOIQ}$. In our experiments, we compare EBR with state-of-the-art reasoners. Our results suggest that EBR is robust against missing and erroneous data in contrast to existing reasoners.
Explainable Benchmarking through the Lense of Concept Learning
Oct 23, 2025Evaluating competing systems in a comparable way, i.e., benchmarking them, is an undeniable pillar of the scientific method. However, system performance is often summarized via a small number of metrics. The analysis of the evaluation details and the derivation of insights for further development or use remains a tedious manual task with often biased results. Thus, this paper argues for a new type of benchmarking, which is dubbed explainable benchmarking. The aim of explainable benchmarking approaches is to automatically generate explanations for the performance of systems in a benchmark. We provide a first instantiation of this paradigm for knowledge-graph-based question answering systems. We compute explanations by using a novel concept learning approach developed for large knowledge graphs called PruneCEL. Our evaluation shows that PruneCEL outperforms state-of-the-art concept learners on the task of explainable benchmarking by up to 0.55 points F1 measure. A task-driven user study with 41 participants shows that in 80\% of the cases, the majority of participants can accurately predict the behavior of a system based on our explanations. Our code and data are available at https://github.com/dice-group/PruneCEL/tree/K-cap2025
Investigating Co-Constructive Behavior of Large Language Models in Explanation Dialogues
Apr 25, 2025The ability to generate explanations that are understood by explainees is the quintessence of explainable artificial intelligence. Since understanding depends on the explainee's background and needs, recent research has focused on co-constructive explanation dialogues, where the explainer continuously monitors the explainee's understanding and adapts explanations dynamically. We investigate the ability of large language models (LLMs) to engage as explainers in co-constructive explanation dialogues. In particular, we present a user study in which explainees interact with LLMs, of which some have been instructed to explain a predefined topic co-constructively. We evaluate the explainees' understanding before and after the dialogue, as well as their perception of the LLMs' co-constructive behavior. Our results indicate that current LLMs show some co-constructive behaviors, such as asking verification questions, that foster the explainees' engagement and can improve understanding of a topic. However, their ability to effectively monitor the current understanding and scaffold the explanations accordingly remains limited.
Aligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
Resilience in Knowledge Graph Embeddings
Oct 28, 2024In recent years, knowledge graphs have gained interest and witnessed widespread applications in various domains, such as information retrieval, question-answering, recommendation systems, amongst others. Large-scale knowledge graphs to this end have demonstrated their utility in effectively representing structured knowledge. To further facilitate the application of machine learning techniques, knowledge graph embedding (KGE) models have been developed. Such models can transform entities and relationships within knowledge graphs into vectors. However, these embedding models often face challenges related to noise, missing information, distribution shift, adversarial attacks, etc. This can lead to sub-optimal embeddings and incorrect inferences, thereby negatively impacting downstream applications. While the existing literature has focused so far on adversarial attacks on KGE models, the challenges related to the other critical aspects remain unexplored. In this paper, we, first of all, give a unified definition of resilience, encompassing several factors such as generalisation, performance consistency, distribution adaption, and robustness. After formalizing these concepts for machine learning in general, we define them in the context of knowledge graphs. To find the gap in the existing works on resilience in the context of knowledge graphs, we perform a systematic survey, taking into account all these aspects mentioned previously. Our survey results show that most of the existing works focus on a specific aspect of resilience, namely robustness. After categorizing such works based on their respective aspects of resilience, we discuss the challenges and future research directions.
Inference over Unseen Entities, Relations and Literals on Knowledge Graphs
Oct 09, 2024
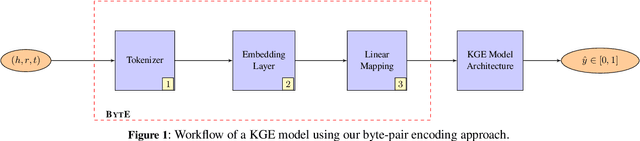

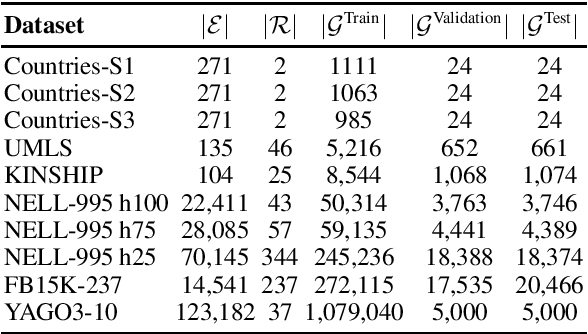
In recent years, knowledge graph embedding models have been successfully applied in the transductive setting to tackle various challenging tasks including link prediction, and query answering. Yet, the transductive setting does not allow for reasoning over unseen entities, relations, let alone numerical or non-numerical literals. Although increasing efforts are put into exploring inductive scenarios, inference over unseen entities, relations, and literals has yet to come. This limitation prohibits the existing methods from handling real-world dynamic knowledge graphs involving heterogeneous information about the world. Here, we propose a remedy to this limitation. We propose the attentive byte-pair encoding layer (BytE) to construct a triple embedding from a sequence of byte-pair encoded subword units of entities and relations. Compared to the conventional setting, BytE leads to massive feature reuse via weight tying, since it forces a knowledge graph embedding model to learn embeddings for subword units instead of entities and relations directly. Consequently, the size of the embedding matrices are not anymore bound to the unique number of entities and relations of a knowledge graph. Experimental results show that BytE improves the link prediction performance of 4 knowledge graph embedding models on datasets where the syntactic representations of triples are semantically meaningful. However, benefits of training a knowledge graph embedding model with BytE dissipate on knowledge graphs where entities and relations are represented with plain numbers or URIs. We provide an open source implementation of BytE to foster reproducible research.
LOLA -- An Open-Source Massively Multilingual Large Language Model
Sep 19, 2024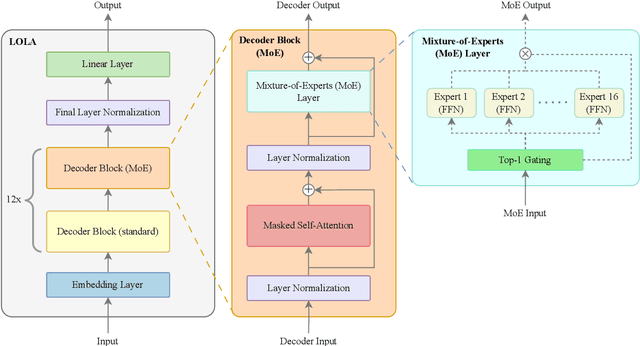
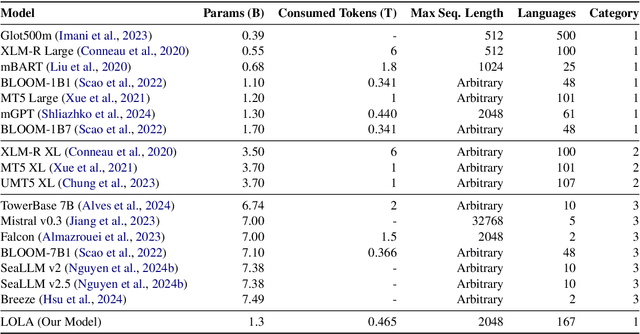
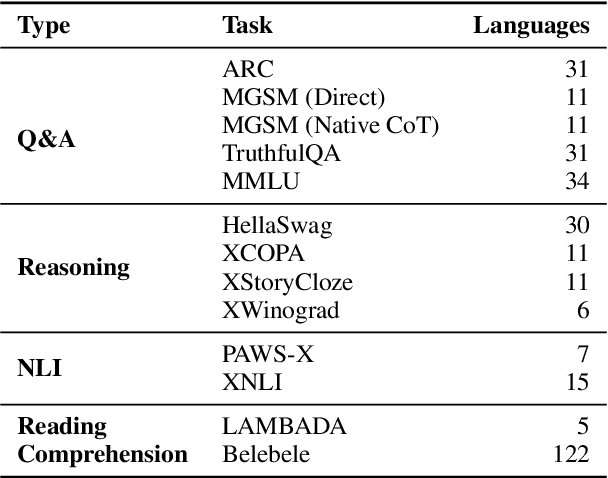
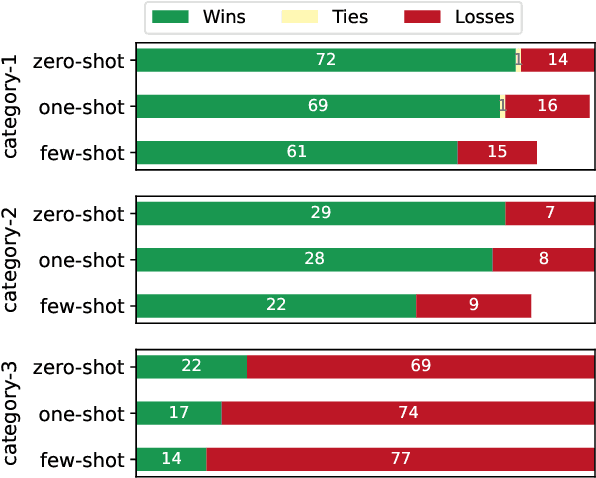
This paper presents LOLA, a massively multilingual large language model trained on more than 160 languages using a sparse Mixture-of-Experts Transformer architecture. Our architectural and implementation choices address the challenge of harnessing linguistic diversity while maintaining efficiency and avoiding the common pitfalls of multilinguality. Our analysis of the evaluation results shows competitive performance in natural language generation and understanding tasks. Additionally, we demonstrate how the learned expert-routing mechanism exploits implicit phylogenetic linguistic patterns to potentially alleviate the curse of multilinguality. We provide an in-depth look at the training process, an analysis of the datasets, and a balanced exploration of the model's strengths and limitations. As an open-source model, LOLA promotes reproducibility and serves as a robust foundation for future research. Our findings enable the development of compute-efficient multilingual models with strong, scalable performance across languages.
HybridFC: A Hybrid Fact-Checking Approach for Knowledge Graphs
Sep 10, 2024We consider fact-checking approaches that aim to predict the veracity of assertions in knowledge graphs. Five main categories of fact-checking approaches for knowledge graphs have been proposed in the recent literature, of which each is subject to partially overlapping limitations. In particular, current text-based approaches are limited by manual feature engineering. Path-based and rule-based approaches are limited by their exclusive use of knowledge graphs as background knowledge, and embedding-based approaches suffer from low accuracy scores on current fact-checking tasks. We propose a hybrid approach -- dubbed HybridFC -- that exploits the diversity of existing categories of fact-checking approaches within an ensemble learning setting to achieve a significantly better prediction performance. In particular, our approach outperforms the state of the art by 0.14 to 0.27 in terms of Area Under the Receiver Operating Characteristic curve on the FactBench dataset. Our code is open-source and can be found at https://github.com/dice-group/HybridFC.
Performance Evaluation of Knowledge Graph Embedding Approaches under Non-adversarial Attacks
Jul 09, 2024



Knowledge Graph Embedding (KGE) transforms a discrete Knowledge Graph (KG) into a continuous vector space facilitating its use in various AI-driven applications like Semantic Search, Question Answering, or Recommenders. While KGE approaches are effective in these applications, most existing approaches assume that all information in the given KG is correct. This enables attackers to influence the output of these approaches, e.g., by perturbing the input. Consequently, the robustness of such KGE approaches has to be addressed. Recent work focused on adversarial attacks. However, non-adversarial attacks on all attack surfaces of these approaches have not been thoroughly examined. We close this gap by evaluating the impact of non-adversarial attacks on the performance of 5 state-of-the-art KGE algorithms on 5 datasets with respect to attacks on 3 attack surfaces-graph, parameter, and label perturbation. Our evaluation results suggest that label perturbation has a strong effect on the KGE performance, followed by parameter perturbation with a moderate and graph with a low effect.