 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of LLM-based Explanations for a Learning Analytics Dashboard
Nov 11, 2025Learning Analytics Dashboards can be a powerful tool to support self-regulated learning in Digital Learning Environments and promote development of meta-cognitive skills, such as reflection. However, their effectiveness can be affected by the interpretability of the data they provide. To assist in the interpretation, we employ a large language model to generate verbal explanations of the data in the dashboard and evaluate it against a standalone dashboard and explanations provided by human teachers in an expert study with university level educators (N=12). We find that the LLM-based explanations of the skill state presented in the dashboard, as well as general recommendations on how to proceed with learning within the course are significantly more favored compared to the other conditions. This indicates that using LLMs for interpretation purposes can enhance the learning experience for learners while maintaining the pedagogical standards approved by teachers.
LLM Analysis of 150+ years of German Parliamentary Debates on Migration Reveals Shift from Post-War Solidarity to Anti-Solidarity in the Last Decade
Sep 08, 2025Migration has been a core topic in German political debate, from millions of expellees post World War II over labor migration to refugee movements in the recent past. Studying political speech regarding such wide-ranging phenomena in depth traditionally required extensive manual annotations, limiting the scope of analysis to small subsets of the data. Large language models (LLMs) have the potential to partially automate even complex annotation tasks. We provide an extensive evaluation of a multiple LLMs in annotating (anti-)solidarity subtypes in German parliamentary debates compared to a large set of thousands of human reference annotations (gathered over a year). We evaluate the influence of model size, prompting differences, fine-tuning, historical versus contemporary data; and we investigate systematic errors. Beyond methodological evaluation, we also interpret the resulting annotations from a social science lense, gaining deeper insight into (anti-)solidarity trends towards migrants in the German post-World War II period and recent past. Our data reveals a high degree of migrant-directed solidarity in the postwar period, as well as a strong trend towards anti-solidarity in the German parliament since 2015, motivating further research. These findings highlight the promise of LLMs for political text analysis and the importance of migration debates in Germany, where demographic decline and labor shortages coexist with rising polarization.
Aligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
Generative Example-Based Explanations: Bridging the Gap between Generative Modeling and Explainability
Oct 28, 2024



Recently, several methods have leveraged deep generative modeling to produce example-based explanations of decision algorithms for high-dimensional input data. Despite promising results, a disconnect exists between these methods and the classical explainability literature, which focuses on lower-dimensional data with semantically meaningful features. This conceptual and communication gap leads to misunderstandings and misalignments in goals and expectations. In this paper, we bridge this gap by proposing a novel probabilistic framework for local example-based explanations. Our framework integrates the critical characteristics of classical local explanation desiderata while being amenable to high-dimensional data and their modeling through deep generative models. Our aim is to facilitate communication, foster rigor and transparency, and improve the quality of peer discussion and research progress.
FairGLVQ: Fairness in Partition-Based Classification
Oct 16, 2024Fairness is an important objective throughout society. From the distribution of limited goods such as education, over hiring and payment, to taxes, legislation, and jurisprudence. Due to the increasing importance of machine learning approaches in all areas of daily life including those related to health, security, and equity, an increasing amount of research focuses on fair machine learning. In this work, we focus on the fairness of partition- and prototype-based models. The contribution of this work is twofold: 1) we develop a general framework for fair machine learning of partition-based models that does not depend on a specific fairness definition, and 2) we derive a fair version of learning vector quantization (LVQ) as a specific instantiation. We compare the resulting algorithm against other algorithms from the literature on theoretical and real-world data showing its practical relevance.
GradCheck: Analyzing classifier guidance gradients for conditional diffusion sampling
Jun 25, 2024



To sample from an unconditionally trained Denoising Diffusion Probabilistic Model (DDPM), classifier guidance adds conditional information during sampling, but the gradients from classifiers, especially those not trained on noisy images, are often unstable. This study conducts a gradient analysis comparing robust and non-robust classifiers, as well as multiple gradient stabilization techniques. Experimental results demonstrate that these techniques significantly improve the quality of class-conditional samples for non-robust classifiers by providing more stable and informative classifier guidance gradients. The findings highlight the importance of gradient stability in enhancing the performance of classifier guidance, especially on non-robust classifiers.
Continual Imitation Learning for Prosthetic Limbs
May 02, 2024



Lower limb amputations and neuromuscular impairments severely restrict mobility, necessitating advancements beyond conventional prosthetics. Motorized bionic limbs offer promise, but their utility depends on mimicking the evolving synergy of human movement in various settings. In this context, we present a novel model for bionic prostheses' application that leverages camera-based motion capture and wearable sensor data, to learn the synergistic coupling of the lower limbs during human locomotion, empowering it to infer the kinematic behavior of a missing lower limb across varied tasks, such as climbing inclines and stairs. We propose a model that can multitask, adapt continually, anticipate movements, and refine. The core of our method lies in an approach which we call -- multitask prospective rehearsal -- that anticipates and synthesizes future movements based on the previous prediction and employs a corrective mechanism for subsequent predictions. We design an evolving architecture that merges lightweight, task-specific modules on a shared backbone, ensuring both specificity and scalability. We empirically validate our model against various baselines using real-world human gait datasets, including experiments with transtibial amputees, which encompass a broad spectrum of locomotion tasks. The results show that our approach consistently outperforms baseline models, particularly under scenarios affected by distributional shifts, adversarial perturbations, and noise.
Diffusion-based Visual Counterfactual Explanations -- Towards Systematic Quantitative Evaluation
Aug 11, 2023Latest methods for visual counterfactual explanations (VCE) harness the power of deep generative models to synthesize new examples of high-dimensional images of impressive quality. However, it is currently difficult to compare the performance of these VCE methods as the evaluation procedures largely vary and often boil down to visual inspection of individual examples and small scale user studies. In this work, we propose a framework for systematic, quantitative evaluation of the VCE methods and a minimal set of metrics to be used. We use this framework to explore the effects of certain crucial design choices in the latest diffusion-based generative models for VCEs of natural image classification (ImageNet). We conduct a battery of ablation-like experiments, generating thousands of VCEs for a suite of classifiers of various complexity, accuracy and robustness. Our findings suggest multiple directions for future advancements and improvements of VCE methods. By sharing our methodology and our approach to tackle the computational challenges of such a study on a limited hardware setup (including the complete code base), we offer a valuable guidance for researchers in the field fostering consistency and transparency in the assessment of counterfactual explanations.
Recursive Tree Grammar Autoencoders
Dec 15, 2020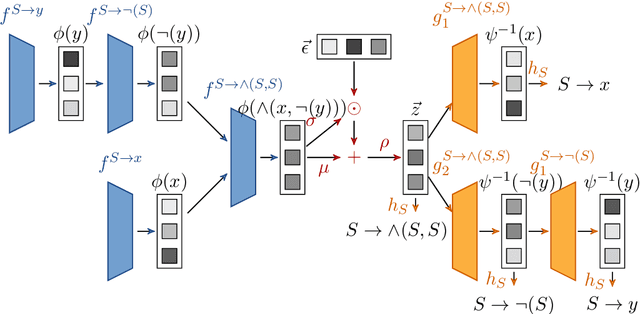
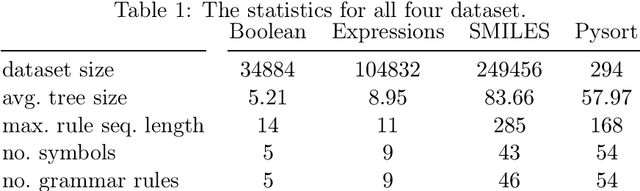

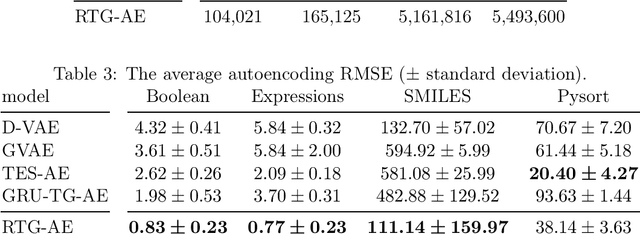
Machine learning on tree data has been mostly focused on trees as input. Much less research has investigates trees as output, like in molecule optimization for drug discovery or hint generation for intelligent tutoring systems. In this work, we propose a novel autoencoder approach, called recursive tree grammar autoencoder (RTG-AE), which encodes trees via a bottom-up parser and decodes trees via a tree grammar, both controlled by neural networks that minimize the variational autoencoder loss. The resulting encoding and decoding functions can then be employed in subsequent tasks, such as optimization and time series prediction. RTG-AE combines variational autoencoders, grammatical knowledge, and recursive processing. Our key message is that this combination improves performance compared to only combining two of these three components. In particular, we show experimentally that our proposed method improves the autoencoding error, training time, and optimization score on four benchmark datasets compared to baselines from the literature.
Tree Echo State Autoencoders with Grammars
Apr 19, 2020

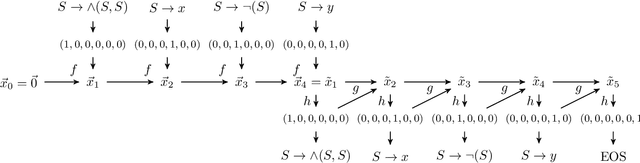

Tree data occurs in many forms, such as computer programs, chemical molecules, or natural language. Unfortunately, the non-vectorial and discrete nature of trees makes it challenging to construct functions with tree-formed output, complicating tasks such as optimization or time series prediction. Autoencoders address this challenge by mapping trees to a vectorial latent space, where tasks are easier to solve, and then mapping the solution back to a tree structure. However, existing autoencoding approaches for tree data fail to take the specific grammatical structure of tree domains into account and rely on deep learning, thus requiring large training datasets and long training times. In this paper, we propose tree echo state autoencoders (TES-AE), which are guided by a tree grammar and can be trained within seconds by virtue of reservoir computing. In our evaluation on three datasets, we demonstrate that our proposed approach is not only much faster than a state-of-the-art deep learning autoencoding approach (D-VAE) but also has less autoencoding error if little data and time is given.