 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStretchBot: A Neuro-Symbolic Framework for Adaptive Guidance with Assistive Robots
Apr 01, 2026Assistive robots have growing potential to support physical wellbeing in home and healthcare settings, for example, by guiding users through stretching or rehabilitation routines. However, existing systems remain largely scripted, which limits their ability to adapt to user state, environmental context, and interaction dynamics. In this work, we present StretchBot, a hybrid neuro-symbolic robotic coach for adaptive assistive guidance. The system combines multimodal perception with knowledge-graph-grounded large language model reasoning to support context-aware adjustments during short stretching sessions while maintaining a structured routine. To complement the system description, we report an exploratory pilot comparison between scripted and adaptive guidance with three participants. The pilot findings suggest that the adaptive condition improved perceived adaptability and contextual relevance, while scripted guidance remained competitive in smoothness and predictability. These results provide preliminary evidence that structured actionable knowledge can help ground language-model-based adaptation in embodied assistive interaction, while also highlighting the need for larger, longitudinal studies to evaluate robustness, generalizability, and long-term user experience.
Enhancing Structural Mapping with LLM-derived Abstractions for Analogical Reasoning in Narratives
Mar 31, 2026Analogical reasoning is a key driver of human generalization in problem-solving and argumentation. Yet, analogies between narrative structures remain challenging for machines. Cognitive engines for structural mapping are not directly applicable, as they assume pre-extracted entities, whereas LLMs' performance is sensitive to prompt format and the degree of surface similarity between narratives. This gap motivates a key question: What is the impact of enhancing structural mapping with LLM-derived abstractions on their analogical reasoning ability in narratives? To that end, we propose a modular framework named YARN (Yielding Abstractions for Reasoning in Narratives), which uses LLMs to decompose narratives into units, abstract these units, and then passes them to a mapping component that aligns elements across stories to perform analogical reasoning. We define and operationalize four levels of abstraction that capture both the general meaning of units and their roles in the story, grounded in prior work on framing. Our experiments reveal that abstractions consistently improve model performance, resulting in competitive or better performance than end-to-end LLM baselines. Closer error analysis reveals the remaining challenges in abstraction at the right level, in incorporating implicit causality, and an emerging categorization of analogical patterns in narratives. YARN enables systematic variation of experimental settings to analyze component contributions, and to support future work, we make the code for YARN openly available.
The Carbon Footprint Wizard: A Knowledge-Augmented AI Interface for Streamlining Food Carbon Footprint Analysis
Sep 09, 2025Environmental sustainability, particularly in relation to climate change, is a key concern for consumers, producers, and policymakers. The carbon footprint, based on greenhouse gas emissions, is a standard metric for quantifying the contribution to climate change of activities and is often assessed using life cycle assessment (LCA). However, conducting LCA is complex due to opaque and global supply chains, as well as fragmented data. This paper presents a methodology that combines advances in LCA and publicly available databases with knowledge-augmented AI techniques, including retrieval-augmented generation, to estimate cradle-to-gate carbon footprints of food products. We introduce a chatbot interface that allows users to interactively explore the carbon impact of composite meals and relate the results to familiar activities. A live web demonstration showcases our proof-of-concept system with arbitrary food items and follow-up questions, highlighting both the potential and limitations - such as database uncertainties and AI misinterpretations - of delivering LCA insights in an accessible format.
Clustering Internet Memes Through Template Matching and Multi-Dimensional Similarity
Apr 30, 2025

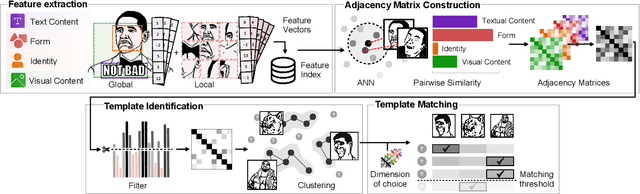

Meme clustering is critical for toxicity detection, virality modeling, and typing, but it has received little attention in previous research. Clustering similar Internet memes is challenging due to their multimodality, cultural context, and adaptability. Existing approaches rely on databases, overlook semantics, and struggle to handle diverse dimensions of similarity. This paper introduces a novel method that uses template-based matching with multi-dimensional similarity features, thus eliminating the need for predefined databases and supporting adaptive matching. Memes are clustered using local and global features across similarity categories such as form, visual content, text, and identity. Our combined approach outperforms existing clustering methods, producing more consistent and coherent clusters, while similarity-based feature sets enable adaptability and align with human intuition. We make all supporting code publicly available to support subsequent research. Code: https://github.com/tygobl/meme-clustering
MLLMs Know Where to Look: Training-free Perception of Small Visual Details with Multimodal LLMs
Feb 24, 2025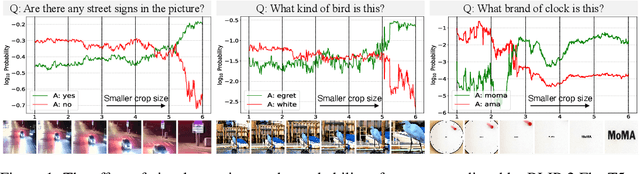
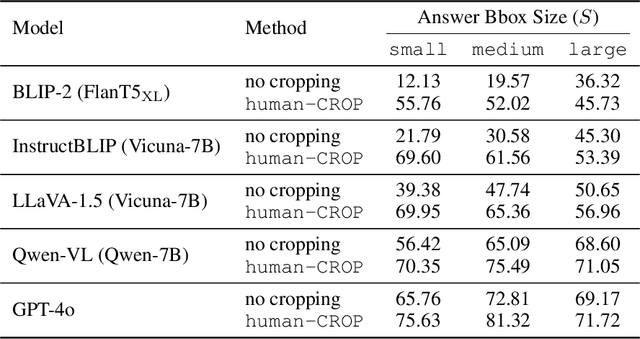
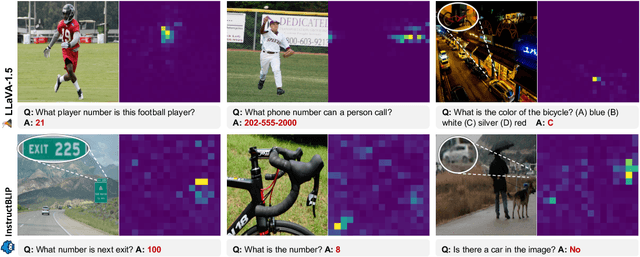
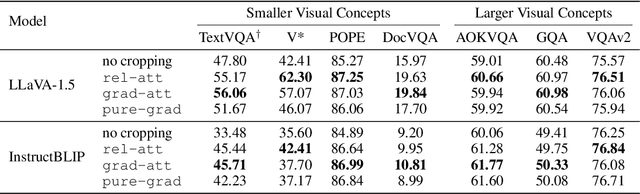
Multimodal Large Language Models (MLLMs) have experienced rapid progress in visual recognition tasks in recent years. Given their potential integration into many critical applications, it is important to understand the limitations of their visual perception. In this work, we study whether MLLMs can perceive small visual details as effectively as large ones when answering questions about images. We observe that their performance is very sensitive to the size of the visual subject of the question, and further show that this effect is in fact causal by conducting an intervention study. Next, we study the attention patterns of MLLMs when answering visual questions, and intriguingly find that they consistently know where to look, even when they provide the wrong answer. Based on these findings, we then propose training-free visual intervention methods that leverage the internal knowledge of any MLLM itself, in the form of attention and gradient maps, to enhance its perception of small visual details. We evaluate our proposed methods on two widely-used MLLMs and seven visual question answering benchmarks and show that they can significantly improve MLLMs' accuracy without requiring any training. Our results elucidate the risk of applying MLLMs to visual recognition tasks concerning small details and indicate that visual intervention using the model's internal state is a promising direction to mitigate this risk.
Investigating the Robustness of Deductive Reasoning with Large Language Models
Feb 04, 2025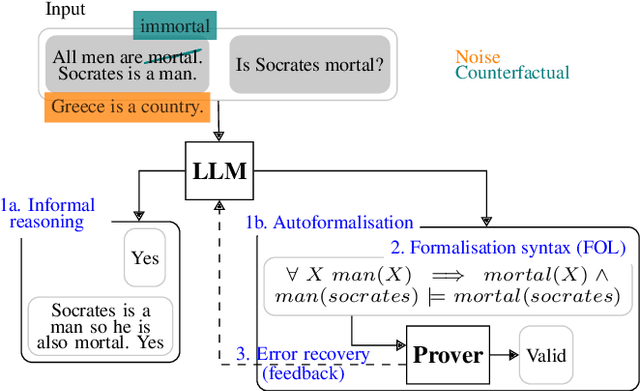
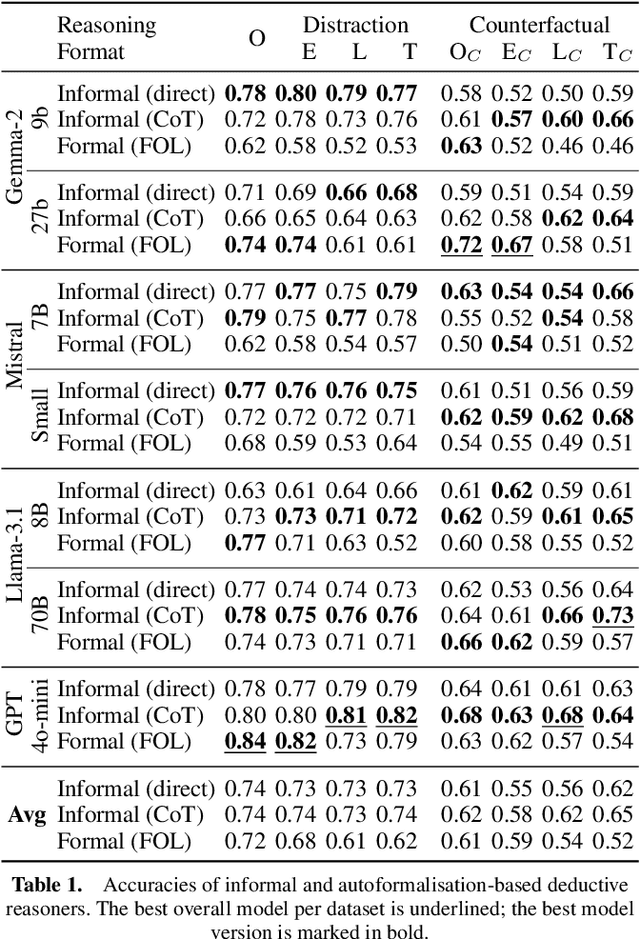

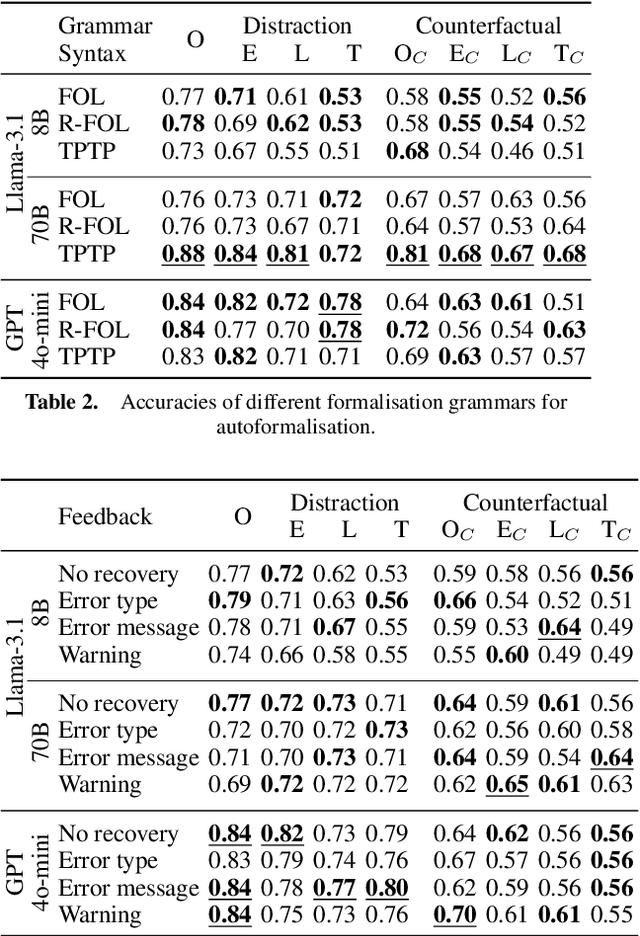
Large Language Models (LLMs) have been shown to achieve impressive results for many reasoning-based Natural Language Processing (NLP) tasks, suggesting a degree of deductive reasoning capability. However, it remains unclear to which extent LLMs, in both informal and autoformalisation methods, are robust on logical deduction tasks. Moreover, while many LLM-based deduction methods have been proposed, there is a lack of a systematic study that analyses the impact of their design components. Addressing these two challenges, we propose the first study of the robustness of LLM-based deductive reasoning methods. We devise a framework with two families of perturbations: adversarial noise and counterfactual statements, which jointly generate seven perturbed datasets. We organize the landscape of LLM reasoners according to their reasoning format, formalisation syntax, and feedback for error recovery. The results show that adversarial noise affects autoformalisation, while counterfactual statements influence all approaches. Detailed feedback does not improve overall accuracy despite reducing syntax errors, pointing to the challenge of LLM-based methods to self-correct effectively.
Commonsense Video Question Answering through Video-Grounded Entailment Tree Reasoning
Jan 09, 2025



This paper proposes the first video-grounded entailment tree reasoning method for commonsense video question answering (VQA). Despite the remarkable progress of large visual-language models (VLMs), there are growing concerns that they learn spurious correlations between videos and likely answers, reinforced by their black-box nature and remaining benchmarking biases. Our method explicitly grounds VQA tasks to video fragments in four steps: entailment tree construction, video-language entailment verification, tree reasoning, and dynamic tree expansion. A vital benefit of the method is its generalizability to current video and image-based VLMs across reasoning types. To support fair evaluation, we devise a de-biasing procedure based on large-language models that rewrites VQA benchmark answer sets to enforce model reasoning. Systematic experiments on existing and de-biased benchmarks highlight the impact of our method components across benchmarks, VLMs, and reasoning types.
Aligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
COLUMBUS: Evaluating COgnitive Lateral Understanding through Multiple-choice reBUSes
Sep 06, 2024



While visual question-answering (VQA) benchmarks have catalyzed the development of reasoning techniques, they have focused on vertical thinking. Effective problem-solving also necessitates lateral thinking, which remains understudied in AI and has not been used to test visual perception systems. To bridge this gap, we formulate visual lateral thinking as a multiple-choice question-answering task and describe a three-step taxonomy-driven methodology for instantiating task examples. Then, we develop COLUMBUS, a synthetic benchmark that applies the task pipeline to create QA sets with text and icon rebus puzzles based on publicly available collections of compounds and common phrases. COLUMBUS comprises over 1,000 puzzles, each with four answer candidates. While the SotA vision-language models (VLMs) achieve decent performance, our evaluation demonstrates a substantial gap between humans and models. VLMs benefit from human-curated descriptions but struggle to self-generate such representations at the right level of abstraction.
MARVEL: Multidimensional Abstraction and Reasoning through Visual Evaluation and Learning
Apr 24, 2024



While multi-modal large language models (MLLMs) have shown significant progress on many popular visual reasoning benchmarks, whether they possess abstract visual reasoning abilities remains an open question. Similar to the Sudoku puzzles, abstract visual reasoning (AVR) problems require finding high-level patterns (e.g., repetition constraints) that control the input shapes (e.g., digits) in a specific task configuration (e.g., matrix). However, existing AVR benchmarks only considered a limited set of patterns (addition, conjunction), input shapes (rectangle, square), and task configurations (3 by 3 matrices). To evaluate MLLMs' reasoning abilities comprehensively, we introduce MARVEL, a multidimensional AVR benchmark with 770 puzzles composed of six core knowledge patterns, geometric and abstract shapes, and five different task configurations. To inspect whether the model accuracy is grounded in perception and reasoning, MARVEL complements the general AVR question with perception questions in a hierarchical evaluation framework. We conduct comprehensive experiments on MARVEL with nine representative MLLMs in zero-shot and few-shot settings. Our experiments reveal that all models show near-random performance on the AVR question, with significant performance gaps (40%) compared to humans across all patterns and task configurations. Further analysis of perception questions reveals that MLLMs struggle to comprehend the visual features (near-random performance) and even count the panels in the puzzle ( <45%), hindering their ability for abstract reasoning. We release our entire code and dataset.