 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
Enhancing Video Large Language Models with Structured Multi-Video Collaborative Reasoning (early version)
Sep 16, 2025Despite the prosperity of the video language model, the current pursuit of comprehensive video reasoning is thwarted by the inherent spatio-temporal incompleteness within individual videos, resulting in hallucinations and inaccuracies. A promising solution is to augment the reasoning performance with multiple related videos. However, video tokens are numerous and contain redundant information, so directly feeding the relevant video data into a large language model to enhance responses could be counterproductive. To address this challenge, we propose a multi-video collaborative framework for video language models. For efficient and flexible video representation, we establish a Video Structuring Module to represent the video's knowledge as a spatio-temporal graph. Based on the structured video representation, we design the Graph Fusion Module to fuse the structured knowledge and valuable information from related videos into the augmented graph node tokens. Finally, we construct an elaborate multi-video structured prompt to integrate the graph, visual, and textual tokens as the input to the large language model. Extensive experiments substantiate the effectiveness of our framework, showcasing its potential as a promising avenue for advancing video language models.
CogStream: Context-guided Streaming Video Question Answering
Jun 12, 2025



Despite advancements in Video Large Language Models (Vid-LLMs) improving multimodal understanding, challenges persist in streaming video reasoning due to its reliance on contextual information. Existing paradigms feed all available historical contextual information into Vid-LLMs, resulting in a significant computational burden for visual data processing. Furthermore, the inclusion of irrelevant context distracts models from key details. This paper introduces a challenging task called Context-guided Streaming Video Reasoning (CogStream), which simulates real-world streaming video scenarios, requiring models to identify the most relevant historical contextual information to deduce answers for questions about the current stream. To support CogStream, we present a densely annotated dataset featuring extensive and hierarchical question-answer pairs, generated by a semi-automatic pipeline. Additionally, we present CogReasoner as a baseline model. It efficiently tackles this task by leveraging visual stream compression and historical dialogue retrieval. Extensive experiments prove the effectiveness of this method. Code will be released soon.
Looking Beyond Visible Cues: Implicit Video Question Answering via Dual-Clue Reasoning
Jun 09, 2025



Video Question Answering (VideoQA) aims to answer natural language questions based on the given video, with prior work primarily focusing on identifying the duration of relevant segments, referred to as explicit visual evidence. However, explicit visual evidence is not always directly available, particularly when questions target symbolic meanings or deeper intentions, leading to significant performance degradation. To fill this gap, we introduce a novel task and dataset, $\textbf{I}$mplicit $\textbf{V}$ideo $\textbf{Q}$uestion $\textbf{A}$nswering (I-VQA), which focuses on answering questions in scenarios where explicit visual evidence is inaccessible. Given an implicit question and its corresponding video, I-VQA requires answering based on the contextual visual cues present within the video. To tackle I-VQA, we propose a novel reasoning framework, IRM (Implicit Reasoning Model), incorporating dual-stream modeling of contextual actions and intent clues as implicit reasoning chains. IRM comprises the Action-Intent Module (AIM) and the Visual Enhancement Module (VEM). AIM deduces and preserves question-related dual clues by generating clue candidates and performing relation deduction. VEM enhances contextual visual representation by leveraging key contextual clues. Extensive experiments validate the effectiveness of our IRM in I-VQA tasks, outperforming GPT-4o, OpenAI-o3, and fine-tuned VideoChat2 by $0.76\%$, $1.37\%$, and $4.87\%$, respectively. Additionally, IRM performs SOTA on similar implicit advertisement understanding and future prediction in traffic-VQA. Datasets and codes are available for double-blind review in anonymous repo: https://github.com/tychen-SJTU/Implicit-VideoQA.
MECD+: Unlocking Event-Level Causal Graph Discovery for Video Reasoning
Jan 16, 2025



Video causal reasoning aims to achieve a high-level understanding of videos from a causal perspective. However, it exhibits limitations in its scope, primarily executed in a question-answering paradigm and focusing on brief video segments containing isolated events and basic causal relations, lacking comprehensive and structured causality analysis for videos with multiple interconnected events. To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD). It aims to uncover the causal relations between events distributed chronologically across long videos. Given visual segments and textual descriptions of events, MECD identifies the causal associations between these events to derive a comprehensive and structured event-level video causal graph explaining why and how the result event occurred. To address the challenges of MECD, we devise a novel framework inspired by the Granger Causality method, incorporating an efficient mask-based event prediction model to perform an Event Granger Test. It estimates causality by comparing the predicted result event when premise events are masked versus unmasked. Furthermore, we integrate causal inference techniques such as front-door adjustment and counterfactual inference to mitigate challenges in MECD like causality confounding and illusory causality. Additionally, context chain reasoning is introduced to conduct more robust and generalized reasoning. Experiments validate the effectiveness of our framework in reasoning complete causal relations, outperforming GPT-4o and VideoChat2 by 5.77% and 2.70%, respectively. Further experiments demonstrate that causal relation graphs can also contribute to downstream video understanding tasks such as video question answering and video event prediction.
CSTA: Spatial-Temporal Causal Adaptive Learning for Exemplar-Free Video Class-Incremental Learning
Jan 13, 2025



Continual learning aims to acquire new knowledge while retaining past information. Class-incremental learning (CIL) presents a challenging scenario where classes are introduced sequentially. For video data, the task becomes more complex than image data because it requires learning and preserving both spatial appearance and temporal action involvement. To address this challenge, we propose a novel exemplar-free framework that equips separate spatiotemporal adapters to learn new class patterns, accommodating the incremental information representation requirements unique to each class. While separate adapters are proven to mitigate forgetting and fit unique requirements, naively applying them hinders the intrinsic connection between spatial and temporal information increments, affecting the efficiency of representing newly learned class information. Motivated by this, we introduce two key innovations from a causal perspective. First, a causal distillation module is devised to maintain the relation between spatial-temporal knowledge for a more efficient representation. Second, a causal compensation mechanism is proposed to reduce the conflicts during increment and memorization between different types of information. Extensive experiments conducted on benchmark datasets demonstrate that our framework can achieve new state-of-the-art results, surpassing current example-based methods by 4.2% in accuracy on average.
Commonsense Video Question Answering through Video-Grounded Entailment Tree Reasoning
Jan 09, 2025



This paper proposes the first video-grounded entailment tree reasoning method for commonsense video question answering (VQA). Despite the remarkable progress of large visual-language models (VLMs), there are growing concerns that they learn spurious correlations between videos and likely answers, reinforced by their black-box nature and remaining benchmarking biases. Our method explicitly grounds VQA tasks to video fragments in four steps: entailment tree construction, video-language entailment verification, tree reasoning, and dynamic tree expansion. A vital benefit of the method is its generalizability to current video and image-based VLMs across reasoning types. To support fair evaluation, we devise a de-biasing procedure based on large-language models that rewrites VQA benchmark answer sets to enforce model reasoning. Systematic experiments on existing and de-biased benchmarks highlight the impact of our method components across benchmarks, VLMs, and reasoning types.
MECD: Unlocking Multi-Event Causal Discovery in Video Reasoning
Sep 26, 2024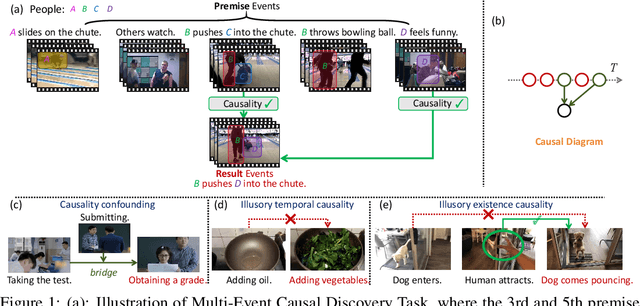
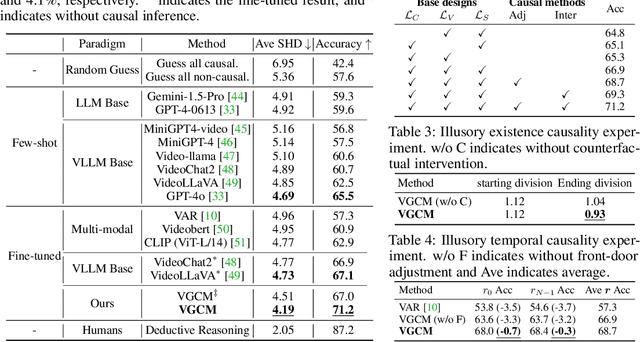
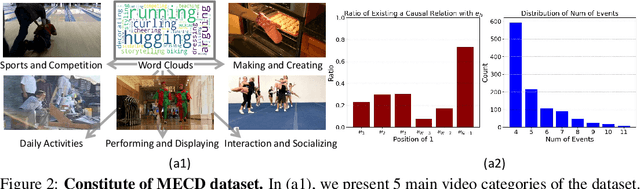
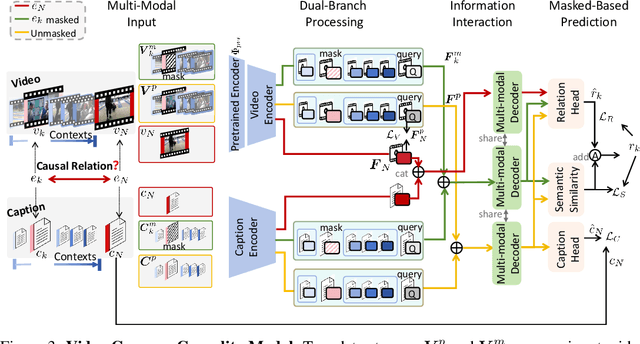
Video causal reasoning aims to achieve a high-level understanding of video content from a causal perspective. However, current video reasoning tasks are limited in scope, primarily executed in a question-answering paradigm and focusing on short videos containing only a single event and simple causal relationships, lacking comprehensive and structured causality analysis for videos with multiple events. To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD). It aims to uncover the causal relationships between events distributed chronologically across long videos. Given visual segments and textual descriptions of events, MECD requires identifying the causal associations between these events to derive a comprehensive, structured event-level video causal diagram explaining why and how the final result event occurred. To address MECD, we devise a novel framework inspired by the Granger Causality method, using an efficient mask-based event prediction model to perform an Event Granger Test, which estimates causality by comparing the predicted result event when premise events are masked versus unmasked. Furthermore, we integrate causal inference techniques such as front-door adjustment and counterfactual inference to address challenges in MECD like causality confounding and illusory causality. Experiments validate the effectiveness of our framework in providing causal relationships in multi-event videos, outperforming GPT-4o and VideoLLaVA by 5.7% and 4.1%, respectively.
DIBS: Enhancing Dense Video Captioning with Unlabeled Videos via Pseudo Boundary Enrichment and Online Refinement
Apr 03, 2024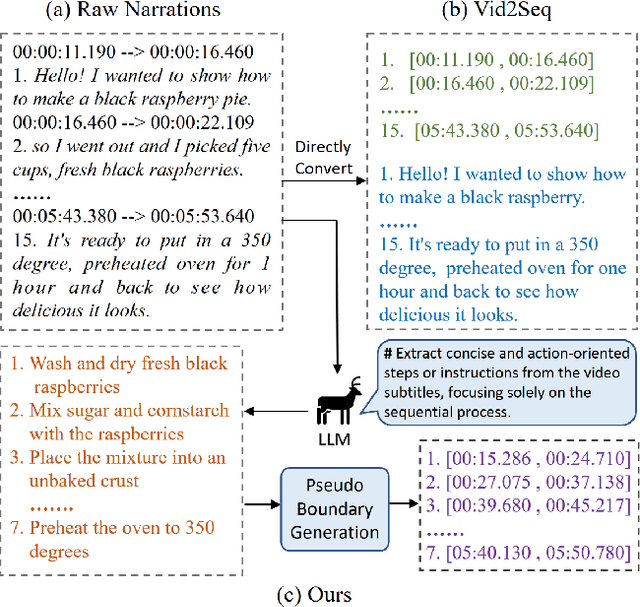

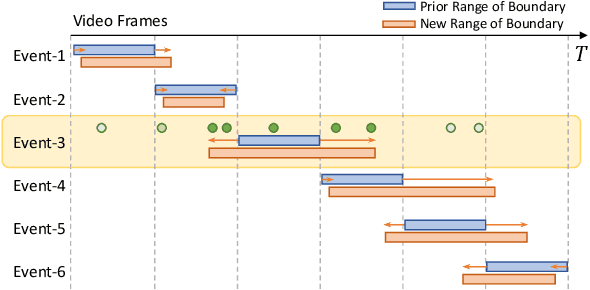
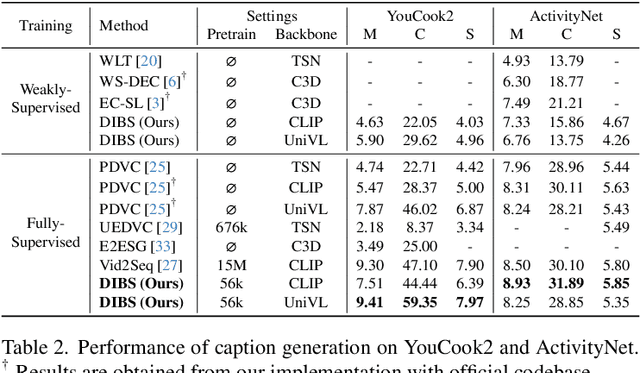
We present Dive Into the BoundarieS (DIBS), a novel pretraining framework for dense video captioning (DVC), that elaborates on improving the quality of the generated event captions and their associated pseudo event boundaries from unlabeled videos. By leveraging the capabilities of diverse large language models (LLMs), we generate rich DVC-oriented caption candidates and optimize the corresponding pseudo boundaries under several meticulously designed objectives, considering diversity, event-centricity, temporal ordering, and coherence. Moreover, we further introduce a novel online boundary refinement strategy that iteratively improves the quality of pseudo boundaries during training. Comprehensive experiments have been conducted to examine the effectiveness of the proposed technique components. By leveraging a substantial amount of unlabeled video data, such as HowTo100M, we achieve a remarkable advancement on standard DVC datasets like YouCook2 and ActivityNet. We outperform the previous state-of-the-art Vid2Seq across a majority of metrics, achieving this with just 0.4% of the unlabeled video data used for pre-training by Vid2Seq.
Collaborative Weakly Supervised Video Correlation Learning for Procedure-Aware Instructional Video Analysis
Dec 18, 2023



Video Correlation Learning (VCL), which aims to analyze the relationships between videos, has been widely studied and applied in various general video tasks. However, applying VCL to instructional videos is still quite challenging due to their intrinsic procedural temporal structure. Specifically, procedural knowledge is critical for accurate correlation analyses on instructional videos. Nevertheless, current procedure-learning methods heavily rely on step-level annotations, which are costly and not scalable. To address this problem, we introduce a weakly supervised framework called Collaborative Procedure Alignment (CPA) for procedure-aware correlation learning on instructional videos. Our framework comprises two core modules: collaborative step mining and frame-to-step alignment. The collaborative step mining module enables simultaneous and consistent step segmentation for paired videos, leveraging the semantic and temporal similarity between frames. Based on the identified steps, the frame-to-step alignment module performs alignment between the frames and steps across videos. The alignment result serves as a measurement of the correlation distance between two videos. We instantiate our framework in two distinct instructional video tasks: sequence verification and action quality assessment. Extensive experiments validate the effectiveness of our approach in providing accurate and interpretable correlation analyses for instructional videos.