 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMECD: Unlocking Multi-Event Causal Discovery in Video Reasoning
Sep 26, 2024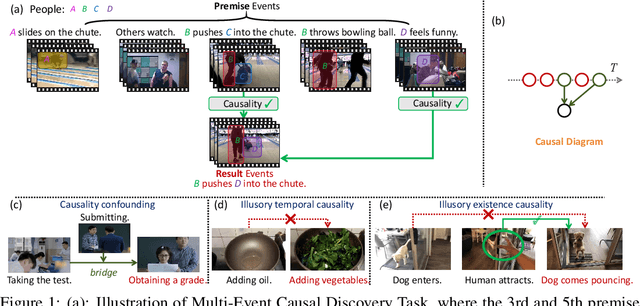
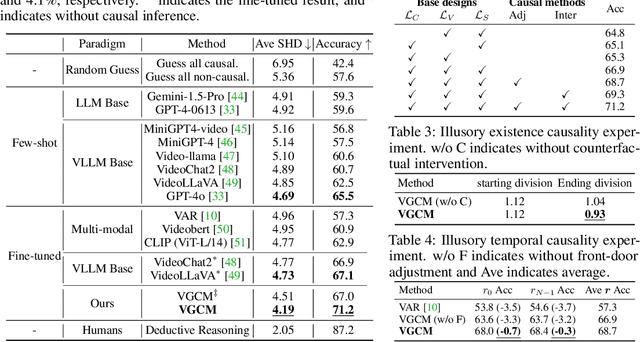
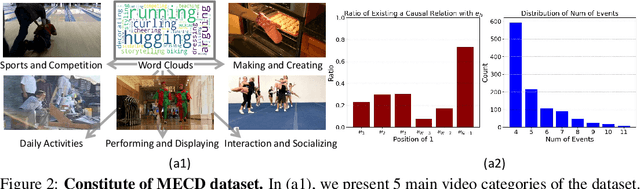
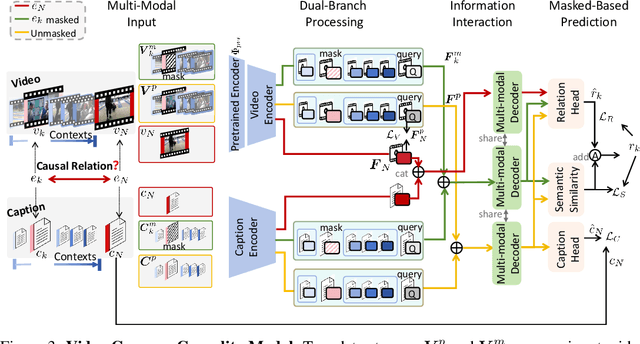
Video causal reasoning aims to achieve a high-level understanding of video content from a causal perspective. However, current video reasoning tasks are limited in scope, primarily executed in a question-answering paradigm and focusing on short videos containing only a single event and simple causal relationships, lacking comprehensive and structured causality analysis for videos with multiple events. To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD). It aims to uncover the causal relationships between events distributed chronologically across long videos. Given visual segments and textual descriptions of events, MECD requires identifying the causal associations between these events to derive a comprehensive, structured event-level video causal diagram explaining why and how the final result event occurred. To address MECD, we devise a novel framework inspired by the Granger Causality method, using an efficient mask-based event prediction model to perform an Event Granger Test, which estimates causality by comparing the predicted result event when premise events are masked versus unmasked. Furthermore, we integrate causal inference techniques such as front-door adjustment and counterfactual inference to address challenges in MECD like causality confounding and illusory causality. Experiments validate the effectiveness of our framework in providing causal relationships in multi-event videos, outperforming GPT-4o and VideoLLaVA by 5.7% and 4.1%, respectively.
Exploring spectro-temporal features in end-to-end convolutional neural networks
Jan 01, 2019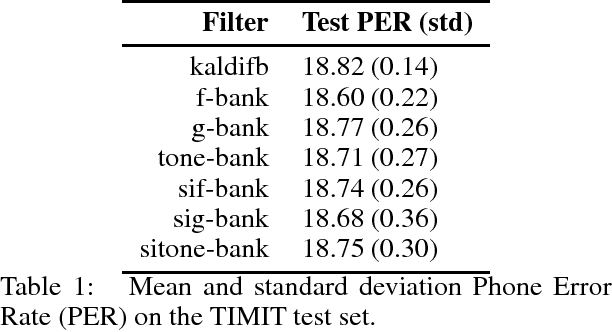
Triangular, overlapping Mel-scaled filters ("f-banks") are the current standard input for acoustic models that exploit their input's time-frequency geometry, because they provide a psycho-acoustically motivated time-frequency geometry for a speech signal. F-bank coefficients are provably robust to small deformations in the scale. In this paper, we explore two ways in which filter banks can be adjusted for the purposes of speech recognition. First, triangular filters can be replaced with Gabor filters, a compactly supported filter that better localizes events in time, or Gammatone filters, a psychoacoustically-motivated filter. Second, by rearranging the order of operations in computing filter bank features, features can be integrated over smaller time scales while simultaneously providing better frequency resolution. We make all feature implementations available online through open-source repositories. Initial experimentation with a modern end-to-end CNN phone recognizer yielded no significant improvements to phone error rate due to either modification. The result, and its ramifications with respect to learned filter banks, is discussed.