 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$λ$-GRPO: Unifying the GRPO Frameworks with Learnable Token Preferences
Oct 08, 2025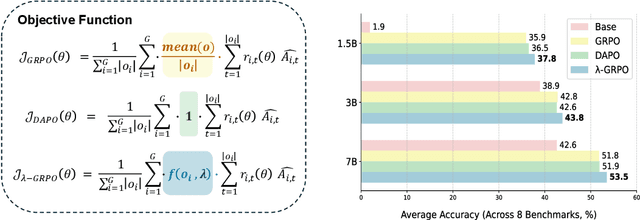
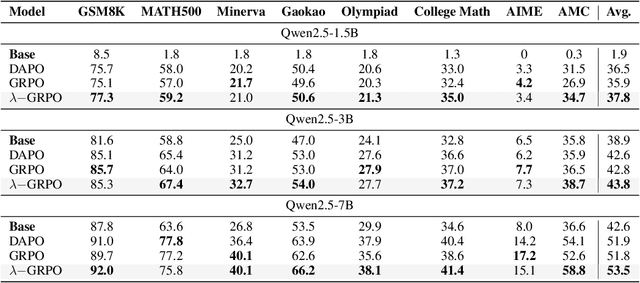
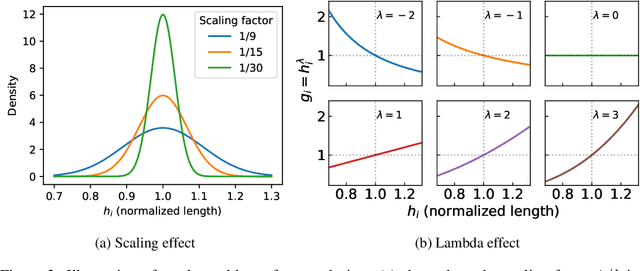

Reinforcement Learning with Human Feedback (RLHF) has been the dominant approach for improving the reasoning capabilities of Large Language Models (LLMs). Recently, Reinforcement Learning with Verifiable Rewards (RLVR) has simplified this paradigm by replacing the reward and value models with rule-based verifiers. A prominent example is Group Relative Policy Optimization (GRPO). However, GRPO inherently suffers from a length bias, since the same advantage is uniformly assigned to all tokens of a response. As a result, longer responses distribute the reward over more tokens and thus contribute disproportionately to gradient updates. Several variants, such as DAPO and Dr. GRPO, modify the token-level aggregation of the loss, yet these methods remain heuristic and offer limited interpretability regarding their implicit token preferences. In this work, we explore the possibility of allowing the model to learn its own token preference during optimization. We unify existing frameworks under a single formulation and introduce a learnable parameter $\lambda$ that adaptively controls token-level weighting. We use $\lambda$-GRPO to denote our method, and we find that $\lambda$-GRPO achieves consistent improvements over vanilla GRPO and DAPO on multiple mathematical reasoning benchmarks. On Qwen2.5 models with 1.5B, 3B, and 7B parameters, $\lambda$-GRPO improves average accuracy by $+1.9\%$, $+1.0\%$, and $+1.7\%$ compared to GRPO, respectively. Importantly, these gains come without any modifications to the training data or additional computational cost, highlighting the effectiveness and practicality of learning token preferences.
Quantifying the Role of Textual Predictability in Automatic Speech Recognition
Jul 23, 2024



A long-standing question in automatic speech recognition research is how to attribute errors to the ability of a model to model the acoustics, versus its ability to leverage higher-order context (lexicon, morphology, syntax, semantics). We validate a novel approach which models error rates as a function of relative textual predictability, and yields a single number, $k$, which measures the effect of textual predictability on the recognizer. We use this method to demonstrate that a Wav2Vec 2.0-based model makes greater stronger use of textual context than a hybrid ASR model, in spite of not using an explicit language model, and also use it to shed light on recent results demonstrating poor performance of standard ASR systems on African-American English. We demonstrate that these mostly represent failures of acoustic--phonetic modelling. We show how this approach can be used straightforwardly in diagnosing and improving ASR.
Functional Faithfulness in the Wild: Circuit Discovery with Differentiable Computation Graph Pruning
Jul 04, 2024In this paper, we introduce a comprehensive reformulation of the task known as Circuit Discovery, along with DiscoGP, a novel and effective algorithm based on differentiable masking for discovering circuits. Circuit discovery is the task of interpreting the computational mechanisms of language models (LMs) by dissecting their functions and capabilities into sparse subnetworks (circuits). We identified two major limitations in existing circuit discovery efforts: (1) a dichotomy between weight-based and connection-edge-based approaches forces researchers to choose between pruning connections or weights, thereby limiting the scope of mechanistic interpretation of LMs; (2) algorithms based on activation patching tend to identify circuits that are neither functionally faithful nor complete. The performance of these identified circuits is substantially reduced, often resulting in near-random performance in isolation. Furthermore, the complement of the circuit -- i.e., the original LM with the identified circuit removed -- still retains adequate performance, indicating that essential components of a complete circuits are missed by existing methods. DiscoGP successfully addresses the two aforementioned issues and demonstrates state-of-the-art faithfulness, completeness, and sparsity. The effectiveness of the algorithm and its novel structure open up new avenues of gathering new insights into the internal workings of generative AI.
What does the Knowledge Neuron Thesis Have to do with Knowledge?
May 03, 2024



We reassess the Knowledge Neuron (KN) Thesis: an interpretation of the mechanism underlying the ability of large language models to recall facts from a training corpus. This nascent thesis proposes that facts are recalled from the training corpus through the MLP weights in a manner resembling key-value memory, implying in effect that "knowledge" is stored in the network. Furthermore, by modifying the MLP modules, one can control the language model's generation of factual information. The plausibility of the KN thesis has been demonstrated by the success of KN-inspired model editing methods (Dai et al., 2022; Meng et al., 2022). We find that this thesis is, at best, an oversimplification. Not only have we found that we can edit the expression of certain linguistic phenomena using the same model editing methods but, through a more comprehensive evaluation, we have found that the KN thesis does not adequately explain the process of factual expression. While it is possible to argue that the MLP weights store complex patterns that are interpretable both syntactically and semantically, these patterns do not constitute "knowledge." To gain a more comprehensive understanding of the knowledge representation process, we must look beyond the MLP weights and explore recent models' complex layer structures and attention mechanisms.
Exploring spectro-temporal features in end-to-end convolutional neural networks
Jan 01, 2019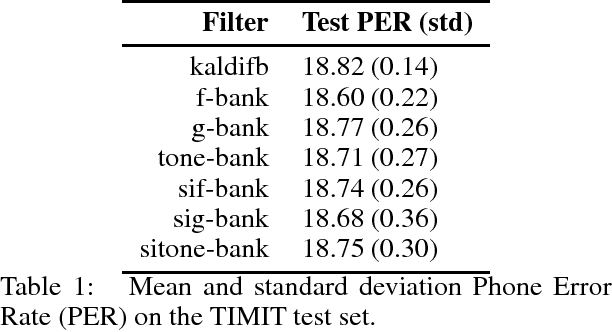
Triangular, overlapping Mel-scaled filters ("f-banks") are the current standard input for acoustic models that exploit their input's time-frequency geometry, because they provide a psycho-acoustically motivated time-frequency geometry for a speech signal. F-bank coefficients are provably robust to small deformations in the scale. In this paper, we explore two ways in which filter banks can be adjusted for the purposes of speech recognition. First, triangular filters can be replaced with Gabor filters, a compactly supported filter that better localizes events in time, or Gammatone filters, a psychoacoustically-motivated filter. Second, by rearranging the order of operations in computing filter bank features, features can be integrated over smaller time scales while simultaneously providing better frequency resolution. We make all feature implementations available online through open-source repositories. Initial experimentation with a modern end-to-end CNN phone recognizer yielded no significant improvements to phone error rate due to either modification. The result, and its ramifications with respect to learned filter banks, is discussed.
Applying Constraint Handling Rules to HPSG
Jul 07, 2000Constraint Handling Rules (CHR) have provided a realistic solution to an over-arching problem in many fields that deal with constraint logic programming: how to combine recursive functions or relations with constraints while avoiding non-termination problems. This paper focuses on some other benefits that CHR, specifically their implementation in SICStus Prolog, have provided to computational linguists working on grammar design tools. CHR rules are applied by means of a subsumption check and this check is made only when their variables are instantiated or bound. The former functionality is at best difficult to simulate using more primitive coroutining statements such as SICStus when/2, and the latter simply did not exist in any form before CHR. For the sake of providing a case study in how these can be applied to grammar development, we consider the Attribute Logic Engine (ALE), a Prolog preprocessor for logic programming with typed feature structures, and its extension to a complete grammar development system for Head-driven Phrase Structure Grammar (HPSG), a popular constraint-based linguistic theory that uses typed feature structures. In this context, CHR can be used not only to extend the constraint language of feature structure descriptions to include relations in a declarative way, but also to provide support for constraints with complex antecedents and constraints on the co-occurrence of feature values that are necessary to interpret the type system of HPSG properly.