 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring spectro-temporal features in end-to-end convolutional neural networks
Paper and Code
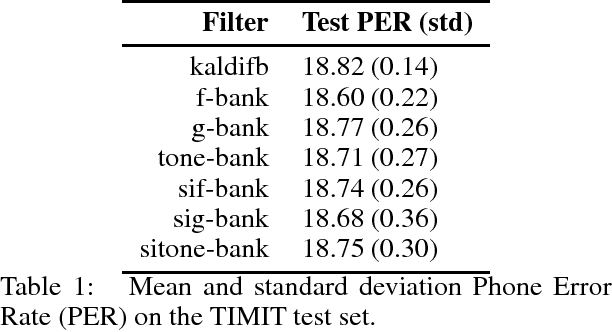
Triangular, overlapping Mel-scaled filters ("f-banks") are the current standard input for acoustic models that exploit their input's time-frequency geometry, because they provide a psycho-acoustically motivated time-frequency geometry for a speech signal. F-bank coefficients are provably robust to small deformations in the scale. In this paper, we explore two ways in which filter banks can be adjusted for the purposes of speech recognition. First, triangular filters can be replaced with Gabor filters, a compactly supported filter that better localizes events in time, or Gammatone filters, a psychoacoustically-motivated filter. Second, by rearranging the order of operations in computing filter bank features, features can be integrated over smaller time scales while simultaneously providing better frequency resolution. We make all feature implementations available online through open-source repositories. Initial experimentation with a modern end-to-end CNN phone recognizer yielded no significant improvements to phone error rate due to either modification. The result, and its ramifications with respect to learned filter banks, is discussed.