 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidLaDA: Bidirectional Diffusion Large Language Models for Efficient Video Understanding
Jan 25, 2026Standard Autoregressive Video LLMs inevitably suffer from causal masking biases that hinder global spatiotemporal modeling, leading to suboptimal understanding efficiency. We propose VidLaDA, a Video LLM based on Diffusion Language Model utilizing bidirectional attention to capture bidirectional dependencies. To further tackle the inference bottleneck of diffusion decoding on massive video tokens, we introduce MARS-Cache. This framework accelerates inference by combining asynchronous visual cache refreshing with frame-wise chunk attention, effectively pruning redundancy while preserving global connectivity via anchor tokens. Extensive experiments show VidLaDA outperforms diffusion baselines and rivals state-of-the-art autoregressive models (e.g., Qwen2.5-VL and LLaVA-Video), with MARS-Cache delivering over 12x speedup without compromising reasoning accuracy. Code and checkpoints are open-sourced at https://github.com/ziHoHe/VidLaDA.
Enhancing Video Large Language Models with Structured Multi-Video Collaborative Reasoning (early version)
Sep 16, 2025Despite the prosperity of the video language model, the current pursuit of comprehensive video reasoning is thwarted by the inherent spatio-temporal incompleteness within individual videos, resulting in hallucinations and inaccuracies. A promising solution is to augment the reasoning performance with multiple related videos. However, video tokens are numerous and contain redundant information, so directly feeding the relevant video data into a large language model to enhance responses could be counterproductive. To address this challenge, we propose a multi-video collaborative framework for video language models. For efficient and flexible video representation, we establish a Video Structuring Module to represent the video's knowledge as a spatio-temporal graph. Based on the structured video representation, we design the Graph Fusion Module to fuse the structured knowledge and valuable information from related videos into the augmented graph node tokens. Finally, we construct an elaborate multi-video structured prompt to integrate the graph, visual, and textual tokens as the input to the large language model. Extensive experiments substantiate the effectiveness of our framework, showcasing its potential as a promising avenue for advancing video language models.
Grove MoE: Towards Efficient and Superior MoE LLMs with Adjugate Experts
Aug 11, 2025The Mixture of Experts (MoE) architecture is a cornerstone of modern state-of-the-art (SOTA) large language models (LLMs). MoE models facilitate scalability by enabling sparse parameter activation. However, traditional MoE architecture uses homogeneous experts of a uniform size, activating a fixed number of parameters irrespective of input complexity and thus limiting computational efficiency. To overcome this limitation, we introduce Grove MoE, a novel architecture incorporating experts of varying sizes, inspired by the heterogeneous big.LITTLE CPU architecture. This architecture features novel adjugate experts with a dynamic activation mechanism, enabling model capacity expansion while maintaining manageable computational overhead. Building on this architecture, we present GroveMoE-Base and GroveMoE-Inst, 33B-parameter LLMs developed by applying an upcycling strategy to the Qwen3-30B-A3B-Base model during mid-training and post-training. GroveMoE models dynamically activate 3.14-3.28B parameters based on token complexity and achieve performance comparable to SOTA open-source models of similar or even larger size.
Looking Beyond Visible Cues: Implicit Video Question Answering via Dual-Clue Reasoning
Jun 09, 2025



Video Question Answering (VideoQA) aims to answer natural language questions based on the given video, with prior work primarily focusing on identifying the duration of relevant segments, referred to as explicit visual evidence. However, explicit visual evidence is not always directly available, particularly when questions target symbolic meanings or deeper intentions, leading to significant performance degradation. To fill this gap, we introduce a novel task and dataset, $\textbf{I}$mplicit $\textbf{V}$ideo $\textbf{Q}$uestion $\textbf{A}$nswering (I-VQA), which focuses on answering questions in scenarios where explicit visual evidence is inaccessible. Given an implicit question and its corresponding video, I-VQA requires answering based on the contextual visual cues present within the video. To tackle I-VQA, we propose a novel reasoning framework, IRM (Implicit Reasoning Model), incorporating dual-stream modeling of contextual actions and intent clues as implicit reasoning chains. IRM comprises the Action-Intent Module (AIM) and the Visual Enhancement Module (VEM). AIM deduces and preserves question-related dual clues by generating clue candidates and performing relation deduction. VEM enhances contextual visual representation by leveraging key contextual clues. Extensive experiments validate the effectiveness of our IRM in I-VQA tasks, outperforming GPT-4o, OpenAI-o3, and fine-tuned VideoChat2 by $0.76\%$, $1.37\%$, and $4.87\%$, respectively. Additionally, IRM performs SOTA on similar implicit advertisement understanding and future prediction in traffic-VQA. Datasets and codes are available for double-blind review in anonymous repo: https://github.com/tychen-SJTU/Implicit-VideoQA.
Unleashing Diffusion Transformers for Visual Correspondence by Modulating Massive Activations
May 24, 2025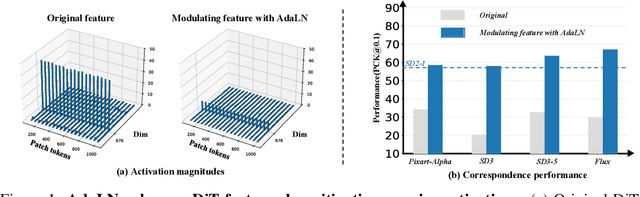
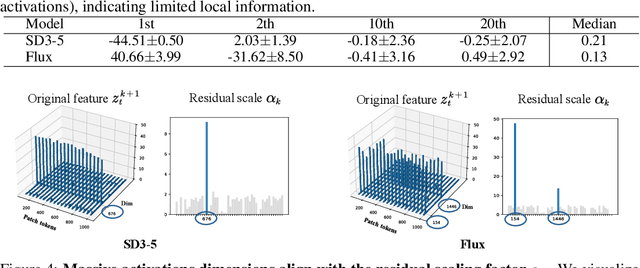
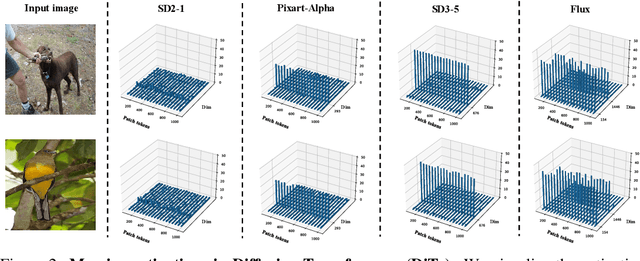
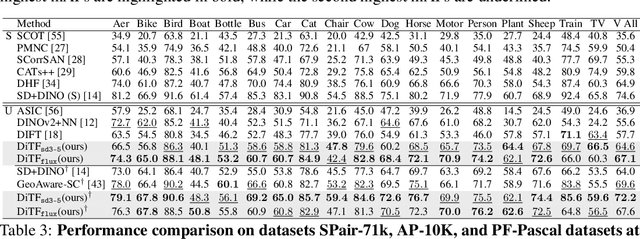
Pre-trained stable diffusion models (SD) have shown great advances in visual correspondence. In this paper, we investigate the capabilities of Diffusion Transformers (DiTs) for accurate dense correspondence. Distinct from SD, DiTs exhibit a critical phenomenon in which very few feature activations exhibit significantly larger values than others, known as \textit{massive activations}, leading to uninformative representations and significant performance degradation for DiTs. The massive activations consistently concentrate at very few fixed dimensions across all image patch tokens, holding little local information. We trace these dimension-concentrated massive activations and find that such concentration can be effectively localized by the zero-initialized Adaptive Layer Norm (AdaLN-zero). Building on these findings, we propose Diffusion Transformer Feature (DiTF), a training-free framework designed to extract semantic-discriminative features from DiTs. Specifically, DiTF employs AdaLN to adaptively localize and normalize massive activations with channel-wise modulation. In addition, we develop a channel discard strategy to further eliminate the negative impacts from massive activations. Experimental results demonstrate that our DiTF outperforms both DINO and SD-based models and establishes a new state-of-the-art performance for DiTs in different visual correspondence tasks (\eg, with +9.4\% on Spair-71k and +4.4\% on AP-10K-C.S.).
Contrastive Representation Distillation via Multi-Scale Feature Decoupling
Feb 09, 2025



Knowledge distillation is a technique aimed at enhancing the performance of a smaller student network without increasing its parameter size by transferring knowledge from a larger, pre-trained teacher network. Previous approaches have predominantly focused on distilling global feature information while overlooking the importance of disentangling the diverse types of information embedded within different regions of the feature. In this work, we introduce multi-scale decoupling in the feature transfer process for the first time, where the decoupled local features are individually processed and integrated with contrastive learning. Moreover, compared to previous contrastive learning-based distillation methods, our approach not only reduces computational costs but also enhances efficiency, enabling performance improvements for the student network using only single-batch samples. Extensive evaluations on CIFAR-100 and ImageNet demonstrate our method's superiority, with some student networks distilled using our method even surpassing the performance of their pre-trained teacher networks. These results underscore the effectiveness of our approach in enabling student networks to thoroughly absorb knowledge from teacher networks.
MECD+: Unlocking Event-Level Causal Graph Discovery for Video Reasoning
Jan 16, 2025



Video causal reasoning aims to achieve a high-level understanding of videos from a causal perspective. However, it exhibits limitations in its scope, primarily executed in a question-answering paradigm and focusing on brief video segments containing isolated events and basic causal relations, lacking comprehensive and structured causality analysis for videos with multiple interconnected events. To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD). It aims to uncover the causal relations between events distributed chronologically across long videos. Given visual segments and textual descriptions of events, MECD identifies the causal associations between these events to derive a comprehensive and structured event-level video causal graph explaining why and how the result event occurred. To address the challenges of MECD, we devise a novel framework inspired by the Granger Causality method, incorporating an efficient mask-based event prediction model to perform an Event Granger Test. It estimates causality by comparing the predicted result event when premise events are masked versus unmasked. Furthermore, we integrate causal inference techniques such as front-door adjustment and counterfactual inference to mitigate challenges in MECD like causality confounding and illusory causality. Additionally, context chain reasoning is introduced to conduct more robust and generalized reasoning. Experiments validate the effectiveness of our framework in reasoning complete causal relations, outperforming GPT-4o and VideoChat2 by 5.77% and 2.70%, respectively. Further experiments demonstrate that causal relation graphs can also contribute to downstream video understanding tasks such as video question answering and video event prediction.
CSTA: Spatial-Temporal Causal Adaptive Learning for Exemplar-Free Video Class-Incremental Learning
Jan 13, 2025



Continual learning aims to acquire new knowledge while retaining past information. Class-incremental learning (CIL) presents a challenging scenario where classes are introduced sequentially. For video data, the task becomes more complex than image data because it requires learning and preserving both spatial appearance and temporal action involvement. To address this challenge, we propose a novel exemplar-free framework that equips separate spatiotemporal adapters to learn new class patterns, accommodating the incremental information representation requirements unique to each class. While separate adapters are proven to mitigate forgetting and fit unique requirements, naively applying them hinders the intrinsic connection between spatial and temporal information increments, affecting the efficiency of representing newly learned class information. Motivated by this, we introduce two key innovations from a causal perspective. First, a causal distillation module is devised to maintain the relation between spatial-temporal knowledge for a more efficient representation. Second, a causal compensation mechanism is proposed to reduce the conflicts during increment and memorization between different types of information. Extensive experiments conducted on benchmark datasets demonstrate that our framework can achieve new state-of-the-art results, surpassing current example-based methods by 4.2% in accuracy on average.
MECD: Unlocking Multi-Event Causal Discovery in Video Reasoning
Sep 26, 2024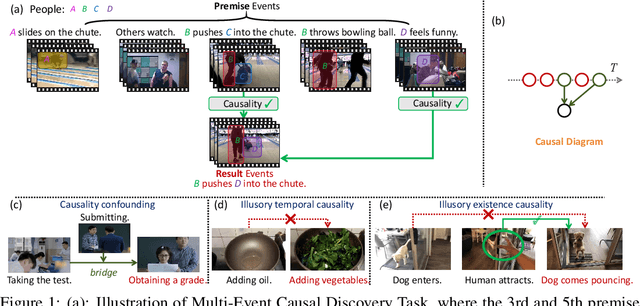
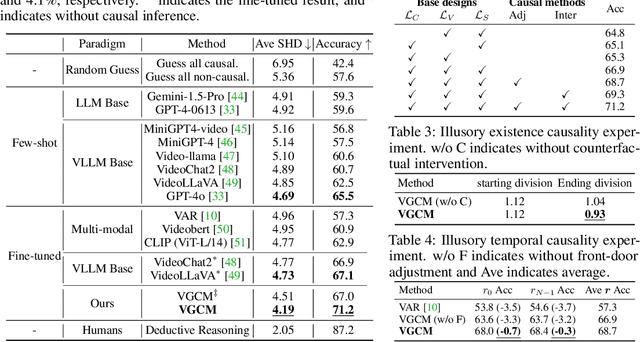
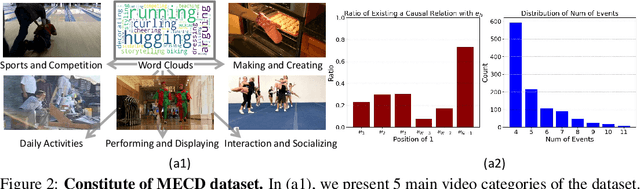
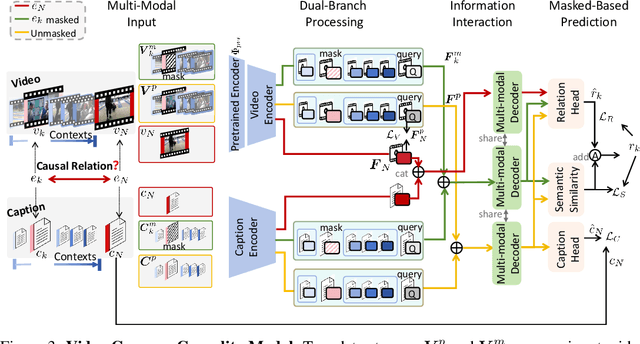
Video causal reasoning aims to achieve a high-level understanding of video content from a causal perspective. However, current video reasoning tasks are limited in scope, primarily executed in a question-answering paradigm and focusing on short videos containing only a single event and simple causal relationships, lacking comprehensive and structured causality analysis for videos with multiple events. To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD). It aims to uncover the causal relationships between events distributed chronologically across long videos. Given visual segments and textual descriptions of events, MECD requires identifying the causal associations between these events to derive a comprehensive, structured event-level video causal diagram explaining why and how the final result event occurred. To address MECD, we devise a novel framework inspired by the Granger Causality method, using an efficient mask-based event prediction model to perform an Event Granger Test, which estimates causality by comparing the predicted result event when premise events are masked versus unmasked. Furthermore, we integrate causal inference techniques such as front-door adjustment and counterfactual inference to address challenges in MECD like causality confounding and illusory causality. Experiments validate the effectiveness of our framework in providing causal relationships in multi-event videos, outperforming GPT-4o and VideoLLaVA by 5.7% and 4.1%, respectively.
Few-shot Action Recognition via Intra- and Inter-Video Information Maximization
May 10, 2023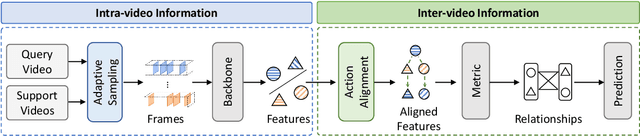
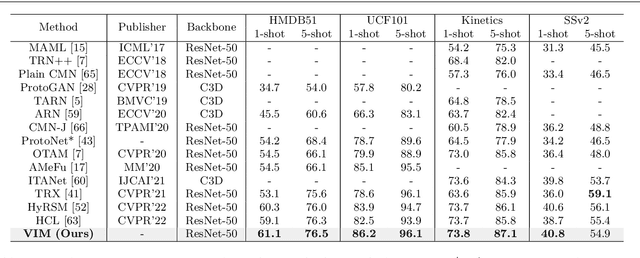

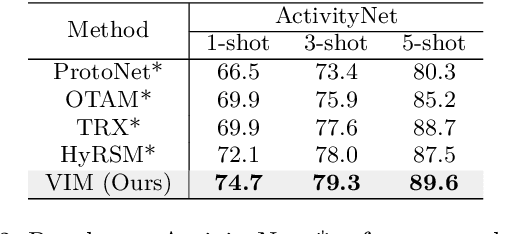
Current few-shot action recognition involves two primary sources of information for classification:(1) intra-video information, determined by frame content within a single video clip, and (2) inter-video information, measured by relationships (e.g., feature similarity) among videos. However, existing methods inadequately exploit these two information sources. In terms of intra-video information, current sampling operations for input videos may omit critical action information, reducing the utilization efficiency of video data. For the inter-video information, the action misalignment among videos makes it challenging to calculate precise relationships. Moreover, how to jointly consider both inter- and intra-video information remains under-explored for few-shot action recognition. To this end, we propose a novel framework, Video Information Maximization (VIM), for few-shot video action recognition. VIM is equipped with an adaptive spatial-temporal video sampler and a spatiotemporal action alignment model to maximize intra- and inter-video information, respectively. The video sampler adaptively selects important frames and amplifies critical spatial regions for each input video based on the task at hand. This preserves and emphasizes informative parts of video clips while eliminating interference at the data level. The alignment model performs temporal and spatial action alignment sequentially at the feature level, leading to more precise measurements of inter-video similarity. Finally, These goals are facilitated by incorporating additional loss terms based on mutual information measurement. Consequently, VIM acts to maximize the distinctiveness of video information from limited video data. Extensive experimental results on public datasets for few-shot action recognition demonstrate the effectiveness and benefits of our framework.