 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPTF-Net: Multi-view Pyramid Transformer Fusion Network for LiDAR-based Place Recognition
Apr 06, 2026LiDAR-based place recognition (LPR) is essential for global localization and loop-closure detection in large-scale SLAM systems. Existing methods typically construct global descriptors from Range Images or BEV representations for matching. BEV is widely adopted due to its explicit 2D spatial layout encoding and efficient retrieval. However, conventional BEV representations rely on simple statistical aggregation, which fails to capture fine-grained geometric structures, leading to performance degradation in complex or repetitive environments. To address this, we propose MPTF-Net, a novel multi-view multi-scale pyramid Transformer fusion network. Our core contribution is a multi-channel NDT-based BEV encoding that explicitly models local geometric complexity and intensity distributions via Normal Distribution Transform, providing a noise-resilient structural prior. To effectively integrate these features, we develop a customized pyramid Transformer module that captures cross-view interactive correlations between Range Image Views (RIV) and NDT-BEV at multiple spatial scales. Extensive experiments on the nuScenes, KITTI and NCLT datasets demonstrate that MPTF-Net achieves state-of-the-art performance, specifically attaining a Recall@1 of 96.31\% on the nuScenes Boston split while maintaining an inference latency of only 10.02 ms, making it highly suitable for real-time autonomous unmanned systems.
Few-shot Action Recognition via Intra- and Inter-Video Information Maximization
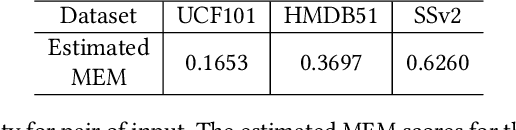
May 10, 2023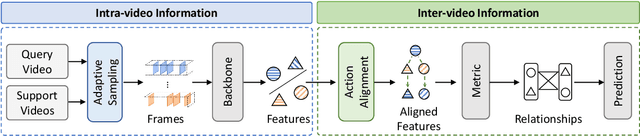
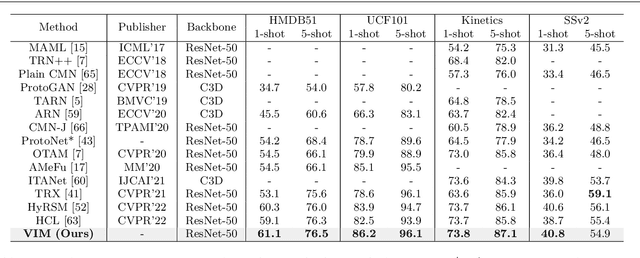

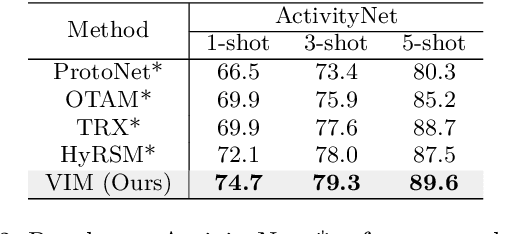
Current few-shot action recognition involves two primary sources of information for classification:(1) intra-video information, determined by frame content within a single video clip, and (2) inter-video information, measured by relationships (e.g., feature similarity) among videos. However, existing methods inadequately exploit these two information sources. In terms of intra-video information, current sampling operations for input videos may omit critical action information, reducing the utilization efficiency of video data. For the inter-video information, the action misalignment among videos makes it challenging to calculate precise relationships. Moreover, how to jointly consider both inter- and intra-video information remains under-explored for few-shot action recognition. To this end, we propose a novel framework, Video Information Maximization (VIM), for few-shot video action recognition. VIM is equipped with an adaptive spatial-temporal video sampler and a spatiotemporal action alignment model to maximize intra- and inter-video information, respectively. The video sampler adaptively selects important frames and amplifies critical spatial regions for each input video based on the task at hand. This preserves and emphasizes informative parts of video clips while eliminating interference at the data level. The alignment model performs temporal and spatial action alignment sequentially at the feature level, leading to more precise measurements of inter-video similarity. Finally, These goals are facilitated by incorporating additional loss terms based on mutual information measurement. Consequently, VIM acts to maximize the distinctiveness of video information from limited video data. Extensive experimental results on public datasets for few-shot action recognition demonstrate the effectiveness and benefits of our framework.
TTAN: Two-Stage Temporal Alignment Network for Few-shot Action Recognition
Jul 10, 2021
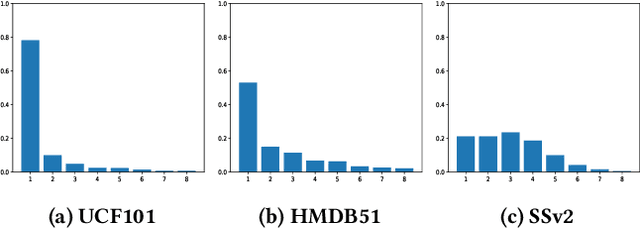
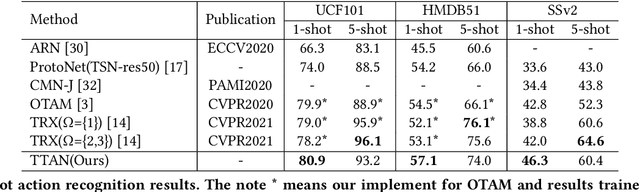
Few-shot action recognition aims to recognize novel action classes (query) using just a few samples (support). The majority of current approaches follow the metric learning paradigm, which learns to compare the similarity between videos. Recently, it has been observed that directly measuring this similarity is not ideal since different action instances may show distinctive temporal distribution, resulting in severe misalignment issues across query and support videos. In this paper, we arrest this problem from two distinct aspects -- action duration misalignment and motion evolution misalignment. We address them sequentially through a Two-stage Temporal Alignment Network (TTAN). The first stage performs temporal transformation with the predicted affine warp parameters, while the second stage utilizes a cross-attention mechanism to coordinate the features of the support and query to a consistent evolution. Besides, we devise a novel multi-shot fusion strategy, which takes the misalignment among support samples into consideration. Ablation studies and visualizations demonstrate the role played by both stages in addressing the misalignment. Extensive experiments on benchmark datasets show the potential of the proposed method in achieving state-of-the-art performance for few-shot action recognition.
Amur Tiger Re-identification in the Wild
Jun 14, 2019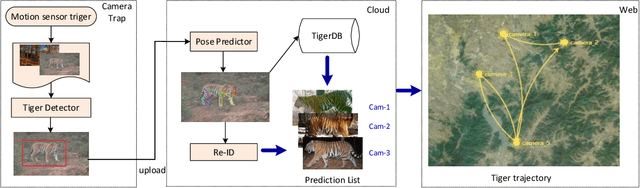

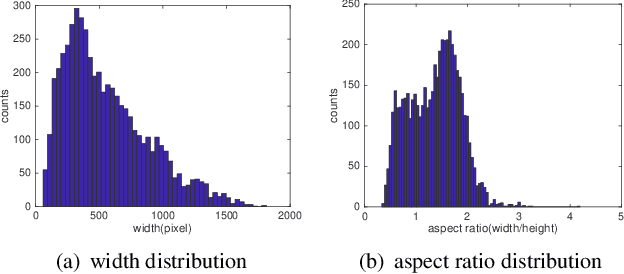
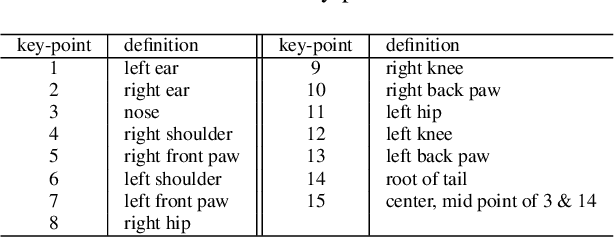
Monitoring the population and movements of endangered species is an important task to wildlife conversation. Traditional tagging methods do not scale to large populations, while applying computer vision methods to camera sensor data requires re-identification (re-ID) algorithms to obtain accurate counts and moving trajectory of wildlife. However, existing re-ID methods are largely targeted at persons and cars, which have limited pose variations and constrained capture environments. This paper tries to fill the gap by introducing a novel large-scale dataset, the Amur Tiger Re-identification in the Wild (ATRW) dataset. ATRW contains over 8,000 video clips from 92 Amur tigers, with bounding box, pose keypoint, and tiger identity annotations. In contrast to typical re-ID datasets, the tigers are captured in a diverse set of unconstrained poses and lighting conditions. We demonstrate with a set of baseline algorithms that ATRW is a challenging dataset for re-ID. Lastly, we propose a novel method for tiger re-identification, which introduces precise pose parts modeling in deep neural networks to handle large pose variation of tigers, and reaches notable performance improvement over existing re-ID methods. The dataset will be public available at https://cvwc2019.github.io/ .