 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Domain Adaptation and Generalization in the Era of CLIP
Jul 21, 2024



In recent studies on domain adaptation, significant emphasis has been placed on the advancement of learning shared knowledge from a source domain to a target domain. Recently, the large vision-language pre-trained model, i.e., CLIP has shown strong ability on zero-shot recognition, and parameter efficient tuning can further improve its performance on specific tasks. This work demonstrates that a simple domain prior boosts CLIP's zero-shot recognition in a specific domain. Besides, CLIP's adaptation relies less on source domain data due to its diverse pre-training dataset. Furthermore, we create a benchmark for zero-shot adaptation and pseudo-labeling based self-training with CLIP. Last but not least, we propose to improve the task generalization ability of CLIP from multiple unlabeled domains, which is a more practical and unique scenario. We believe our findings motivate a rethinking of domain adaptation benchmarks and the associated role of related algorithms in the era of CLIP.
Vision Pair Learning: An Efficient Training Framework for Image Classification
Dec 02, 2021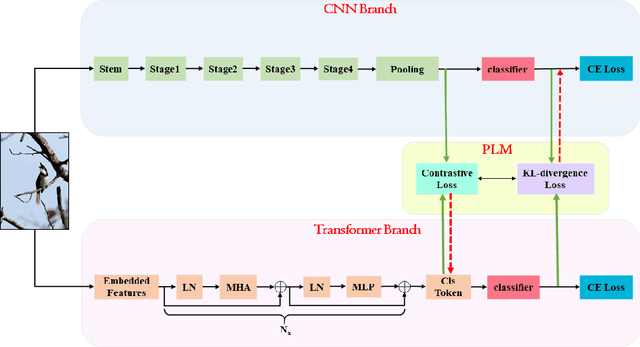
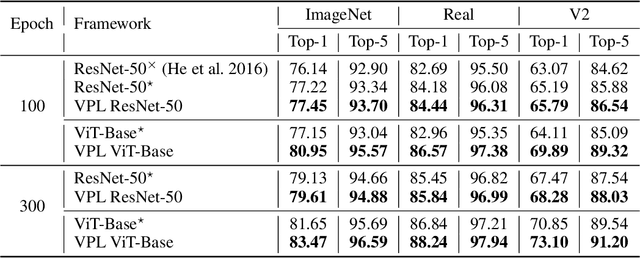
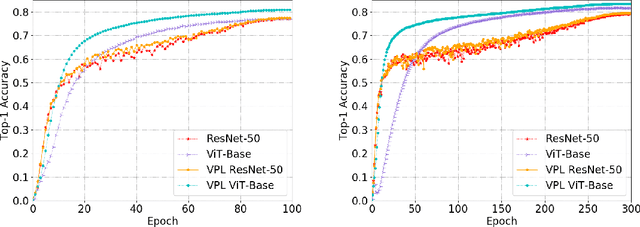
Transformer is a potentially powerful architecture for vision tasks. Although equipped with more parameters and attention mechanism, its performance is not as dominant as CNN currently. CNN is usually computationally cheaper and still the leading competitor in various vision tasks. One research direction is to adopt the successful ideas of CNN and improve transformer, but it often relies on elaborated and heuristic network design. Observing that transformer and CNN are complementary in representation learning and convergence speed, we propose an efficient training framework called Vision Pair Learning (VPL) for image classification task. VPL builds up a network composed of a transformer branch, a CNN branch and pair learning module. With multi-stage training strategy, VPL enables the branches to learn from their partners during the appropriate stage of the training process, and makes them both achieve better performance with less time cost. Without external data, VPL promotes the top-1 accuracy of ViT-Base and ResNet-50 on the ImageNet-1k validation set to 83.47% and 79.61% respectively. Experiments on other datasets of various domains prove the efficacy of VPL and suggest that transformer performs better when paired with the differently structured CNN in VPL. we also analyze the importance of components through ablation study.
Few-Shot Real Image Restoration via Distortion-Relation Guided Transfer Learning
Nov 25, 2021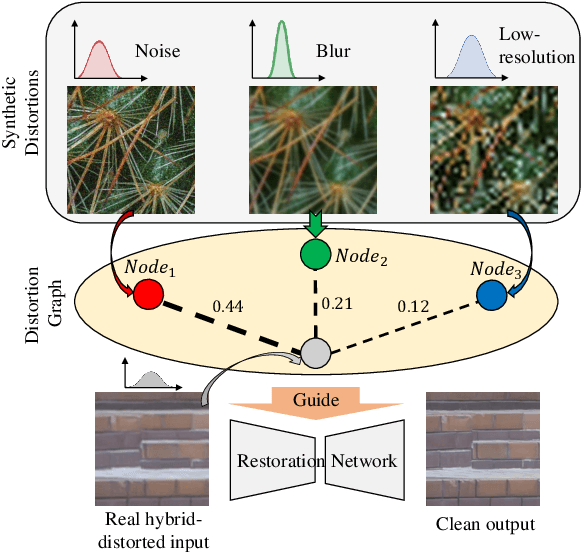

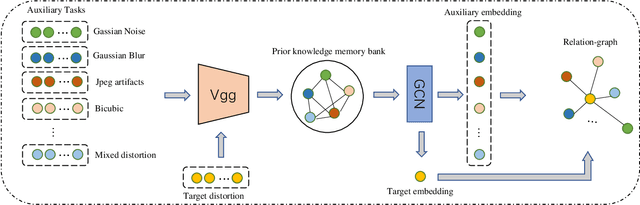
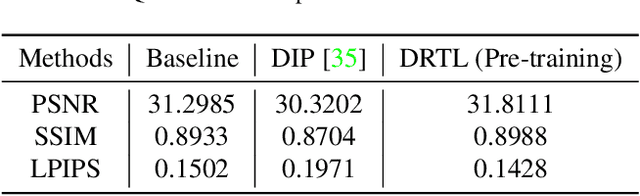
Collecting large clean-distorted training image pairs in real world is non-trivial, which seriously limits the practical applications of these supervised learning based image restoration (IR) methods. Previous works attempt to address this problem by leveraging unsupervised learning technologies to alleviate the dependency for paired training samples. However, these methods typically suffer from unsatisfactory textures synthesis due to the lack of clean image supervision. Compared with purely unsupervised solution, the under-explored scheme with Few-Shot clean images (FS-IR) is more feasible to tackle this challenging real Image Restoration task. In this paper, we are the first to investigate the few-shot real image restoration and propose a Distortion-Relation guided Transfer Learning (termed as DRTL) framework. DRTL assigns a knowledge graph to capture the distortion relation between auxiliary tasks (i.e., synthetic distortions) and target tasks (i.e., real distortions with few images), and then adopt a gradient weighting strategy to guide the knowledge transfer from auxiliary task to target task. In this way, DRTL could quickly learn the most relevant knowledge from the prior distortions for target distortion. We instantiate DRTL integrated with pre-training and meta-learning pipelines as an embodiment to realize a distortion-relation aware FS-IR. Extensive experiments on multiple benchmarks demonstrate the effectiveness of DRTL on few-shot real image restoration.
TTAN: Two-Stage Temporal Alignment Network for Few-shot Action Recognition
Jul 10, 2021
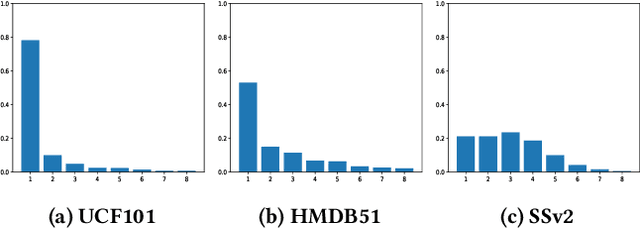
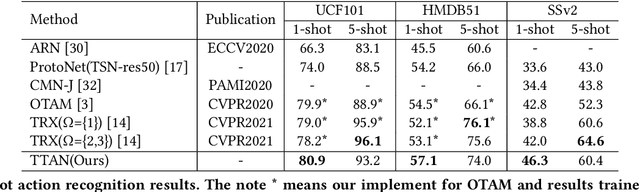
Few-shot action recognition aims to recognize novel action classes (query) using just a few samples (support). The majority of current approaches follow the metric learning paradigm, which learns to compare the similarity between videos. Recently, it has been observed that directly measuring this similarity is not ideal since different action instances may show distinctive temporal distribution, resulting in severe misalignment issues across query and support videos. In this paper, we arrest this problem from two distinct aspects -- action duration misalignment and motion evolution misalignment. We address them sequentially through a Two-stage Temporal Alignment Network (TTAN). The first stage performs temporal transformation with the predicted affine warp parameters, while the second stage utilizes a cross-attention mechanism to coordinate the features of the support and query to a consistent evolution. Besides, we devise a novel multi-shot fusion strategy, which takes the misalignment among support samples into consideration. Ablation studies and visualizations demonstrate the role played by both stages in addressing the misalignment. Extensive experiments on benchmark datasets show the potential of the proposed method in achieving state-of-the-art performance for few-shot action recognition.