 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Mode Pneumatic Artificial Muscles Driven by Hybrid Positive-Negative Pressure
Mar 16, 2026Artificial muscles embody human aspirations for engineering lifelike robotic movements. This paper introduces an architecture for Inflatable Fluid-Driven Origami-Inspired Artificial Muscles (IN-FOAMs). A typical IN-FOAM consists of an inflatable skeleton enclosed within an outer skin, which can be driven using a combination of positive and negative pressures (e.g., compressed air and vacuum). IN-FOAMs are manufactured using low-cost heat-sealable sheet materials through heat-pressing and heat-sealing processes. Thus, they can be ultra-thin when not actuated, making them flexible, lightweight, and portable. The skeleton patterns are programmable, enabling a variety of motions, including contracting, bending, twisting, and rotating, based on specific skeleton designs. We conducted comprehensive experimental, theoretical, and numerical studies to investigate IN-FOAM's basic mechanical behavior and properties. The results show that IN-FOAM's output force and contraction can be tuned through multiple operation modes with the applied hybrid positive-negative pressure. Additionally, we propose multilayer skeleton structures to enhance the contraction ratio further, and we demonstrate a multi-channel skeleton approach that allows the integration of multiple motion modes into a single IN-FOAM. These findings indicate that IN-FOAMs hold great potential for future applications in flexible wearable devices and compact soft robotic systems.
* 20 pages, 17 figures. Published in IEEE Transactions on Robotics
GlobalPaint: Spatiotemporal Coherent Video Outpainting with Global Feature Guidance
Jan 10, 2026Video outpainting extends a video beyond its original boundaries by synthesizing missing border content. Compared with image outpainting, it requires not only per-frame spatial plausibility but also long-range temporal coherence, especially when outpainted content becomes visible across time under camera or object motion. We propose GlobalPaint, a diffusion-based framework for spatiotemporal coherent video outpainting. Our approach adopts a hierarchical pipeline that first outpaints key frames and then completes intermediate frames via an interpolation model conditioned on the completed boundaries, reducing error accumulation in sequential processing. At the model level, we augment a pretrained image inpainting backbone with (i) an Enhanced Spatial-Temporal module featuring 3D windowed attention for stronger spatiotemporal interaction, and (ii) global feature guidance that distills OpenCLIP features from observed regions across all frames into compact global tokens using a dedicated extractor. Comprehensive evaluations on benchmark datasets demonstrate improved reconstruction quality and more natural motion compared to prior methods. Our demo page is https://yuemingpan.github.io/GlobalPaint/
ContentV: Efficient Training of Video Generation Models with Limited Compute
Jun 05, 2025Recent advances in video generation demand increasingly efficient training recipes to mitigate escalating computational costs. In this report, we present ContentV, an 8B-parameter text-to-video model that achieves state-of-the-art performance (85.14 on VBench) after training on 256 x 64GB Neural Processing Units (NPUs) for merely four weeks. ContentV generates diverse, high-quality videos across multiple resolutions and durations from text prompts, enabled by three key innovations: (1) A minimalist architecture that maximizes reuse of pre-trained image generation models for video generation; (2) A systematic multi-stage training strategy leveraging flow matching for enhanced efficiency; and (3) A cost-effective reinforcement learning with human feedback framework that improves generation quality without requiring additional human annotations. All the code and models are available at: https://contentv.github.io.
Rethinking Domain Adaptation and Generalization in the Era of CLIP
Jul 21, 2024



In recent studies on domain adaptation, significant emphasis has been placed on the advancement of learning shared knowledge from a source domain to a target domain. Recently, the large vision-language pre-trained model, i.e., CLIP has shown strong ability on zero-shot recognition, and parameter efficient tuning can further improve its performance on specific tasks. This work demonstrates that a simple domain prior boosts CLIP's zero-shot recognition in a specific domain. Besides, CLIP's adaptation relies less on source domain data due to its diverse pre-training dataset. Furthermore, we create a benchmark for zero-shot adaptation and pseudo-labeling based self-training with CLIP. Last but not least, we propose to improve the task generalization ability of CLIP from multiple unlabeled domains, which is a more practical and unique scenario. We believe our findings motivate a rethinking of domain adaptation benchmarks and the associated role of related algorithms in the era of CLIP.
Rate-Distortion-Cognition Controllable Versatile Neural Image Compression
Jul 16, 2024Recently, the field of Image Coding for Machines (ICM) has garnered heightened interest and significant advances thanks to the rapid progress of learning-based techniques for image compression and analysis. Previous studies often require training separate codecs to support various bitrate levels, machine tasks, and networks, thus lacking both flexibility and practicality. To address these challenges, we propose a rate-distortion-cognition controllable versatile image compression, which method allows the users to adjust the bitrate (i.e., Rate), image reconstruction quality (i.e., Distortion), and machine task accuracy (i.e., Cognition) with a single neural model, achieving ultra-controllability. Specifically, we first introduce a cognition-oriented loss in the primary compression branch to train a codec for diverse machine tasks. This branch attains variable bitrate by regulating quantization degree through the latent code channels. To further enhance the quality of the reconstructed images, we employ an auxiliary branch to supplement residual information with a scalable bitstream. Ultimately, two branches use a `$\beta x + (1 - \beta) y$' interpolation strategy to achieve a balanced cognition-distortion trade-off. Extensive experiments demonstrate that our method yields satisfactory ICM performance and flexible Rate-Distortion-Cognition controlling.
PromptCIR: Blind Compressed Image Restoration with Prompt Learning
Apr 26, 2024Blind Compressed Image Restoration (CIR) has garnered significant attention due to its practical applications. It aims to mitigate compression artifacts caused by unknown quality factors, particularly with JPEG codecs. Existing works on blind CIR often seek assistance from a quality factor prediction network to facilitate their network to restore compressed images. However, the predicted numerical quality factor lacks spatial information, preventing network adaptability toward image contents. Recent studies in prompt-learning-based image restoration have showcased the potential of prompts to generalize across varied degradation types and degrees. This motivated us to design a prompt-learning-based compressed image restoration network, dubbed PromptCIR, which can effectively restore images from various compress levels. Specifically, PromptCIR exploits prompts to encode compression information implicitly, where prompts directly interact with soft weights generated from image features, thus providing dynamic content-aware and distortion-aware guidance for the restoration process. The light-weight prompts enable our method to adapt to different compression levels, while introducing minimal parameter overhead. Overall, PromptCIR leverages the powerful transformer-based backbone with the dynamic prompt module to proficiently handle blind CIR tasks, winning first place in the NTIRE 2024 challenge of blind compressed image enhancement track. Extensive experiments have validated the effectiveness of our proposed PromptCIR. The code is available at https://github.com/lbc12345/PromptCIR-NTIRE24.
SeD: Semantic-Aware Discriminator for Image Super-Resolution
Feb 29, 2024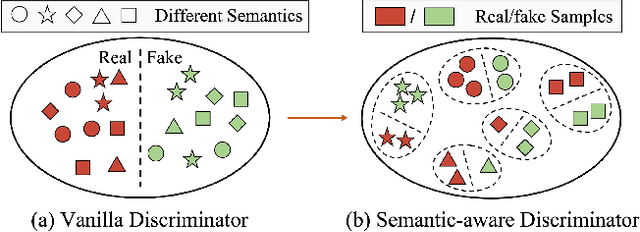
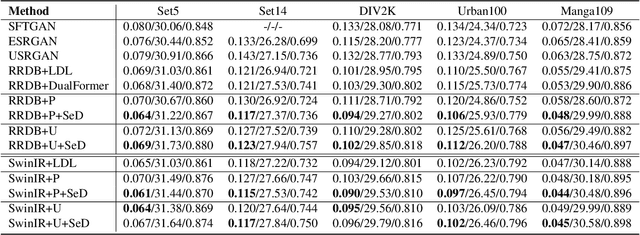
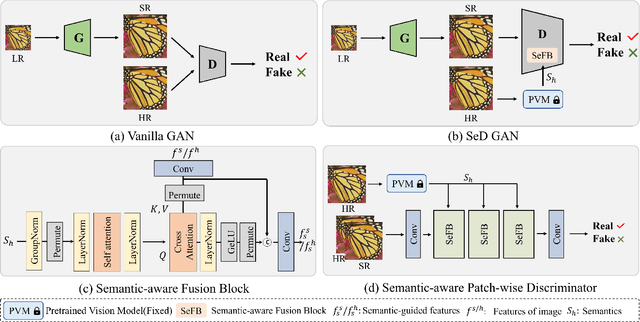
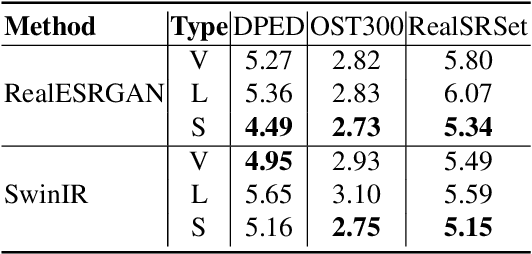
Generative Adversarial Networks (GANs) have been widely used to recover vivid textures in image super-resolution (SR) tasks. In particular, one discriminator is utilized to enable the SR network to learn the distribution of real-world high-quality images in an adversarial training manner. However, the distribution learning is overly coarse-grained, which is susceptible to virtual textures and causes counter-intuitive generation results. To mitigate this, we propose the simple and effective Semantic-aware Discriminator (denoted as SeD), which encourages the SR network to learn the fine-grained distributions by introducing the semantics of images as a condition. Concretely, we aim to excavate the semantics of images from a well-trained semantic extractor. Under different semantics, the discriminator is able to distinguish the real-fake images individually and adaptively, which guides the SR network to learn the more fine-grained semantic-aware textures. To obtain accurate and abundant semantics, we take full advantage of recently popular pretrained vision models (PVMs) with extensive datasets, and then incorporate its semantic features into the discriminator through a well-designed spatial cross-attention module. In this way, our proposed semantic-aware discriminator empowered the SR network to produce more photo-realistic and pleasing images. Extensive experiments on two typical tasks, i.e., SR and Real SR have demonstrated the effectiveness of our proposed methods.
ART$\boldsymbol{\cdot}$V: Auto-Regressive Text-to-Video Generation with Diffusion Models
Nov 30, 2023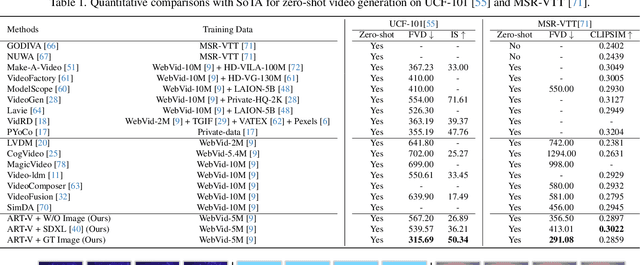
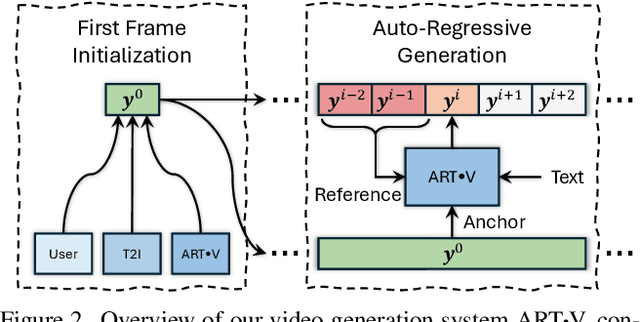
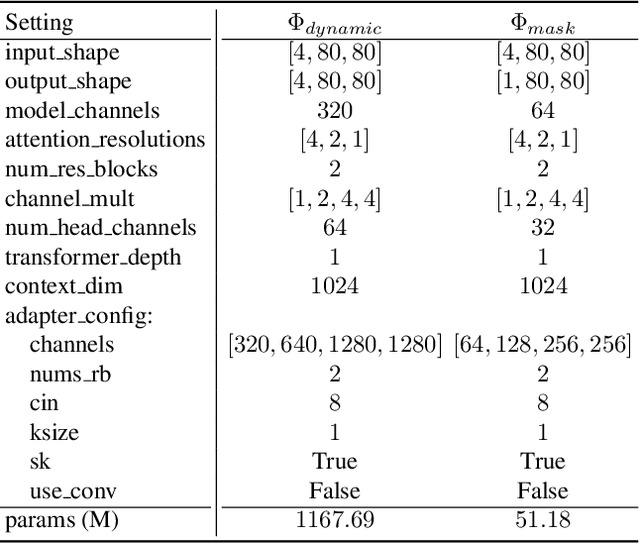
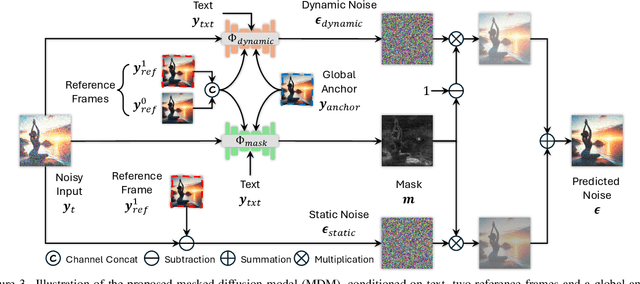
We present ART$\boldsymbol{\cdot}$V, an efficient framework for auto-regressive video generation with diffusion models. Unlike existing methods that generate entire videos in one-shot, ART$\boldsymbol{\cdot}$V generates a single frame at a time, conditioned on the previous ones. The framework offers three distinct advantages. First, it only learns simple continual motions between adjacent frames, therefore avoiding modeling complex long-range motions that require huge training data. Second, it preserves the high-fidelity generation ability of the pre-trained image diffusion models by making only minimal network modifications. Third, it can generate arbitrarily long videos conditioned on a variety of prompts such as text, image or their combinations, making it highly versatile and flexible. To combat the common drifting issue in AR models, we propose masked diffusion model which implicitly learns which information can be drawn from reference images rather than network predictions, in order to reduce the risk of generating inconsistent appearances that cause drifting. Moreover, we further enhance generation coherence by conditioning it on the initial frame, which typically contains minimal noise. This is particularly useful for long video generation. When trained for only two weeks on four GPUs, ART$\boldsymbol{\cdot}$V already can generate videos with natural motions, rich details and a high level of aesthetic quality. Besides, it enables various appealing applications, e.g., composing a long video from multiple text prompts.
MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation
Nov 30, 2023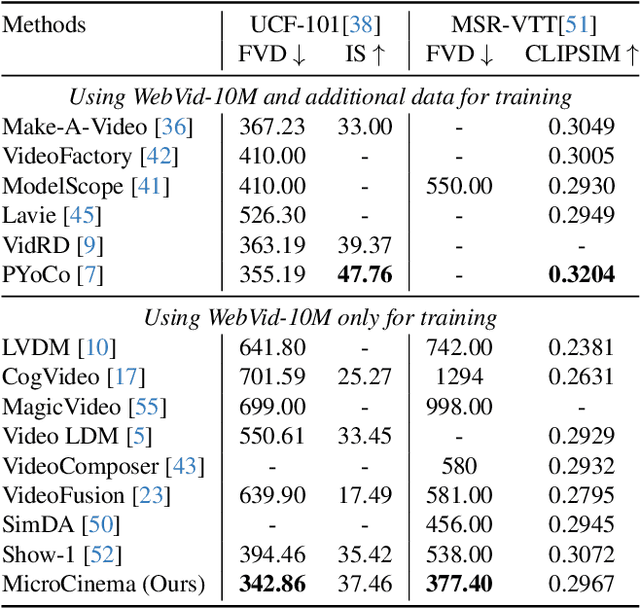
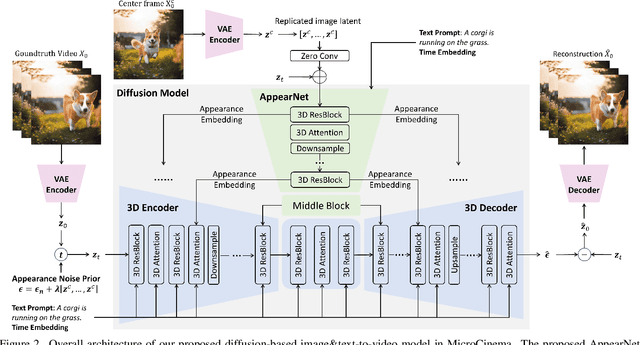
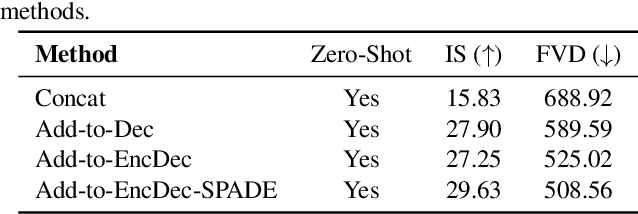
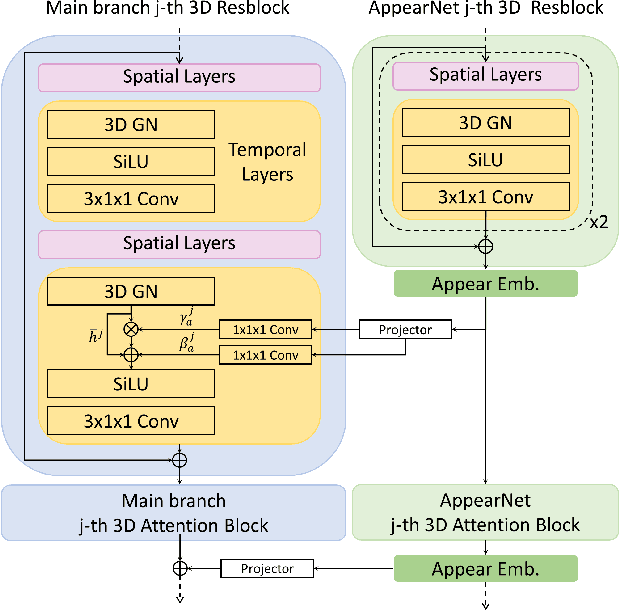
We present MicroCinema, a straightforward yet effective framework for high-quality and coherent text-to-video generation. Unlike existing approaches that align text prompts with video directly, MicroCinema introduces a Divide-and-Conquer strategy which divides the text-to-video into a two-stage process: text-to-image generation and image\&text-to-video generation. This strategy offers two significant advantages. a) It allows us to take full advantage of the recent advances in text-to-image models, such as Stable Diffusion, Midjourney, and DALLE, to generate photorealistic and highly detailed images. b) Leveraging the generated image, the model can allocate less focus to fine-grained appearance details, prioritizing the efficient learning of motion dynamics. To implement this strategy effectively, we introduce two core designs. First, we propose the Appearance Injection Network, enhancing the preservation of the appearance of the given image. Second, we introduce the Appearance Noise Prior, a novel mechanism aimed at maintaining the capabilities of pre-trained 2D diffusion models. These design elements empower MicroCinema to generate high-quality videos with precise motion, guided by the provided text prompts. Extensive experiments demonstrate the superiority of the proposed framework. Concretely, MicroCinema achieves SOTA zero-shot FVD of 342.86 on UCF-101 and 377.40 on MSR-VTT. See https://wangyanhui666.github.io/MicroCinema.github.io/ for video samples.
CCEdit: Creative and Controllable Video Editing via Diffusion Models
Sep 28, 2023



In this work, we present CCEdit, a versatile framework designed to address the challenges of creative and controllable video editing. CCEdit accommodates a wide spectrum of user editing requirements and enables enhanced creative control through an innovative approach that decouples video structure and appearance. We leverage the foundational ControlNet architecture to preserve structural integrity, while seamlessly integrating adaptable temporal modules compatible with state-of-the-art personalization techniques for text-to-image generation, such as DreamBooth and LoRA.Furthermore, we introduce reference-conditioned video editing, empowering users to exercise precise creative control over video editing through the more manageable process of editing key frames. Our extensive experimental evaluations confirm the exceptional functionality and editing capabilities of the proposed CCEdit framework. Demo video is available at https://www.youtube.com/watch?v=UQw4jq-igN4.