 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tri-Dynamic Preprocessing Framework for UGC Video Compression
Dec 18, 2025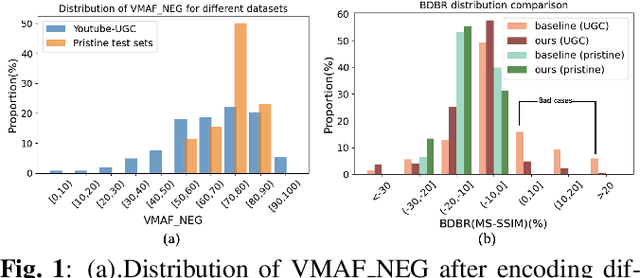
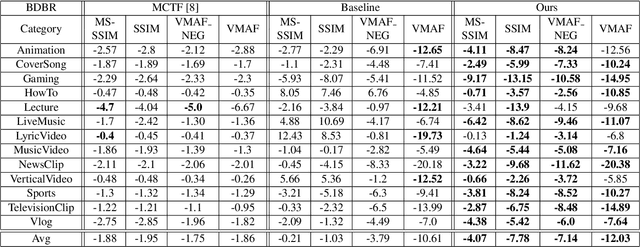
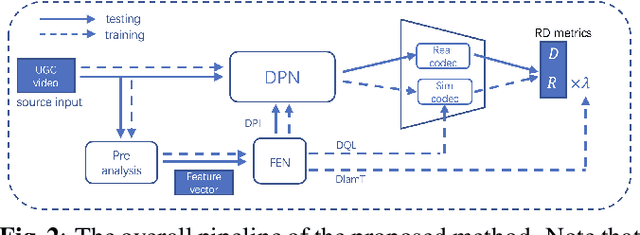
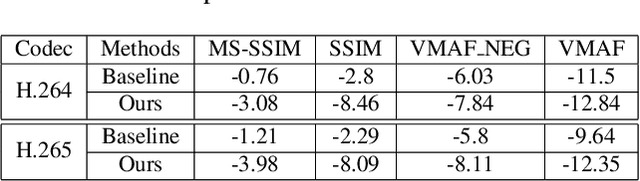
In recent years, user generated content (UGC) has become the dominant force in internet traffic. However, UGC videos exhibit a higher degree of variability and diverse characteristics compared to traditional encoding test videos. This variance challenges the effectiveness of data-driven machine learning algorithms for optimizing encoding in the broader context of UGC scenarios. To address this issue, we propose a Tri-Dynamic Preprocessing framework for UGC. Firstly, we employ an adaptive factor to regulate preprocessing intensity. Secondly, an adaptive quantization level is employed to fine-tune the codec simulator. Thirdly, we utilize an adaptive lambda tradeoff to adjust the rate-distortion loss function. Experimental results on large-scale test sets demonstrate that our method attains exceptional performance.
A Preprocessing Framework for Video Machine Vision under Compression
Dec 17, 2025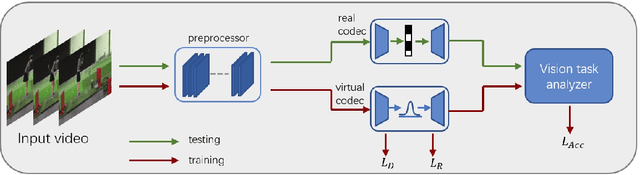
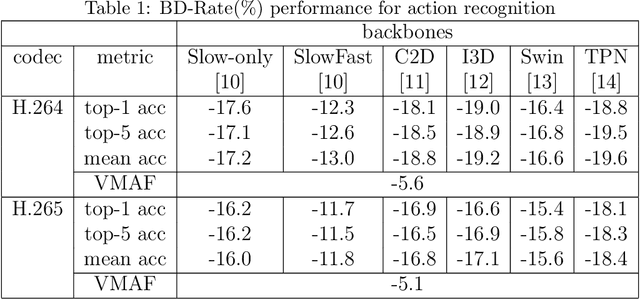
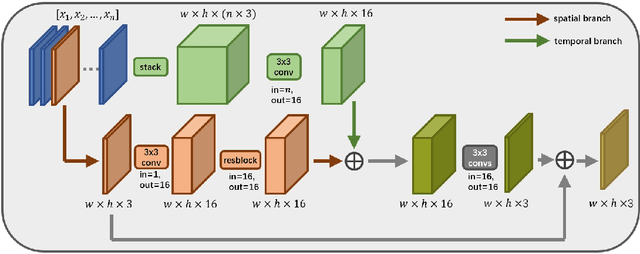
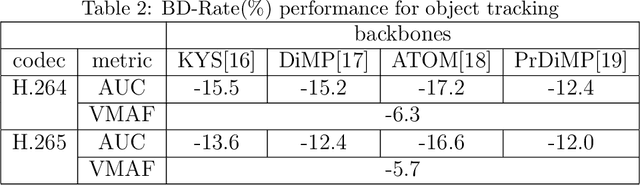
There has been a growing trend in compressing and transmitting videos from terminals for machine vision tasks. Nevertheless, most video coding optimization method focus on minimizing distortion according to human perceptual metrics, overlooking the heightened demands posed by machine vision systems. In this paper, we propose a video preprocessing framework tailored for machine vision tasks to address this challenge. The proposed method incorporates a neural preprocessor which retaining crucial information for subsequent tasks, resulting in the boosting of rate-accuracy performance. We further introduce a differentiable virtual codec to provide constraints on rate and distortion during the training stage. We directly apply widely used standard codecs for testing. Therefore, our solution can be easily applied to real-world scenarios. We conducted extensive experiments evaluating our compression method on two typical downstream tasks with various backbone networks. The experimental results indicate that our approach can save over 15% of bitrate compared to using only the standard codec anchor version.
Audio-Visual Cross-Modal Compression for Generative Face Video Coding
Dec 17, 2025Generative face video coding (GFVC) is vital for modern applications like video conferencing, yet existing methods primarily focus on video motion while neglecting the significant bitrate contribution of audio. Despite the well-established correlation between audio and lip movements, this cross-modal coherence has not been systematically exploited for compression. To address this, we propose an Audio-Visual Cross-Modal Compression (AVCC) framework that jointly compresses audio and video streams. Our framework extracts motion information from video and tokenizes audio features, then aligns them through a unified audio-video diffusion process. This allows synchronized reconstruction of both modalities from a shared representation. In extremely low-rate scenarios, AVCC can even reconstruct one modality from the other. Experiments show that AVCC significantly outperforms the Versatile Video Coding (VVC) standard and state-of-the-art GFVC schemes in rate-distortion performance, paving the way for more efficient multimodal communication systems.
Generative Preprocessing for Image Compression with Pre-trained Diffusion Models
Dec 17, 2025Preprocessing is a well-established technique for optimizing compression, yet existing methods are predominantly Rate-Distortion (R-D) optimized and constrained by pixel-level fidelity. This work pioneers a shift towards Rate-Perception (R-P) optimization by, for the first time, adapting a large-scale pre-trained diffusion model for compression preprocessing. We propose a two-stage framework: first, we distill the multi-step Stable Diffusion 2.1 into a compact, one-step image-to-image model using Consistent Score Identity Distillation (CiD). Second, we perform a parameter-efficient fine-tuning of the distilled model's attention modules, guided by a Rate-Perception loss and a differentiable codec surrogate. Our method seamlessly integrates with standard codecs without any modification and leverages the model's powerful generative priors to enhance texture and mitigate artifacts. Experiments show substantial R-P gains, achieving up to a 30.13% BD-rate reduction in DISTS on the Kodak dataset and delivering superior subjective visual quality.
Region-Adaptive Video Sharpening via Rate-Perception Optimization
Aug 12, 2025



Sharpening is a widely adopted video enhancement technique. However, uniform sharpening intensity ignores texture variations, degrading video quality. Sharpening also increases bitrate, and there's a lack of techniques to optimally allocate these additional bits across diverse regions. Thus, this paper proposes RPO-AdaSharp, an end-to-end region-adaptive video sharpening model for both perceptual enhancement and bitrate savings. We use the coding tree unit (CTU) partition mask as prior information to guide and constrain the allocation of increased bits. Experiments on benchmarks demonstrate the effectiveness of the proposed model qualitatively and quantitatively.
MambaCSR: Dual-Interleaved Scanning for Compressed Image Super-Resolution With SSMs
Aug 21, 2024We present MambaCSR, a simple but effective framework based on Mamba for the challenging compressed image super-resolution (CSR) task. Particularly, the scanning strategies of Mamba are crucial for effective contextual knowledge modeling in the restoration process despite it relying on selective state space modeling for all tokens. In this work, we propose an efficient dual-interleaved scanning paradigm (DIS) for CSR, which is composed of two scanning strategies: (i) hierarchical interleaved scanning is designed to comprehensively capture and utilize the most potential contextual information within an image by simultaneously taking advantage of the local window-based and sequential scanning methods; (ii) horizontal-to-vertical interleaved scanning is proposed to reduce the computational cost by leaving the redundancy between the scanning of different directions. To overcome the non-uniform compression artifacts, we also propose position-aligned cross-scale scanning to model multi-scale contextual information. Experimental results on multiple benchmarks have shown the great performance of our MambaCSR in the compressed image super-resolution task. The code will be soon available in~\textcolor{magenta}{\url{https://github.com/renyulin-f/MambaCSR}}.
MoE-DiffIR: Task-customized Diffusion Priors for Universal Compressed Image Restoration
Jul 15, 2024We present MoE-DiffIR, an innovative universal compressed image restoration (CIR) method with task-customized diffusion priors. This intends to handle two pivotal challenges in the existing CIR methods: (i) lacking adaptability and universality for different image codecs, e.g., JPEG and WebP; (ii) poor texture generation capability, particularly at low bitrates. Specifically, our MoE-DiffIR develops the powerful mixture-of-experts (MoE) prompt module, where some basic prompts cooperate to excavate the task-customized diffusion priors from Stable Diffusion (SD) for each compression task. Moreover, the degradation-aware routing mechanism is proposed to enable the flexible assignment of basic prompts. To activate and reuse the cross-modality generation prior of SD, we design the visual-to-text adapter for MoE-DiffIR, which aims to adapt the embedding of low-quality images from the visual domain to the textual domain as the textual guidance for SD, enabling more consistent and reasonable texture generation. We also construct one comprehensive benchmark dataset for universal CIR, covering 21 types of degradations from 7 popular traditional and learned codecs. Extensive experiments on universal CIR have demonstrated the excellent robustness and texture restoration capability of our proposed MoE-DiffIR. The project can be found at https://renyulin-f.github.io/MoE-DiffIR.github.io/.
PromptCIR: Blind Compressed Image Restoration with Prompt Learning
Apr 26, 2024Blind Compressed Image Restoration (CIR) has garnered significant attention due to its practical applications. It aims to mitigate compression artifacts caused by unknown quality factors, particularly with JPEG codecs. Existing works on blind CIR often seek assistance from a quality factor prediction network to facilitate their network to restore compressed images. However, the predicted numerical quality factor lacks spatial information, preventing network adaptability toward image contents. Recent studies in prompt-learning-based image restoration have showcased the potential of prompts to generalize across varied degradation types and degrees. This motivated us to design a prompt-learning-based compressed image restoration network, dubbed PromptCIR, which can effectively restore images from various compress levels. Specifically, PromptCIR exploits prompts to encode compression information implicitly, where prompts directly interact with soft weights generated from image features, thus providing dynamic content-aware and distortion-aware guidance for the restoration process. The light-weight prompts enable our method to adapt to different compression levels, while introducing minimal parameter overhead. Overall, PromptCIR leverages the powerful transformer-based backbone with the dynamic prompt module to proficiently handle blind CIR tasks, winning first place in the NTIRE 2024 challenge of blind compressed image enhancement track. Extensive experiments have validated the effectiveness of our proposed PromptCIR. The code is available at https://github.com/lbc12345/PromptCIR-NTIRE24.
Optimal Transcoding Resolution Prediction for Efficient Per-Title Bitrate Ladder Estimation
Jan 09, 2024Adaptive video streaming requires efficient bitrate ladder construction to meet heterogeneous network conditions and end-user demands. Per-title optimized encoding typically traverses numerous encoding parameters to search the Pareto-optimal operating points for each video. Recently, researchers have attempted to predict the content-optimized bitrate ladder for pre-encoding overhead reduction. However, existing methods commonly estimate the encoding parameters on the Pareto front and still require subsequent pre-encodings. In this paper, we propose to directly predict the optimal transcoding resolution at each preset bitrate for efficient bitrate ladder construction. We adopt a Temporal Attentive Gated Recurrent Network to capture spatial-temporal features and predict transcoding resolutions as a multi-task classification problem. We demonstrate that content-optimized bitrate ladders can thus be efficiently determined without any pre-encoding. Our method well approximates the ground-truth bitrate-resolution pairs with a slight Bj{\o}ntegaard Delta rate loss of 1.21% and significantly outperforms the state-of-the-art fixed ladder.
Video Compression with Arbitrary Rescaling Network
Jun 07, 2023
Most video platforms provide video streaming services with different qualities, and the quality of the services is usually adjusted by the resolution of the videos. So high-resolution videos need to be downsampled for compression. In order to solve the problem of video coding at different resolutions, we propose a rate-guided arbitrary rescaling network (RARN) for video resizing before encoding. To help the RARN be compatible with standard codecs and generate compression-friendly results, an iteratively optimized transformer-based virtual codec (TVC) is introduced to simulate the key components of video encoding and perform bitrate estimation. By iteratively training the TVC and the RARN, we achieved 5%-29% BD-Rate reduction anchored by linear interpolation under different encoding configurations and resolutions, exceeding the previous methods on most test videos. Furthermore, the lightweight RARN structure can process FHD (1080p) content at real-time speed (91 FPS) and obtain a considerable rate reduction.