 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboBrain 2.5: Depth in Sight, Time in Mind
Jan 20, 2026We introduce RoboBrain 2.5, a next-generation embodied AI foundation model that advances general perception, spatial reasoning, and temporal modeling through extensive training on high-quality spatiotemporal supervision. Building upon its predecessor, RoboBrain 2.5 introduces two major capability upgrades. Specifically, it unlocks Precise 3D Spatial Reasoning by shifting from 2D pixel-relative grounding to depth-aware coordinate prediction and absolute metric constraint comprehension, generating complete 3D manipulation traces as ordered keypoint sequences under physical constraints. Complementing this spatial precision, the model establishes Dense Temporal Value Estimation that provides dense, step-aware progress prediction and execution state understanding across varying viewpoints, producing stable feedback signals for downstream learning. Together, these upgrades extend the framework toward more physically grounded and execution-aware embodied intelligence for complex, fine-grained manipulation. The code and checkpoints are available at project website: https://superrobobrain.github.io
DesignEdit: Multi-Layered Latent Decomposition and Fusion for Unified & Accurate Image Editing
Mar 21, 2024



Recently, how to achieve precise image editing has attracted increasing attention, especially given the remarkable success of text-to-image generation models. To unify various spatial-aware image editing abilities into one framework, we adopt the concept of layers from the design domain to manipulate objects flexibly with various operations. The key insight is to transform the spatial-aware image editing task into a combination of two sub-tasks: multi-layered latent decomposition and multi-layered latent fusion. First, we segment the latent representations of the source images into multiple layers, which include several object layers and one incomplete background layer that necessitates reliable inpainting. To avoid extra tuning, we further explore the inner inpainting ability within the self-attention mechanism. We introduce a key-masking self-attention scheme that can propagate the surrounding context information into the masked region while mitigating its impact on the regions outside the mask. Second, we propose an instruction-guided latent fusion that pastes the multi-layered latent representations onto a canvas latent. We also introduce an artifact suppression scheme in the latent space to enhance the inpainting quality. Due to the inherent modular advantages of such multi-layered representations, we can achieve accurate image editing, and we demonstrate that our approach consistently surpasses the latest spatial editing methods, including Self-Guidance and DiffEditor. Last, we show that our approach is a unified framework that supports various accurate image editing tasks on more than six different editing tasks.
Towards Blind Watermarking: Combining Invertible and Non-invertible Mechanisms
Dec 24, 2022
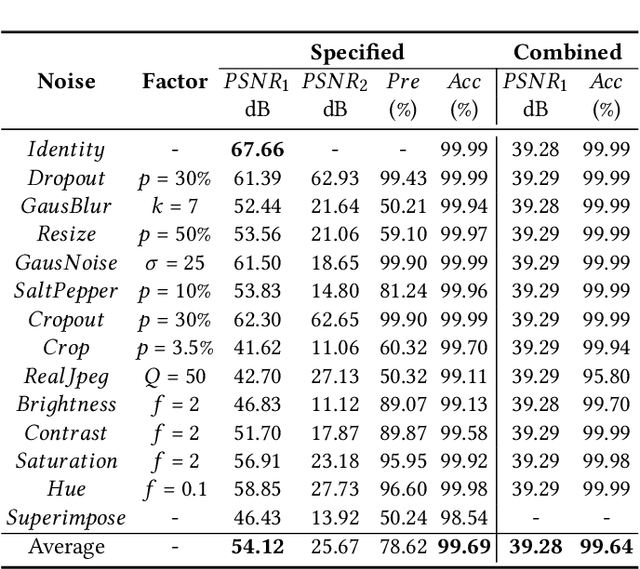
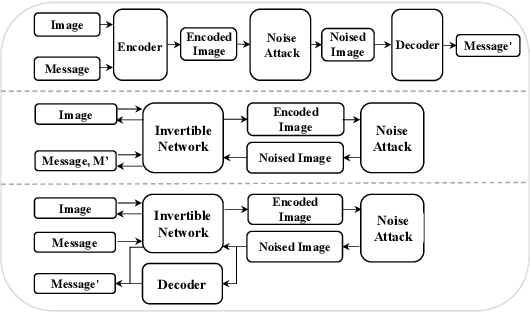
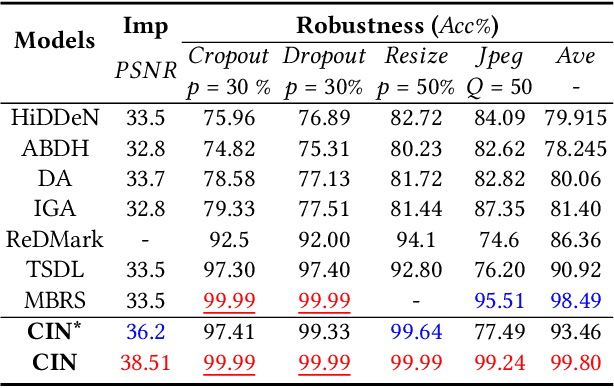
Blind watermarking provides powerful evidence for copyright protection, image authentication, and tampering identification. However, it remains a challenge to design a watermarking model with high imperceptibility and robustness against strong noise attacks. To resolve this issue, we present a framework Combining the Invertible and Non-invertible (CIN) mechanisms. The CIN is composed of the invertible part to achieve high imperceptibility and the non-invertible part to strengthen the robustness against strong noise attacks. For the invertible part, we develop a diffusion and extraction module (DEM) and a fusion and split module (FSM) to embed and extract watermarks symmetrically in an invertible way. For the non-invertible part, we introduce a non-invertible attention-based module (NIAM) and the noise-specific selection module (NSM) to solve the asymmetric extraction under a strong noise attack. Extensive experiments demonstrate that our framework outperforms the current state-of-the-art methods of imperceptibility and robustness significantly. Our framework can achieve an average of 99.99% accuracy and 67.66 dB PSNR under noise-free conditions, while 96.64% and 39.28 dB combined strong noise attacks. The code will be available in https://github.com/rmpku/CIN.
Multi-Agent Automated Machine Learning
Oct 17, 2022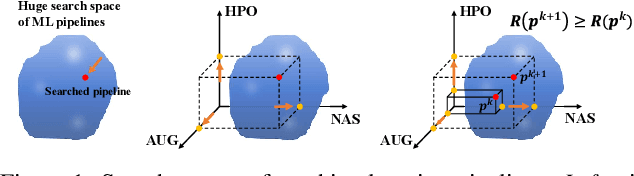
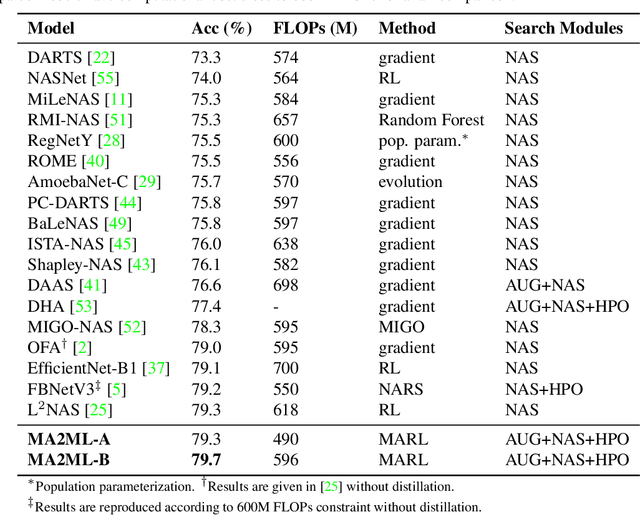
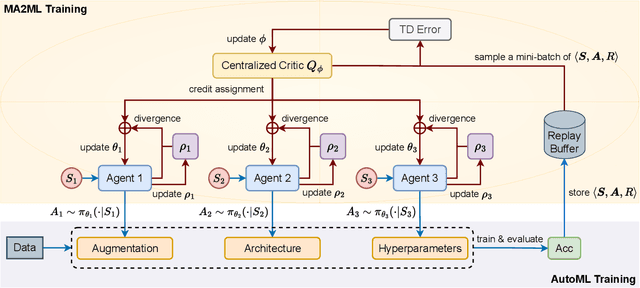
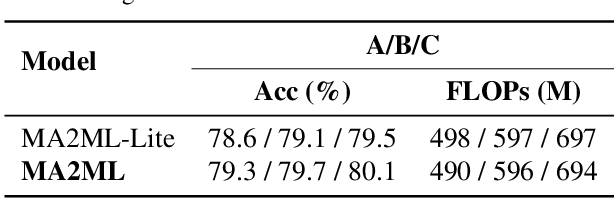
In this paper, we propose multi-agent automated machine learning (MA2ML) with the aim to effectively handle joint optimization of modules in automated machine learning (AutoML). MA2ML takes each machine learning module, such as data augmentation (AUG), neural architecture search (NAS), or hyper-parameters (HPO), as an agent and the final performance as the reward, to formulate a multi-agent reinforcement learning problem. MA2ML explicitly assigns credit to each agent according to its marginal contribution to enhance cooperation among modules, and incorporates off-policy learning to improve search efficiency. Theoretically, MA2ML guarantees monotonic improvement of joint optimization. Extensive experiments show that MA2ML yields the state-of-the-art top-1 accuracy on ImageNet under constraints of computational cost, e.g., $79.7\%/80.5\%$ with FLOPs fewer than 600M/800M. Extensive ablation studies verify the benefits of credit assignment and off-policy learning of MA2ML.
Enhancing and Dissecting Crowd Counting By Synthetic Data
Jan 22, 2022
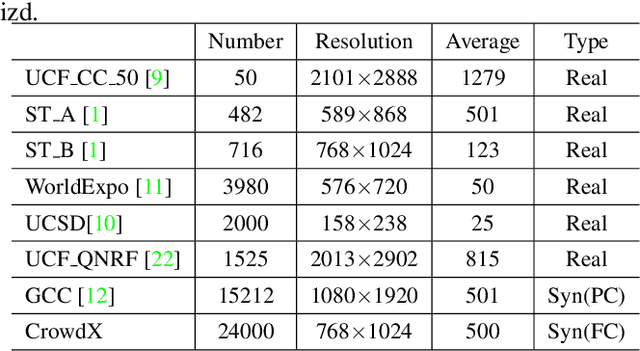

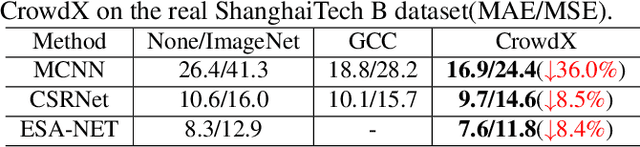
In this article, we propose a simulated crowd counting dataset CrowdX, which has a large scale, accurate labeling, parameterized realization, and high fidelity. The experimental results of using this dataset as data enhancement show that the performance of the proposed streamlined and efficient benchmark network ESA-Net can be improved by 8.4\%. The other two classic heterogeneous architectures MCNN and CSRNet pre-trained on CrowdX also show significant performance improvements. Considering many influencing factors determine performance, such as background, camera angle, human density, and resolution. Although these factors are important, there is still a lack of research on how they affect crowd counting. Thanks to the CrowdX dataset with rich annotation information, we conduct a large number of data-driven comparative experiments to analyze these factors. Our research provides a reference for a deeper understanding of the crowd counting problem and puts forward some useful suggestions in the actual deployment of the algorithm.
BBA-net: A bi-branch attention network for crowd counting
Jan 22, 2022
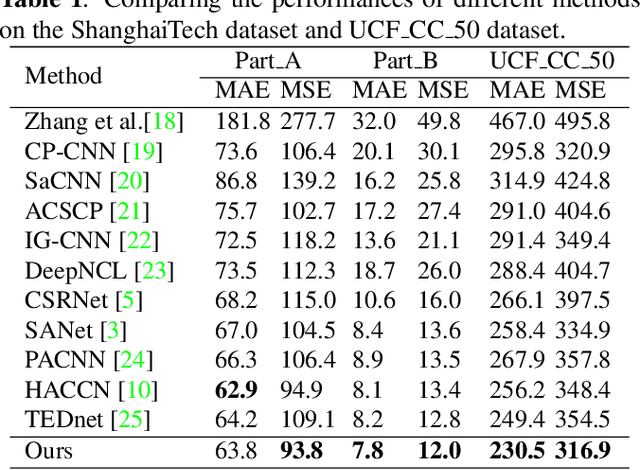
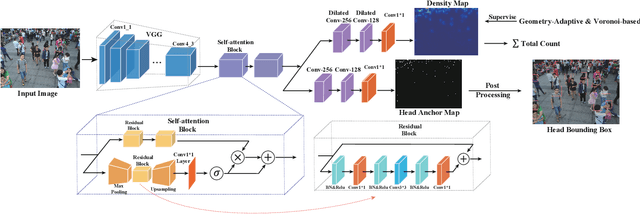

In the field of crowd counting, the current mainstream CNN-based regression methods simply extract the density information of pedestrians without finding the position of each person. This makes the output of the network often found to contain incorrect responses, which may erroneously estimate the total number and not conducive to the interpretation of the algorithm. To this end, we propose a Bi-Branch Attention Network (BBA-NET) for crowd counting, which has three innovation points. i) A two-branch architecture is used to estimate the density information and location information separately. ii) Attention mechanism is used to facilitate feature extraction, which can reduce false responses. iii) A new density map generation method combining geometric adaptation and Voronoi split is introduced. Our method can integrate the pedestrian's head and body information to enhance the feature expression ability of the density map. Extensive experiments performed on two public datasets show that our method achieves a lower crowd counting error compared to other state-of-the-art methods.
FFA-Net: Feature Fusion Attention Network for Single Image Dehazing
Dec 05, 2019
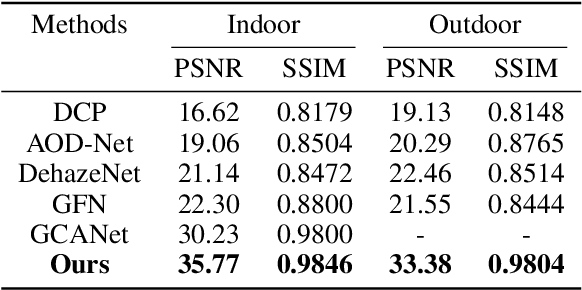
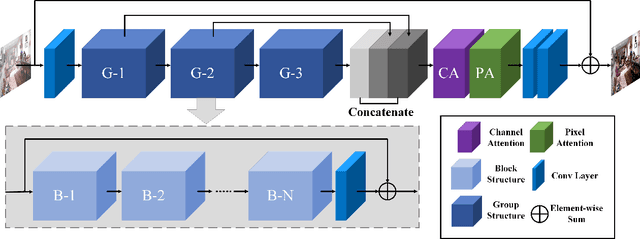
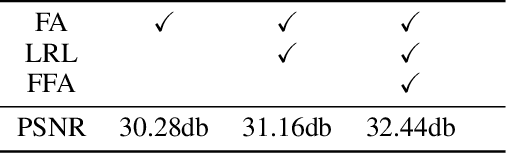
In this paper, we propose an end-to-end feature fusion at-tention network (FFA-Net) to directly restore the haze-free image. The FFA-Net architecture consists of three key components: 1) A novel Feature Attention (FA) module combines Channel Attention with Pixel Attention mechanism, considering that different channel-wise features contain totally different weighted information and haze distribution is uneven on the different image pixels. FA treats different features and pixels unequally, which provides additional flexibility in dealing with different types of information, expanding the representational ability of CNNs. 2) A basic block structure consists of Local Residual Learning and Feature Attention, Local Residual Learning allowing the less important information such as thin haze region or low-frequency to be bypassed through multiple local residual connections, let main network architecture focus on more effective information. 3) An Attention-based different levels Feature Fusion (FFA) structure, the feature weights are adaptively learned from the Feature Attention (FA) module, giving more weight to important features. This structure can also retain the information of shallow layers and pass it into deep layers. The experimental results demonstrate that our proposed FFA-Net surpasses previous state-of-the-art single image dehazing methods by a very large margin both quantitatively and qualitatively, boosting the best published PSNR metric from 30.23db to 36.39db on the SOTS indoor test dataset. Code has been made available at GitHub.
Single Image Blind Deblurring Using Multi-Scale Latent Structure Prior
Jun 11, 2019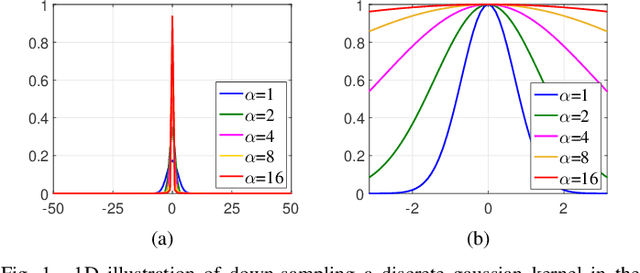
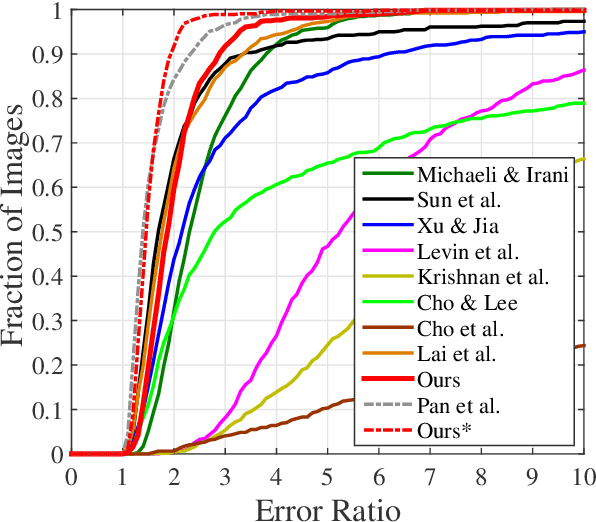


Blind image deblurring is a challenging problem in computer vision, which aims to restore both the blur kernel and the latent sharp image from only a blurry observation. Inspired by the prevalent self-example prior in image super-resolution, in this paper, we observe that a coarse enough image down-sampled from a blurry observation is approximately a low-resolution version of the latent sharp image. We prove this phenomenon theoretically and define the coarse enough image as a latent structure prior of the unknown sharp image. Starting from this prior, we propose to restore sharp images from the coarsest scale to the finest scale on a blurry image pyramid, and progressively update the prior image using the newly restored sharp image. These coarse-to-fine priors are referred to as \textit{Multi-Scale Latent Structures} (MSLS). Leveraging the MSLS prior, our algorithm comprises two phases: 1) we first preliminarily restore sharp images in the coarse scales; 2) we then apply a refinement process in the finest scale to obtain the final deblurred image. In each scale, to achieve lower computational complexity, we alternately perform a sharp image reconstruction with fast local self-example matching, an accelerated kernel estimation with error compensation, and a fast non-blind image deblurring, instead of computing any computationally expensive non-convex priors. We further extend the proposed algorithm to solve more challenging non-uniform blind image deblurring problem. Extensive experiments demonstrate that our algorithm achieves competitive results against the state-of-the-art methods with much faster running speed.
Attention Driven Person Re-identification
Oct 13, 2018
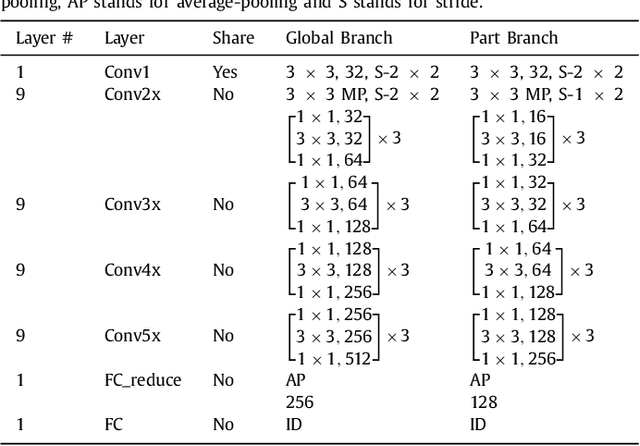

Person re-identification (ReID) is a challenging task due to arbitrary human pose variations, background clutters, etc. It has been studied extensively in recent years, but the multifarious local and global features are still not fully exploited by either ignoring the interplay between whole-body images and body-part images or missing in-depth examination of specific body-part images. In this paper, we propose a novel attention-driven multi-branch network that learns robust and discriminative human representation from global whole-body images and local body-part images simultaneously. Within each branch, an intra-attention network is designed to search for informative and discriminative regions within the whole-body or body-part images, where attention is elegantly decomposed into spatial-wise attention and channel-wise attention for effective and efficient learning. In addition, a novel inter-attention module is designed which fuses the output of intra-attention networks adaptively for optimal person ReID. The proposed technique has been evaluated over three widely used datasets CUHK03, Market-1501 and DukeMTMC-ReID, and experiments demonstrate its superior robustness and effectiveness as compared with the state of the arts.
Trajectory Factory: Tracklet Cleaving and Re-connection by Deep Siamese Bi-GRU for Multiple Object Tracking
Apr 12, 2018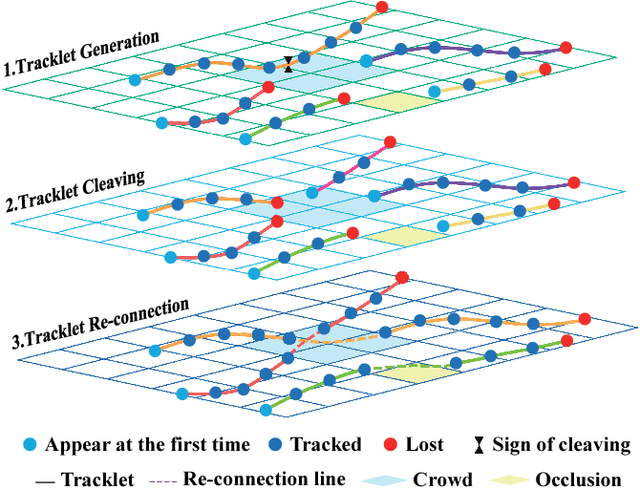
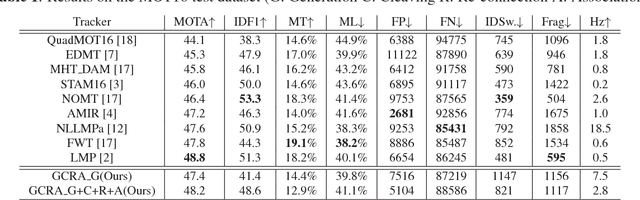
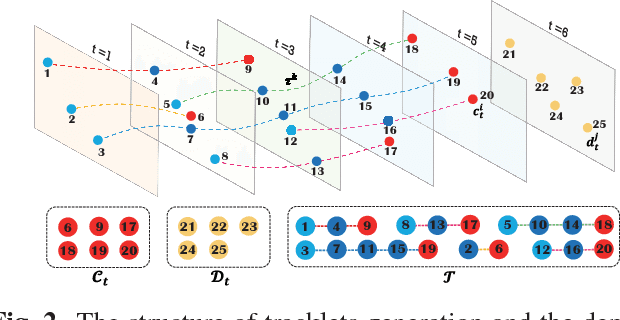
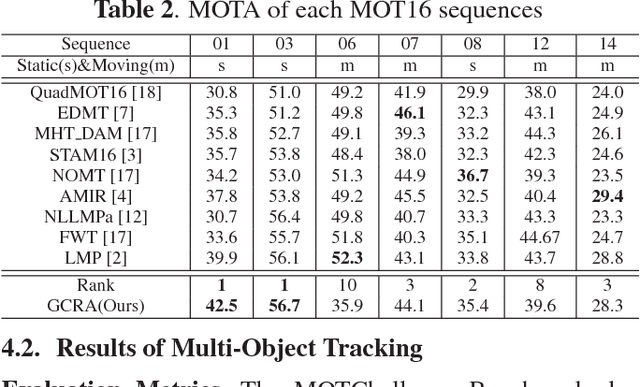
Multi-Object Tracking (MOT) is a challenging task in the complex scene such as surveillance and autonomous driving. In this paper, we propose a novel tracklet processing method to cleave and re-connect tracklets on crowd or long-term occlusion by Siamese Bi-Gated Recurrent Unit (GRU). The tracklet generation utilizes object features extracted by CNN and RNN to create the high-confidence tracklet candidates in sparse scenario. Due to mis-tracking in the generation process, the tracklets from different objects are split into several sub-tracklets by a bidirectional GRU. After that, a Siamese GRU based tracklet re-connection method is applied to link the sub-tracklets which belong to the same object to form a whole trajectory. In addition, we extract the tracklet images from existing MOT datasets and propose a novel dataset to train our networks. The proposed dataset contains more than 95160 pedestrian images. It has 793 different persons in it. On average, there are 120 images for each person with positions and sizes. Experimental results demonstrate the advantages of our model over the state-of-the-art methods on MOT16.