 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Heads to Neurons: Causal Attribution and Steering in Multi-Task Vision-Language Models
Apr 20, 2026Recent work has increasingly explored neuron-level interpretation in vision-language models (VLMs) to identify neurons critical to final predictions. However, existing neuron analyses generally focus on single tasks, limiting the comparability of neuron importance across tasks. Moreover, ranking strategies tend to score neurons in isolation, overlooking how task-dependent information pathways shape the write-in effects of feed-forward network (FFN) neurons. This oversight can exacerbate neuron polysemanticity in multi-task settings, introducing noise into the identification and intervention of task-critical neurons. In this study, we propose HONES (Head-Oriented Neuron Explanation & Steering), a gradient-free framework for task-aware neuron attribution and steering in multi-task VLMs. HONES ranks FFN neurons by their causal write-in contributions conditioned on task-relevant attention heads, and further modulates salient neurons via lightweight scaling. Experiments on four diverse multimodal tasks and two popular VLMs show that HONES outperforms existing methods in identifying task-critical neurons and improves model performance after steering. Our source code is released at: https://github.com/petergit1/HONES.
SciEvent: Benchmarking Multi-domain Scientific Event Extraction
Sep 19, 2025

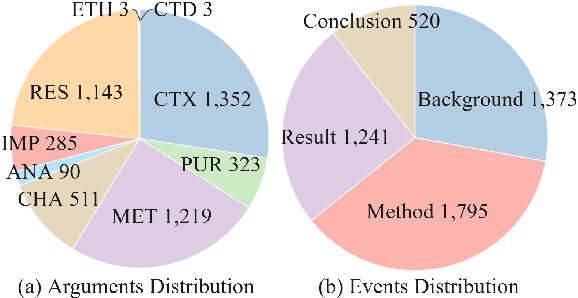
Scientific information extraction (SciIE) has primarily relied on entity-relation extraction in narrow domains, limiting its applicability to interdisciplinary research and struggling to capture the necessary context of scientific information, often resulting in fragmented or conflicting statements. In this paper, we introduce SciEvent, a novel multi-domain benchmark of scientific abstracts annotated via a unified event extraction (EE) schema designed to enable structured and context-aware understanding of scientific content. It includes 500 abstracts across five research domains, with manual annotations of event segments, triggers, and fine-grained arguments. We define SciIE as a multi-stage EE pipeline: (1) segmenting abstracts into core scientific activities--Background, Method, Result, and Conclusion; and (2) extracting the corresponding triggers and arguments. Experiments with fine-tuned EE models, large language models (LLMs), and human annotators reveal a performance gap, with current models struggling in domains such as sociology and humanities. SciEvent serves as a challenging benchmark and a step toward generalizable, multi-domain SciIE.
V-SEAM: Visual Semantic Editing and Attention Modulating for Causal Interpretability of Vision-Language Models
Sep 18, 2025Recent advances in causal interpretability have extended from language models to vision-language models (VLMs), seeking to reveal their internal mechanisms through input interventions. While textual interventions often target semantics, visual interventions typically rely on coarse pixel-level perturbations, limiting semantic insights on multimodal integration. In this study, we introduce V-SEAM, a novel framework that combines Visual Semantic Editing and Attention Modulating for causal interpretation of VLMs. V-SEAM enables concept-level visual manipulations and identifies attention heads with positive or negative contributions to predictions across three semantic levels: objects, attributes, and relationships. We observe that positive heads are often shared within the same semantic level but vary across levels, while negative heads tend to generalize broadly. Finally, we introduce an automatic method to modulate key head embeddings, demonstrating enhanced performance for both LLaVA and InstructBLIP across three diverse VQA benchmarks. Our data and code are released at: https://github.com/petergit1/V-SEAM.
MonoPartNeRF:Human Reconstruction from Monocular Video via Part-Based Neural Radiance Fields
Aug 12, 2025In recent years, Neural Radiance Fields (NeRF) have achieved remarkable progress in dynamic human reconstruction and rendering. Part-based rendering paradigms, guided by human segmentation, allow for flexible parameter allocation based on structural complexity, thereby enhancing representational efficiency. However, existing methods still struggle with complex pose variations, often producing unnatural transitions at part boundaries and failing to reconstruct occluded regions accurately in monocular settings. We propose MonoPartNeRF, a novel framework for monocular dynamic human rendering that ensures smooth transitions and robust occlusion recovery. First, we build a bidirectional deformation model that combines rigid and non-rigid transformations to establish a continuous, reversible mapping between observation and canonical spaces. Sampling points are projected into a parameterized surface-time space (u, v, t) to better capture non-rigid motion. A consistency loss further suppresses deformation-induced artifacts and discontinuities. We introduce a part-based pose embedding mechanism that decomposes global pose vectors into local joint embeddings based on body regions. This is combined with keyframe pose retrieval and interpolation, along three orthogonal directions, to guide pose-aware feature sampling. A learnable appearance code is integrated via attention to model dynamic texture changes effectively. Experiments on the ZJU-MoCap and MonoCap datasets demonstrate that our method significantly outperforms prior approaches under complex pose and occlusion conditions, achieving superior joint alignment, texture fidelity, and structural continuity.
No Preference Left Behind: Group Distributional Preference Optimization
Dec 28, 2024



Preferences within a group of people are not uniform but follow a distribution. While existing alignment methods like Direct Preference Optimization (DPO) attempt to steer models to reflect human preferences, they struggle to capture the distributional pluralistic preferences within a group. These methods often skew toward dominant preferences, overlooking the diversity of opinions, especially when conflicting preferences arise. To address this issue, we propose Group Distribution Preference Optimization (GDPO), a novel framework that aligns language models with the distribution of preferences within a group by incorporating the concept of beliefs that shape individual preferences. GDPO calibrates a language model using statistical estimation of the group's belief distribution and aligns the model with belief-conditioned preferences, offering a more inclusive alignment framework than traditional methods. In experiments using both synthetic controllable opinion generation and real-world movie review datasets, we show that DPO fails to align with the targeted belief distributions, while GDPO consistently reduces this alignment gap during training. Moreover, our evaluation metrics demonstrate that GDPO outperforms existing approaches in aligning with group distributional preferences, marking a significant advance in pluralistic alignment.
Cross-modal Medical Image Generation Based on Pyramid Convolutional Attention Network
Nov 26, 2024


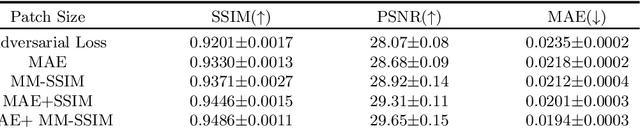
The integration of multimodal medical imaging can provide complementary and comprehensive information for the diagnosis of Alzheimer's disease (AD). However, in clinical practice, since positron emission tomography (PET) is often missing, multimodal images might be incomplete. To address this problem, we propose a method that can efficiently utilize structural magnetic resonance imaging (sMRI) image information to generate high-quality PET images. Our generation model efficiently utilizes pyramid convolution combined with channel attention mechanism to extract multi-scale local features in sMRI, and injects global correlation information into these features using self-attention mechanism to ensure the restoration of the generated PET image on local texture and global structure. Additionally, we introduce additional loss functions to guide the generation model in producing higher-quality PET images. Through experiments conducted on publicly available ADNI databases, the generated images outperform previous research methods in various performance indicators (average absolute error: 0.0194, peak signal-to-noise ratio: 29.65, structural similarity: 0.9486) and are close to real images. In promoting AD diagnosis, the generated images combined with their corresponding sMRI also showed excellent performance in AD diagnosis tasks (classification accuracy: 94.21 %), and outperformed previous research methods of the same type. The experimental results demonstrate that our method outperforms other competing methods in quantitative metrics, qualitative visualization, and evaluation criteria.
Multi-Continental Healthcare Modelling Using Blockchain-Enabled Federated Learning
Oct 23, 2024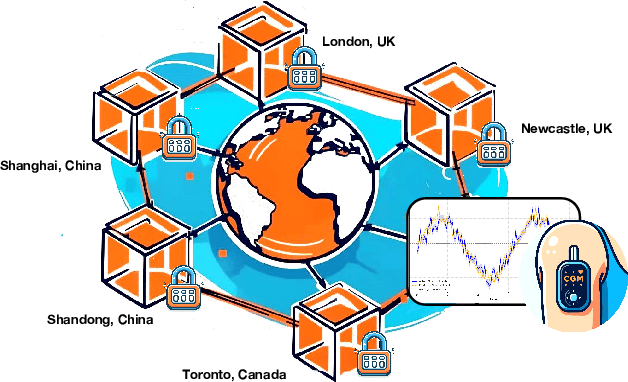
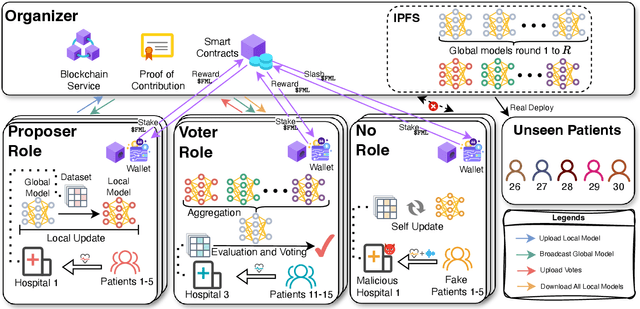
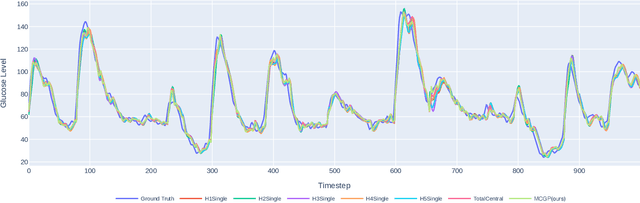
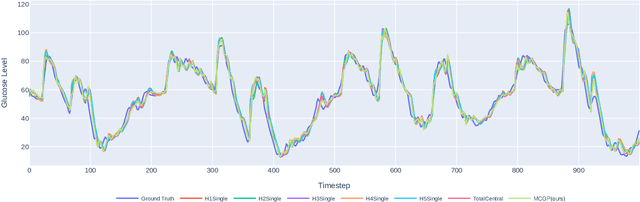
One of the biggest challenges of building artificial intelligence (AI) model in healthcare area is the data sharing. Since healthcare data is private, sensitive, and heterogeneous, collecting sufficient data for modelling is exhausted, costly, and sometimes impossible. In this paper, we propose a framework for global healthcare modelling using datasets from multi-continents (Europe, North America and Asia) while without sharing the local datasets, and choose glucose management as a study model to verify its effectiveness. Technically, blockchain-enabled federated learning is implemented with adaption to make it meet with the privacy and safety requirements of healthcare data, meanwhile rewards honest participation and penalize malicious activities using its on-chain incentive mechanism. Experimental results show that the proposed framework is effective, efficient, and privacy preserved. Its prediction accuracy is much better than the models trained from limited personal data and is similar to, and even slightly better than, the results from a centralized dataset. This work paves the way for international collaborations on healthcare projects, where additional data is crucial for reducing bias and providing benefits to humanity.
Class-RAG: Content Moderation with Retrieval Augmented Generation
Oct 18, 2024



Robust content moderation classifiers are essential for the safety of Generative AI systems. Content moderation, or safety classification, is notoriously ambiguous: differences between safe and unsafe inputs are often extremely subtle, making it difficult for classifiers (and indeed, even humans) to properly distinguish violating vs. benign samples without further context or explanation. Furthermore, as these technologies are deployed across various applications and audiences, scaling risk discovery and mitigation through continuous model fine-tuning becomes increasingly challenging and costly. To address these challenges, we propose a Classification approach employing Retrieval-Augmented Generation (Class-RAG). Class-RAG extends the capability of its base LLM through access to a retrieval library which can be dynamically updated to enable semantic hotfixing for immediate, flexible risk mitigation. Compared to traditional fine-tuned models, Class-RAG demonstrates flexibility and transparency in decision-making. As evidenced by empirical studies, Class-RAG outperforms on classification and is more robust against adversarial attack. Besides, our findings suggest that Class-RAG performance scales with retrieval library size, indicating that increasing the library size is a viable and low-cost approach to improve content moderation.
Large Language Models Are Active Critics in NLG Evaluation
Oct 14, 2024The conventional paradigm of using large language models (LLMs) for evaluating natural language generation (NLG) systems typically relies on two key inputs: (1) a clear definition of the NLG task to be evaluated and (2) a list of pre-defined evaluation criteria. This process treats LLMs as ''passive critics,'' strictly following human-defined criteria for evaluation. However, as new NLG tasks emerge, the criteria for assessing text quality can vary greatly. Consequently, these rigid evaluation methods struggle to adapt to diverse NLG tasks without extensive prompt engineering customized for each specific task. To address this limitation, we introduce Active-Critic, a novel LLM-based NLG evaluation protocol that enables LLMs to function as ''active critics.'' Specifically, our protocol comprises two key stages. In the first stage, the LLM is instructed to infer the target NLG task and establish relevant evaluation criteria from the data. Building on this self-inferred information, the second stage dynamically optimizes the prompt to guide the LLM toward more human-aligned scoring decisions, while also generating detailed explanations to justify its evaluations. Experiments across four NLG evaluation tasks show that our approach achieves stronger alignment with human judgments than state-of-the-art evaluation methods. Our comprehensive analysis further highlights the effectiveness and explainability of Active-Critic with only a small amount of labeled data. We will share our code and data on GitHub.
Enhancing Robustness in Large Language Models: Prompting for Mitigating the Impact of Irrelevant Information
Aug 20, 2024
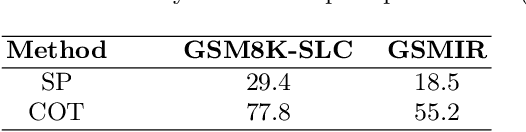
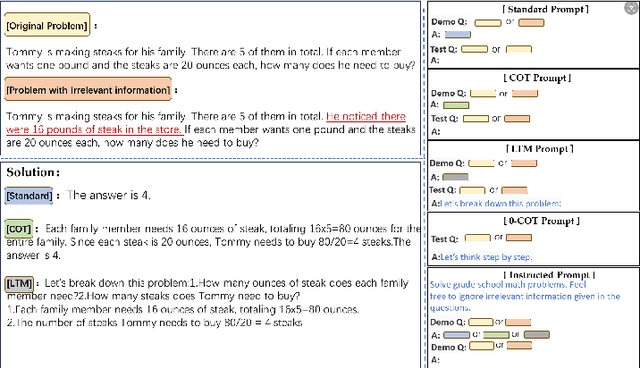
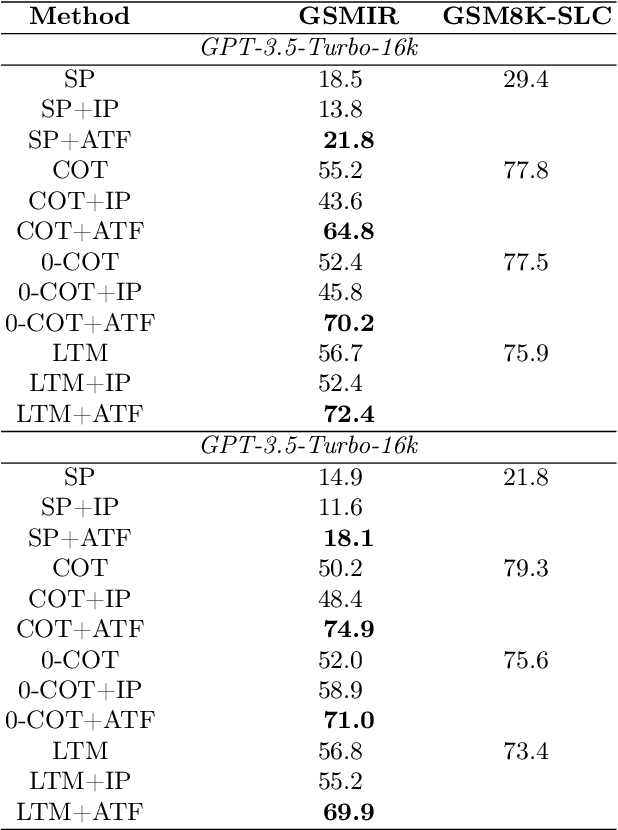
In recent years, Large language models (LLMs) have garnered significant attention due to their superior performance in complex reasoning tasks. However, recent studies may diminish their reasoning capabilities markedly when problem descriptions contain irrelevant information, even with the use of advanced prompting techniques. To further investigate this issue, a dataset of primary school mathematics problems containing irrelevant information, named GSMIR, was constructed. Testing prominent LLMs and prompting techniques on this dataset revealed that while LLMs can identify irrelevant information, they do not effectively mitigate the interference it causes once identified. A novel automatic construction method, ATF, which enhances the ability of LLMs to identify and self-mitigate the influence of irrelevant information, is proposed to address this shortcoming. This method operates in two steps: first, analysis of irrelevant information, followed by its filtering. The ATF method, as demonstrated by experimental results, significantly improves the reasoning performance of LLMs and prompting techniques, even in the presence of irrelevant information on the GSMIR dataset.