 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeXplain: Learning to Predict Natural Language Explanations of Visual Scanpaths
Paper and Code
Aug 05, 2024

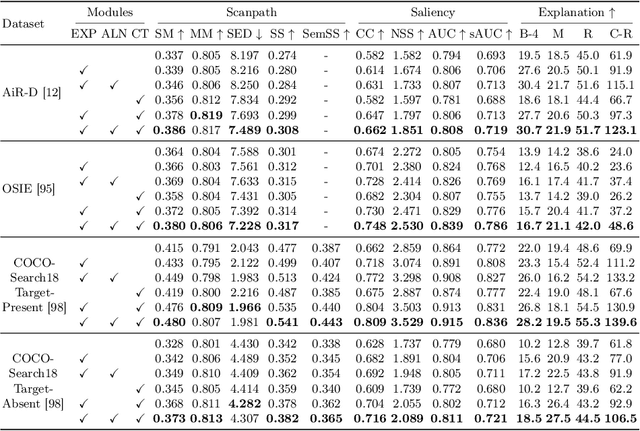

While exploring visual scenes, humans' scanpaths are driven by their underlying attention processes. Understanding visual scanpaths is essential for various applications. Traditional scanpath models predict the where and when of gaze shifts without providing explanations, creating a gap in understanding the rationale behind fixations. To bridge this gap, we introduce GazeXplain, a novel study of visual scanpath prediction and explanation. This involves annotating natural-language explanations for fixations across eye-tracking datasets and proposing a general model with an attention-language decoder that jointly predicts scanpaths and generates explanations. It integrates a unique semantic alignment mechanism to enhance the consistency between fixations and explanations, alongside a cross-dataset co-training approach for generalization. These novelties present a comprehensive and adaptable solution for explainable human visual scanpath prediction. Extensive experiments on diverse eye-tracking datasets demonstrate the effectiveness of GazeXplain in both scanpath prediction and explanation, offering valuable insights into human visual attention and cognitive processes.