 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Not Together? A Multiple-Round Recommender System for Queries and Items
Dec 14, 2024



A fundamental technique of recommender systems involves modeling user preferences, where queries and items are widely used as symbolic representations of user interests. Queries delineate user needs at an abstract level, providing a high-level description, whereas items operate on a more specific and concrete level, representing the granular facets of user preference. While practical, both query and item recommendations encounter the challenge of sparse user feedback. To this end, we propose a novel approach named Multiple-round Auto Guess-and-Update System (MAGUS) that capitalizes on the synergies between both types, allowing us to leverage both query and item information to form user interests. This integrated system introduces a recursive framework that could be applied to any recommendation method to exploit queries and items in historical interactions and to provide recommendations for both queries and items in each interaction round. Empirical results from testing 12 different recommendation methods demonstrate that integrating queries into item recommendations via MAGUS significantly enhances the efficiency, with which users can identify their preferred items during multiple-round interactions.
GazeXplain: Learning to Predict Natural Language Explanations of Visual Scanpaths
Aug 05, 2024

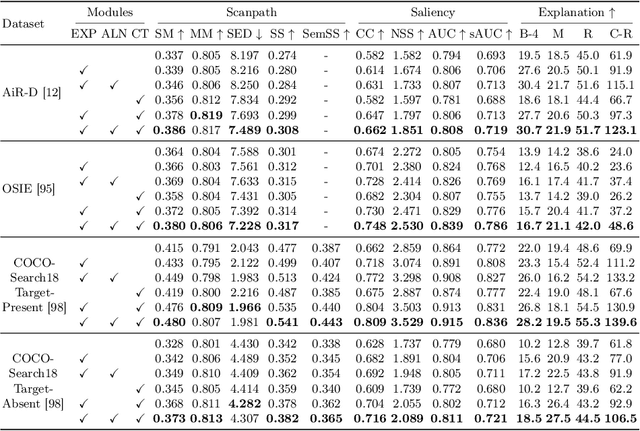

While exploring visual scenes, humans' scanpaths are driven by their underlying attention processes. Understanding visual scanpaths is essential for various applications. Traditional scanpath models predict the where and when of gaze shifts without providing explanations, creating a gap in understanding the rationale behind fixations. To bridge this gap, we introduce GazeXplain, a novel study of visual scanpath prediction and explanation. This involves annotating natural-language explanations for fixations across eye-tracking datasets and proposing a general model with an attention-language decoder that jointly predicts scanpaths and generates explanations. It integrates a unique semantic alignment mechanism to enhance the consistency between fixations and explanations, alongside a cross-dataset co-training approach for generalization. These novelties present a comprehensive and adaptable solution for explainable human visual scanpath prediction. Extensive experiments on diverse eye-tracking datasets demonstrate the effectiveness of GazeXplain in both scanpath prediction and explanation, offering valuable insights into human visual attention and cognitive processes.
Beyond Average: Individualized Visual Scanpath Prediction
Apr 19, 2024Understanding how attention varies across individuals has significant scientific and societal impacts. However, existing visual scanpath models treat attention uniformly, neglecting individual differences. To bridge this gap, this paper focuses on individualized scanpath prediction (ISP), a new attention modeling task that aims to accurately predict how different individuals shift their attention in diverse visual tasks. It proposes an ISP method featuring three novel technical components: (1) an observer encoder to characterize and integrate an observer's unique attention traits, (2) an observer-centric feature integration approach that holistically combines visual features, task guidance, and observer-specific characteristics, and (3) an adaptive fixation prioritization mechanism that refines scanpath predictions by dynamically prioritizing semantic feature maps based on individual observers' attention traits. These novel components allow scanpath models to effectively address the attention variations across different observers. Our method is generally applicable to different datasets, model architectures, and visual tasks, offering a comprehensive tool for transforming general scanpath models into individualized ones. Comprehensive evaluations using value-based and ranking-based metrics verify the method's effectiveness and generalizability.
Lending Interaction Wings to Recommender Systems with Conversational Agents
Oct 06, 2023



Recommender systems trained on offline historical user behaviors are embracing conversational techniques to online query user preference. Unlike prior conversational recommendation approaches that systemically combine conversational and recommender parts through a reinforcement learning framework, we propose CORE, a new offline-training and online-checking paradigm that bridges a COnversational agent and REcommender systems via a unified uncertainty minimization framework. It can benefit any recommendation platform in a plug-and-play style. Here, CORE treats a recommender system as an offline relevance score estimator to produce an estimated relevance score for each item; while a conversational agent is regarded as an online relevance score checker to check these estimated scores in each session. We define uncertainty as the summation of unchecked relevance scores. In this regard, the conversational agent acts to minimize uncertainty via querying either attributes or items. Based on the uncertainty minimization framework, we derive the expected certainty gain of querying each attribute and item, and develop a novel online decision tree algorithm to decide what to query at each turn. Experimental results on 8 industrial datasets show that CORE could be seamlessly employed on 9 popular recommendation approaches. We further demonstrate that our conversational agent could communicate as a human if empowered by a pre-trained large language model.
Replace Scoring with Arrangement: A Contextual Set-to-Arrangement Framework for Learning-to-Rank
Aug 05, 2023
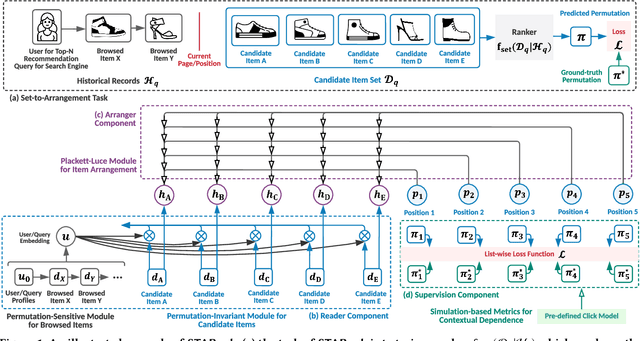


Learning-to-rank is a core technique in the top-N recommendation task, where an ideal ranker would be a mapping from an item set to an arrangement (a.k.a. permutation). Most existing solutions fall in the paradigm of probabilistic ranking principle (PRP), i.e., first score each item in the candidate set and then perform a sort operation to generate the top ranking list. However, these approaches neglect the contextual dependence among candidate items during individual scoring, and the sort operation is non-differentiable. To bypass the above issues, we propose Set-To-Arrangement Ranking (STARank), a new framework directly generates the permutations of the candidate items without the need for individually scoring and sort operations; and is end-to-end differentiable. As a result, STARank can operate when only the ground-truth permutations are accessible without requiring access to the ground-truth relevance scores for items. For this purpose, STARank first reads the candidate items in the context of the user browsing history, whose representations are fed into a Plackett-Luce module to arrange the given items into a list. To effectively utilize the given ground-truth permutations for supervising STARank, we leverage the internal consistency property of Plackett-Luce models to derive a computationally efficient list-wise loss. Experimental comparisons against 9 the state-of-the-art methods on 2 learning-to-rank benchmark datasets and 3 top-N real-world recommendation datasets demonstrate the superiority of STARank in terms of conventional ranking metrics. Notice that these ranking metrics do not consider the effects of the contextual dependence among the items in the list, we design a new family of simulation-based ranking metrics, where existing metrics can be regarded as special cases. STARank can consistently achieve better performance in terms of PBM and UBM simulation-based metrics.
Set-to-Sequence Ranking-based Concept-aware Learning Path Recommendation
Jun 07, 2023



With the development of the online education system, personalized education recommendation has played an essential role. In this paper, we focus on developing path recommendation systems that aim to generating and recommending an entire learning path to the given user in each session. Noticing that existing approaches fail to consider the correlations of concepts in the path, we propose a novel framework named Set-to-Sequence Ranking-based Concept-aware Learning Path Recommendation (SRC), which formulates the recommendation task under a set-to-sequence paradigm. Specifically, we first design a concept-aware encoder module which can capture the correlations among the input learning concepts. The outputs are then fed into a decoder module that sequentially generates a path through an attention mechanism that handles correlations between the learning and target concepts. Our recommendation policy is optimized by policy gradient. In addition, we also introduce an auxiliary module based on knowledge tracing to enhance the model's stability by evaluating students' learning effects on learning concepts. We conduct extensive experiments on two real-world public datasets and one industrial dataset, and the experimental results demonstrate the superiority and effectiveness of SRC. Code will be available at https://gitee.com/mindspore/models/tree/master/research/recommend/SRC.
Multi-Scale User Behavior Network for Entire Space Multi-Task Learning
Aug 16, 2022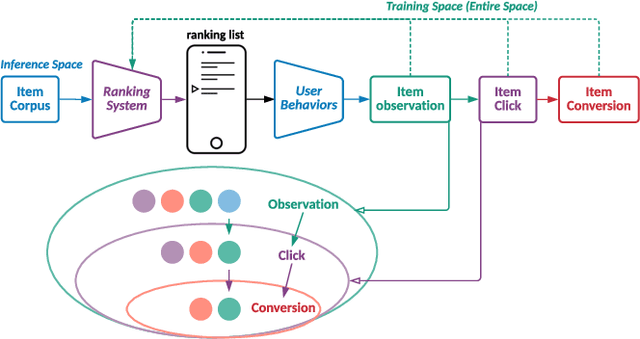

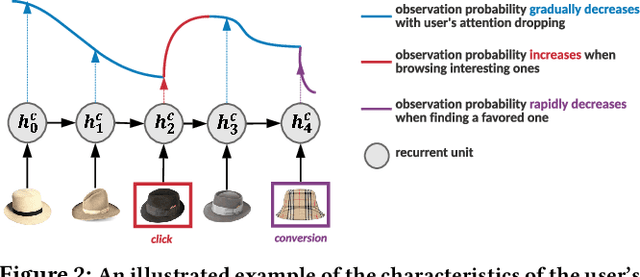
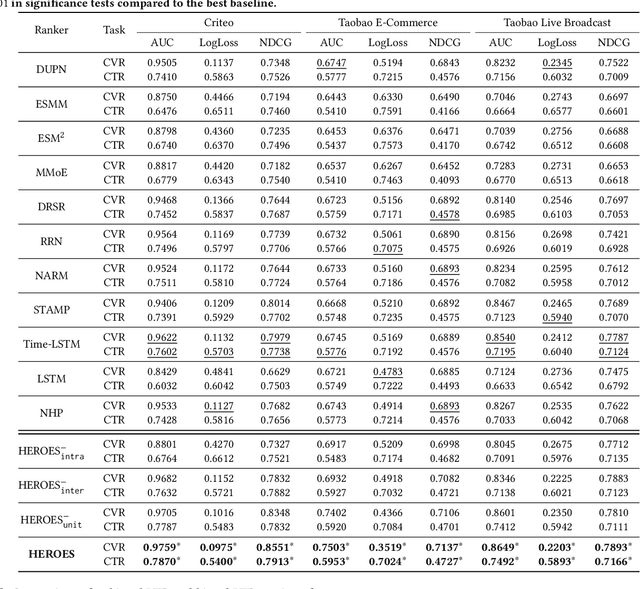
Modelling the user's multiple behaviors is an essential part of modern e-commerce, whose widely adopted application is to jointly optimize click-through rate (CTR) and conversion rate (CVR) predictions. Most of existing methods overlook the effect of two key characteristics of the user's behaviors: for each item list, (i) contextual dependence refers to that the user's behaviors on any item are not purely determinated by the item itself but also are influenced by the user's previous behaviors (e.g., clicks, purchases) on other items in the same sequence; (ii) multiple time scales means that users are likely to click frequently but purchase periodically. To this end, we develop a new multi-scale user behavior network named Hierarchical rEcurrent Ranking On the Entire Space (HEROES) which incorporates the contextual information to estimate the user multiple behaviors in a multi-scale fashion. Concretely, we introduce a hierarchical framework, where the lower layer models the user's engagement behaviors while the upper layer estimates the user's satisfaction behaviors. The proposed architecture can automatically learn a suitable time scale for each layer to capture the dynamic user's behavioral patterns. Besides the architecture, we also introduce the Hawkes process to form a novel recurrent unit which can not only encode the items' features in the context but also formulate the excitation or discouragement from the user's previous behaviors. We further show that HEROES can be extended to build unbiased ranking systems through combinations with the survival analysis technique. Extensive experiments over three large-scale industrial datasets demonstrate the superiority of our model compared with the state-of-the-art methods.
Multi-View Graph Representation for Programming Language Processing: An Investigation into Algorithm Detection
Feb 25, 2022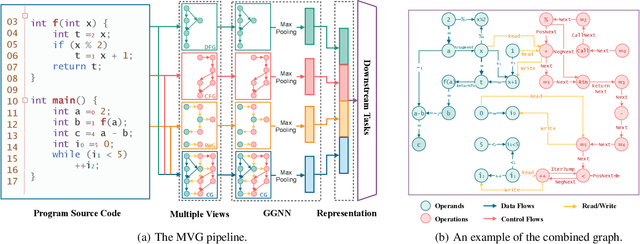
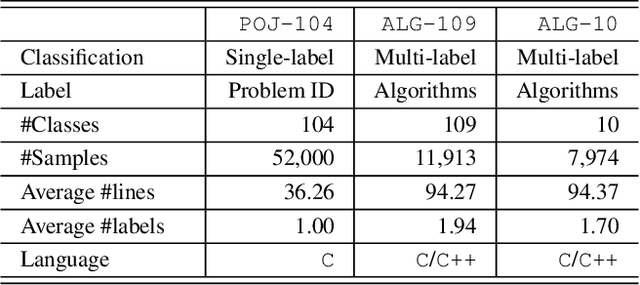
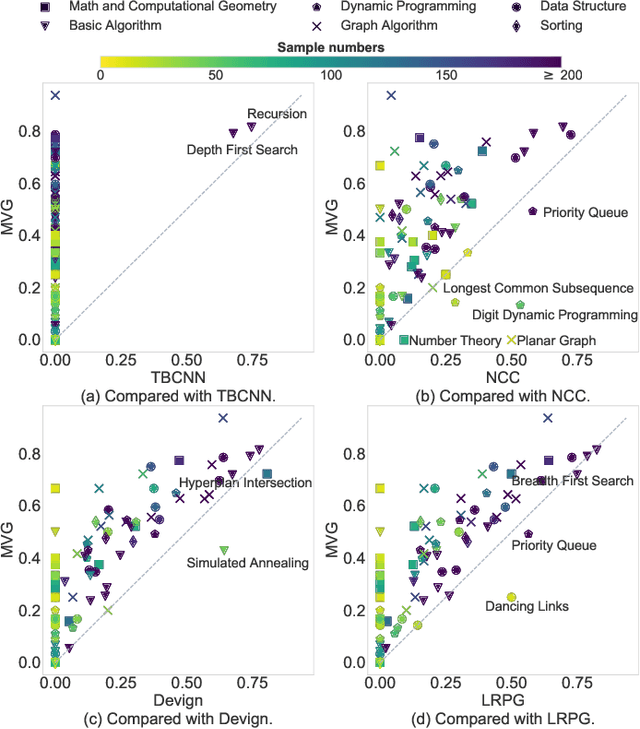
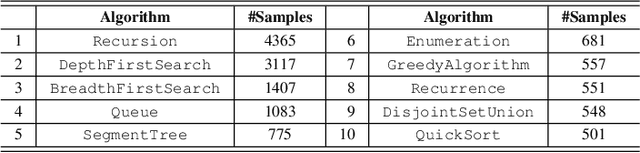
Program representation, which aims at converting program source code into vectors with automatically extracted features, is a fundamental problem in programming language processing (PLP). Recent work tries to represent programs with neural networks based on source code structures. However, such methods often focus on the syntax and consider only one single perspective of programs, limiting the representation power of models. This paper proposes a multi-view graph (MVG) program representation method. MVG pays more attention to code semantics and simultaneously includes both data flow and control flow as multiple views. These views are then combined and processed by a graph neural network (GNN) to obtain a comprehensive program representation that covers various aspects. We thoroughly evaluate our proposed MVG approach in the context of algorithm detection, an important and challenging subfield of PLP. Specifically, we use a public dataset POJ-104 and also construct a new challenging dataset ALG-109 to test our method. In experiments, MVG outperforms previous methods significantly, demonstrating our model's strong capability of representing source code.
Who to Watch Next: Two-side Interactive Networks for Live Broadcast Recommendation
Feb 09, 2022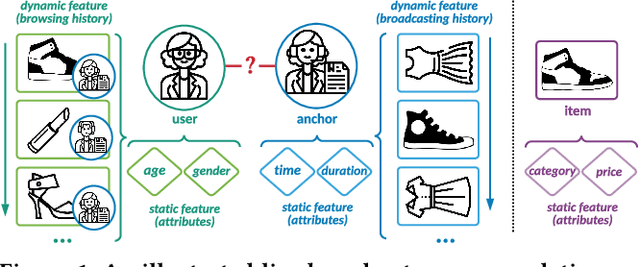
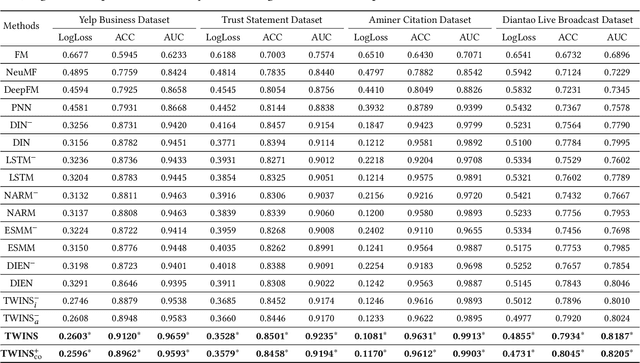
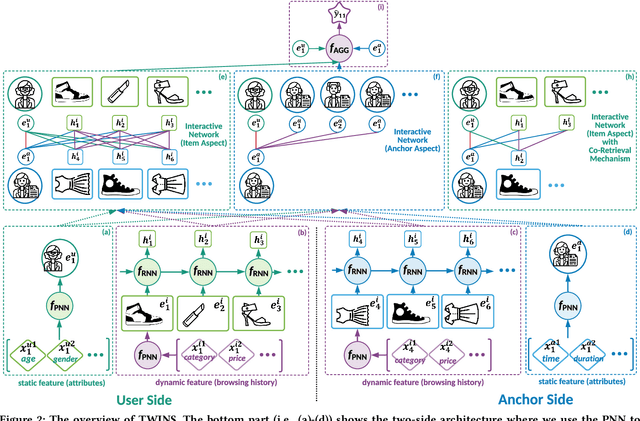

With the prevalence of live broadcast business nowadays, a new type of recommendation service, called live broadcast recommendation, is widely used in many mobile e-commerce Apps. Different from classical item recommendation, live broadcast recommendation is to automatically recommend user anchors instead of items considering the interactions among triple-objects (i.e., users, anchors, items) rather than binary interactions between users and items. Existing methods based on binary objects, ranging from early matrix factorization to recently emerged deep learning, obtain objects' embeddings by mapping from pre-existing features. Directly applying these techniques would lead to limited performance, as they are failing to encode collaborative signals among triple-objects. In this paper, we propose a novel TWo-side Interactive NetworkS (TWINS) for live broadcast recommendation. In order to fully use both static and dynamic information on user and anchor sides, we combine a product-based neural network with a recurrent neural network to learn the embedding of each object. In addition, instead of directly measuring the similarity, TWINS effectively injects the collaborative effects into the embedding process in an explicit manner by modeling interactive patterns between the user's browsing history and the anchor's broadcast history in both item and anchor aspects. Furthermore, we design a novel co-retrieval technique to select key items among massive historic records efficiently. Offline experiments on real large-scale data show the superior performance of the proposed TWINS, compared to representative methods; and further results of online experiments on Diantao App show that TWINS gains average performance improvement of around 8% on ACTR metric, 3% on UCTR metric, 3.5% on UCVR metric.
Learn over Past, Evolve for Future: Search-based Time-aware Recommendation with Sequential Behavior Data
Feb 07, 2022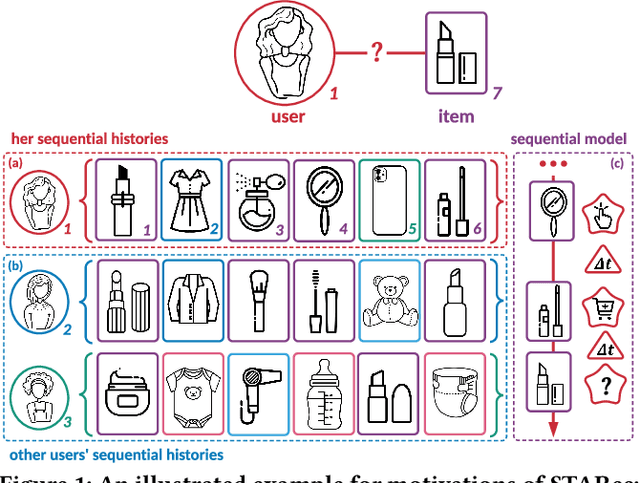

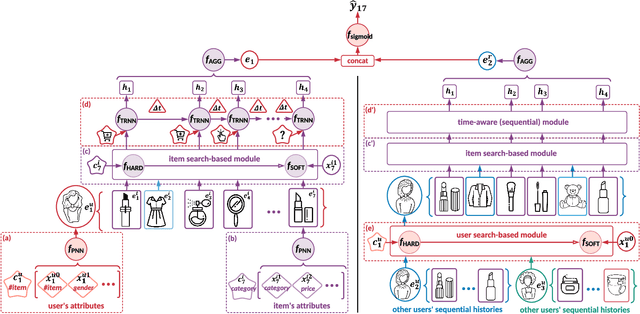
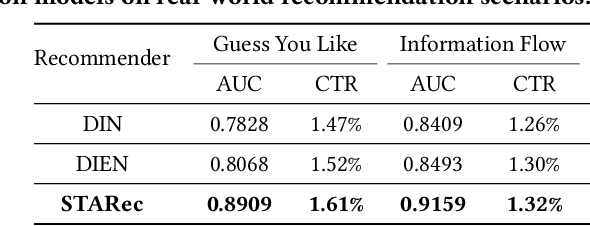
The personalized recommendation is an essential part of modern e-commerce, where user's demands are not only conditioned by their profile but also by their recent browsing behaviors as well as periodical purchases made some time ago. In this paper, we propose a novel framework named Search-based Time-Aware Recommendation (STARec), which captures the evolving demands of users over time through a unified search-based time-aware model. More concretely, we first design a search-based module to retrieve a user's relevant historical behaviors, which are then mixed up with her recent records to be fed into a time-aware sequential network for capturing her time-sensitive demands. Besides retrieving relevant information from her personal history, we also propose to search and retrieve similar user's records as an additional reference. All these sequential records are further fused to make the final recommendation. Beyond this framework, we also develop a novel label trick that uses the previous labels (i.e., user's feedbacks) as the input to better capture the user's browsing pattern. We conduct extensive experiments on three real-world commercial datasets on click-through-rate prediction tasks against state-of-the-art methods. Experimental results demonstrate the superiority and efficiency of our proposed framework and techniques. Furthermore, results of online experiments on a daily item recommendation platform of Company X show that STARec gains average performance improvement of around 6% and 1.5% in its two main item recommendation scenarios on CTR metric respectively.