 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn the Ropes, Then Trust the Wins: Self-imitation with Progressive Exploration for Agentic Reinforcement Learning
Sep 26, 2025
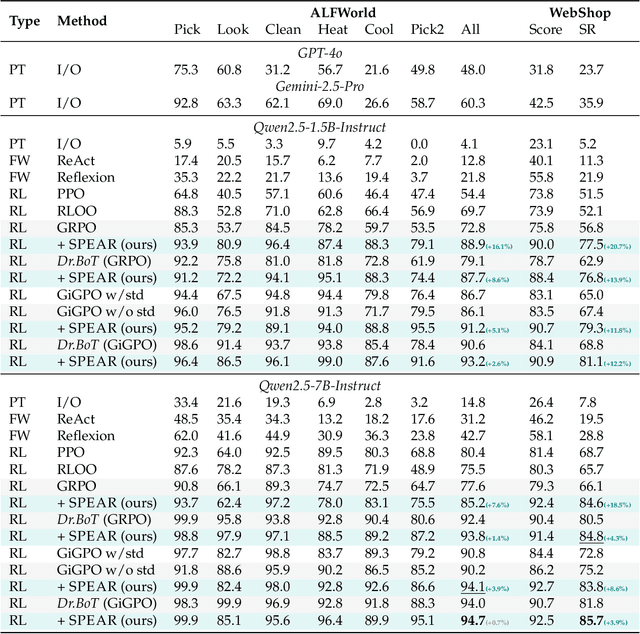
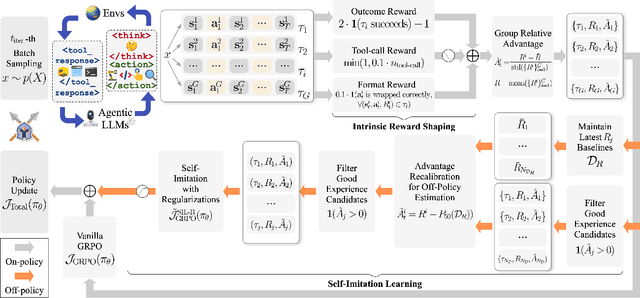
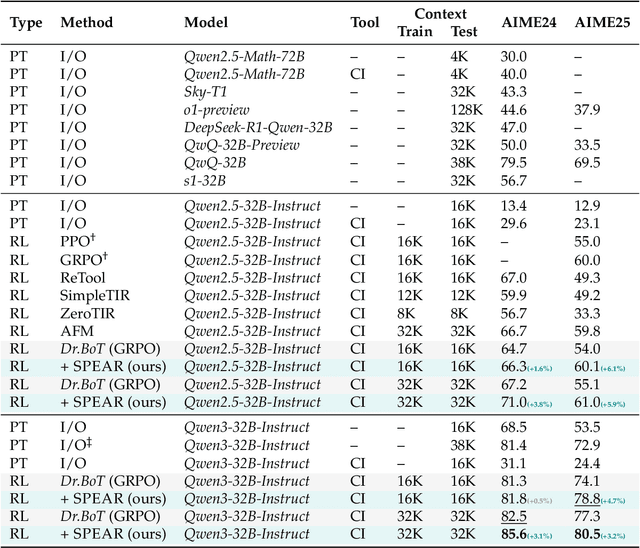
Reinforcement learning (RL) is the dominant paradigm for sharpening strategic tool use capabilities of LLMs on long-horizon, sparsely-rewarded agent tasks, yet it faces a fundamental challenge of exploration-exploitation trade-off. Existing studies stimulate exploration through the lens of policy entropy, but such mechanical entropy maximization is prone to RL training instability due to the multi-turn distribution shifting. In this paper, we target the progressive exploration-exploitation balance under the guidance of the agent own experiences without succumbing to either entropy collapsing or runaway divergence. We propose SPEAR, a curriculum-based self-imitation learning (SIL) recipe for training agentic LLMs. It extends the vanilla SIL framework, where a replay buffer stores self-generated promising trajectories for off-policy update, by gradually steering the policy evolution within a well-balanced range of entropy across stages. Specifically, our approach incorporates a curriculum to manage the exploration process, utilizing intrinsic rewards to foster skill-level exploration and facilitating action-level exploration through SIL. At first, the auxiliary tool call reward plays a critical role in the accumulation of tool-use skills, enabling broad exposure to the unfamiliar distributions of the environment feedback with an upward entropy trend. As training progresses, self-imitation gets strengthened to exploit existing successful patterns from replayed experiences for comparative action-level exploration, accelerating solution iteration without unbounded entropy growth. To further stabilize training, we recalibrate the advantages of experiences in the replay buffer to address the potential policy drift. Reugularizations such as the clipping of tokens with high covariance between probability and advantage are introduced to the trajectory-level entropy control to curb over-confidence.
AgentNet: Decentralized Evolutionary Coordination for LLM-based Multi-Agent Systems
Apr 01, 2025The rapid advancement of Large Language Models (LLMs) has catalyzed the development of multi-agent systems, where multiple LLM-based agents collaborate to solve complex tasks. However, existing systems predominantly rely on centralized coordination, which introduces scalability bottlenecks, limits adaptability, and creates single points of failure. Additionally, concerns over privacy and proprietary knowledge sharing hinder cross-organizational collaboration, leading to siloed expertise. To address these challenges, we propose AgentNet, a decentralized, Retrieval-Augmented Generation (RAG)-based framework that enables LLM-based agents to autonomously evolve their capabilities and collaborate efficiently in a Directed Acyclic Graph (DAG)-structured network. Unlike traditional multi-agent systems that depend on static role assignments or centralized control, AgentNet allows agents to specialize dynamically, adjust their connectivity, and route tasks without relying on predefined workflows. AgentNet's core design is built upon several key innovations: (1) Fully Decentralized Paradigm: Removing the central orchestrator, allowing agents to coordinate and specialize autonomously, fostering fault tolerance and emergent collective intelligence. (2) Dynamically Evolving Graph Topology: Real-time adaptation of agent connections based on task demands, ensuring scalability and resilience.(3) Adaptive Learning for Expertise Refinement: A retrieval-based memory system that enables agents to continuously update and refine their specialized skills. By eliminating centralized control, AgentNet enhances fault tolerance, promotes scalable specialization, and enables privacy-preserving collaboration across organizations. Through decentralized coordination and minimal data exchange, agents can leverage diverse knowledge sources while safeguarding sensitive information.
CodeGRAG: Extracting Composed Syntax Graphs for Retrieval Augmented Cross-Lingual Code Generation
May 03, 2024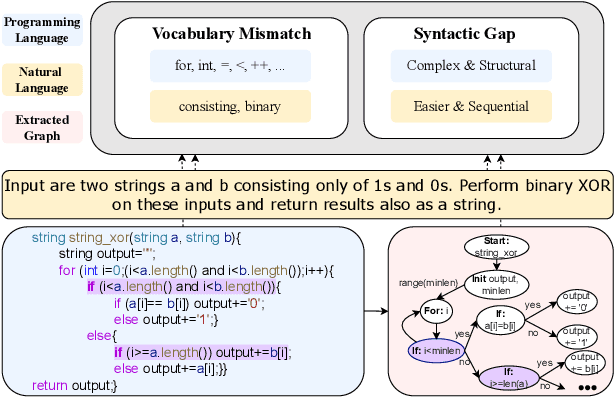
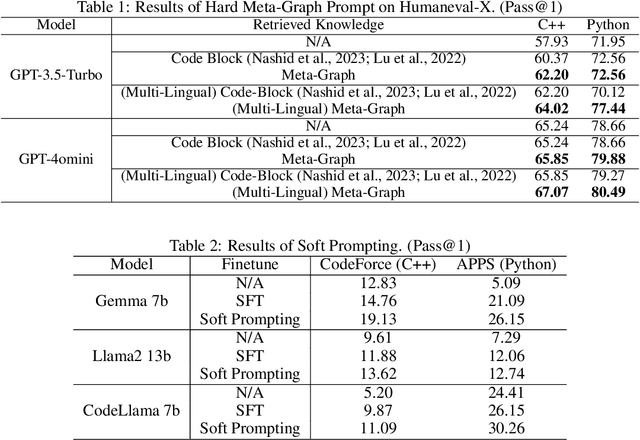
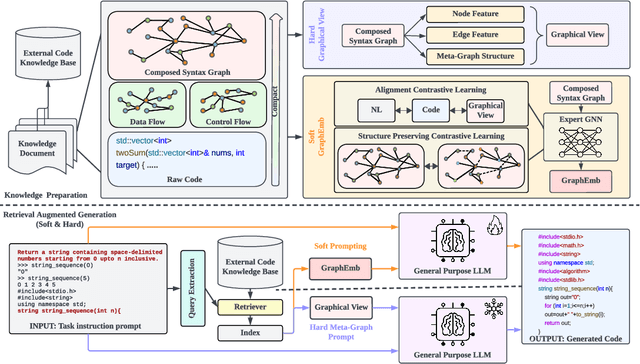
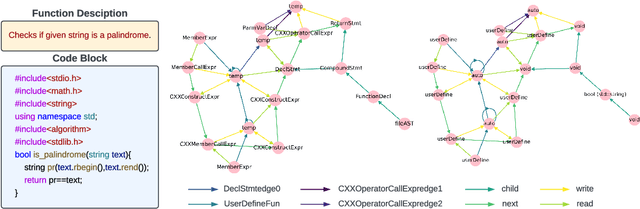
Utilizing large language models to generate codes has shown promising meaning in software development revolution. Despite the intelligence shown by the general large language models, their specificity in code generation can still be improved due to the syntactic gap and mismatched vocabulary existing among natural language and different programming languages. In addition, programming languages are inherently logical and complex, making them hard to be correctly generated. Existing methods rely on multiple prompts to the large language model to explore better solutions, which is expensive. In this paper, we propose Syntax Graph Retrieval Augmented Code Generation (CodeGRAG) to enhance the performance of LLMs in single-round code generation tasks. CodeGRAG extracts and summarizes the control flow and data flow of code blocks to fill the gap between programming languages and natural language. The extracted external structural knowledge models the inherent flows of code blocks, which can facilitate LLMs for better understanding of code syntax and serve as a bridge among different programming languages. CodeGRAG significantly improves the code generation ability of LLMs and can even offer performance gain for cross-lingual code generation, e.g., C++ for Python.
CodeApex: A Bilingual Programming Evaluation Benchmark for Large Language Models
Sep 10, 2023



With the emergence of Large Language Models (LLMs), there has been a significant improvement in the programming capabilities of models, attracting growing attention from researchers. We propose CodeApex, a bilingual benchmark dataset focusing on the programming comprehension and code generation abilities of LLMs. CodeApex comprises three types of multiple-choice questions: conceptual understanding, commonsense reasoning, and multi-hop reasoning, designed to evaluate LLMs on programming comprehension tasks. Additionally, CodeApex utilizes algorithmic questions and corresponding test cases to assess the code quality generated by LLMs. We evaluate 14 state-of-the-art LLMs, including both general-purpose and specialized models. GPT exhibits the best programming capabilities, achieving approximate accuracies of 50% and 56% on the two tasks, respectively. There is still significant room for improvement in programming tasks. We hope that CodeApex can serve as a reference for evaluating the coding capabilities of LLMs, further promoting their development and growth. Datasets are released at https://github.com/APEXLAB/CodeApex.git. CodeApex submission website is https://apex.sjtu.edu.cn/codeapex/.
Who to Watch Next: Two-side Interactive Networks for Live Broadcast Recommendation
Feb 09, 2022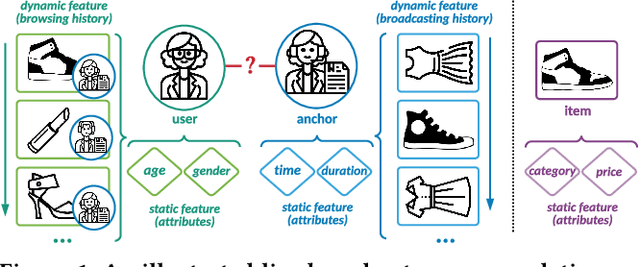
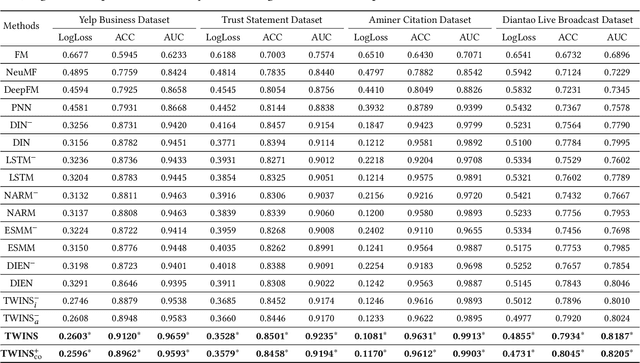
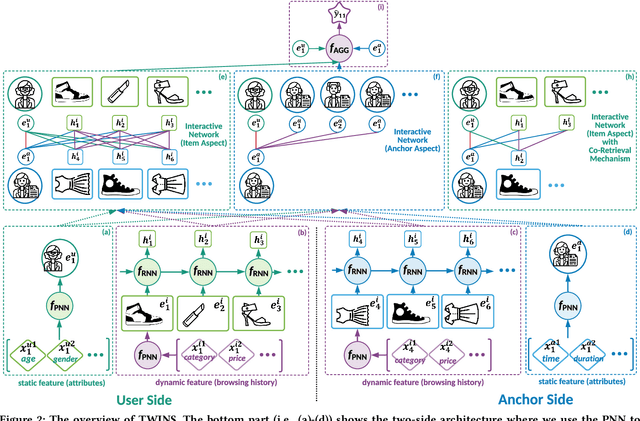

With the prevalence of live broadcast business nowadays, a new type of recommendation service, called live broadcast recommendation, is widely used in many mobile e-commerce Apps. Different from classical item recommendation, live broadcast recommendation is to automatically recommend user anchors instead of items considering the interactions among triple-objects (i.e., users, anchors, items) rather than binary interactions between users and items. Existing methods based on binary objects, ranging from early matrix factorization to recently emerged deep learning, obtain objects' embeddings by mapping from pre-existing features. Directly applying these techniques would lead to limited performance, as they are failing to encode collaborative signals among triple-objects. In this paper, we propose a novel TWo-side Interactive NetworkS (TWINS) for live broadcast recommendation. In order to fully use both static and dynamic information on user and anchor sides, we combine a product-based neural network with a recurrent neural network to learn the embedding of each object. In addition, instead of directly measuring the similarity, TWINS effectively injects the collaborative effects into the embedding process in an explicit manner by modeling interactive patterns between the user's browsing history and the anchor's broadcast history in both item and anchor aspects. Furthermore, we design a novel co-retrieval technique to select key items among massive historic records efficiently. Offline experiments on real large-scale data show the superior performance of the proposed TWINS, compared to representative methods; and further results of online experiments on Diantao App show that TWINS gains average performance improvement of around 8% on ACTR metric, 3% on UCTR metric, 3.5% on UCVR metric.