 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe AI Hippocampus: How Far are We From Human Memory?
Jan 14, 2026Memory plays a foundational role in augmenting the reasoning, adaptability, and contextual fidelity of modern Large Language Models and Multi-Modal LLMs. As these models transition from static predictors to interactive systems capable of continual learning and personalized inference, the incorporation of memory mechanisms has emerged as a central theme in their architectural and functional evolution. This survey presents a comprehensive and structured synthesis of memory in LLMs and MLLMs, organizing the literature into a cohesive taxonomy comprising implicit, explicit, and agentic memory paradigms. Specifically, the survey delineates three primary memory frameworks. Implicit memory refers to the knowledge embedded within the internal parameters of pre-trained transformers, encompassing their capacity for memorization, associative retrieval, and contextual reasoning. Recent work has explored methods to interpret, manipulate, and reconfigure this latent memory. Explicit memory involves external storage and retrieval components designed to augment model outputs with dynamic, queryable knowledge representations, such as textual corpora, dense vectors, and graph-based structures, thereby enabling scalable and updatable interaction with information sources. Agentic memory introduces persistent, temporally extended memory structures within autonomous agents, facilitating long-term planning, self-consistency, and collaborative behavior in multi-agent systems, with relevance to embodied and interactive AI. Extending beyond text, the survey examines the integration of memory within multi-modal settings, where coherence across vision, language, audio, and action modalities is essential. Key architectural advances, benchmark tasks, and open challenges are discussed, including issues related to memory capacity, alignment, factual consistency, and cross-system interoperability.
A Survey of AI Agent Protocols
Apr 23, 2025The rapid development of large language models (LLMs) has led to the widespread deployment of LLM agents across diverse industries, including customer service, content generation, data analysis, and even healthcare. However, as more LLM agents are deployed, a major issue has emerged: there is no standard way for these agents to communicate with external tools or data sources. This lack of standardized protocols makes it difficult for agents to work together or scale effectively, and it limits their ability to tackle complex, real-world tasks. A unified communication protocol for LLM agents could change this. It would allow agents and tools to interact more smoothly, encourage collaboration, and triggering the formation of collective intelligence. In this paper, we provide a systematic overview of existing communication protocols for LLM agents. We classify them into four main categories and make an analysis to help users and developers select the most suitable protocols for specific applications. Additionally, we conduct a comparative performance analysis of these protocols across key dimensions such as security, scalability, and latency. Finally, we explore future challenges, such as how protocols can adapt and survive in fast-evolving environments, and what qualities future protocols might need to support the next generation of LLM agent ecosystems. We expect this work to serve as a practical reference for both researchers and engineers seeking to design, evaluate, or integrate robust communication infrastructures for intelligent agents.
AgentNet: Decentralized Evolutionary Coordination for LLM-based Multi-Agent Systems
Apr 01, 2025The rapid advancement of Large Language Models (LLMs) has catalyzed the development of multi-agent systems, where multiple LLM-based agents collaborate to solve complex tasks. However, existing systems predominantly rely on centralized coordination, which introduces scalability bottlenecks, limits adaptability, and creates single points of failure. Additionally, concerns over privacy and proprietary knowledge sharing hinder cross-organizational collaboration, leading to siloed expertise. To address these challenges, we propose AgentNet, a decentralized, Retrieval-Augmented Generation (RAG)-based framework that enables LLM-based agents to autonomously evolve their capabilities and collaborate efficiently in a Directed Acyclic Graph (DAG)-structured network. Unlike traditional multi-agent systems that depend on static role assignments or centralized control, AgentNet allows agents to specialize dynamically, adjust their connectivity, and route tasks without relying on predefined workflows. AgentNet's core design is built upon several key innovations: (1) Fully Decentralized Paradigm: Removing the central orchestrator, allowing agents to coordinate and specialize autonomously, fostering fault tolerance and emergent collective intelligence. (2) Dynamically Evolving Graph Topology: Real-time adaptation of agent connections based on task demands, ensuring scalability and resilience.(3) Adaptive Learning for Expertise Refinement: A retrieval-based memory system that enables agents to continuously update and refine their specialized skills. By eliminating centralized control, AgentNet enhances fault tolerance, promotes scalable specialization, and enables privacy-preserving collaboration across organizations. Through decentralized coordination and minimal data exchange, agents can leverage diverse knowledge sources while safeguarding sensitive information.
Differentiable Information Enhanced Model-Based Reinforcement Learning
Mar 03, 2025Differentiable environments have heralded new possibilities for learning control policies by offering rich differentiable information that facilitates gradient-based methods. In comparison to prevailing model-free reinforcement learning approaches, model-based reinforcement learning (MBRL) methods exhibit the potential to effectively harness the power of differentiable information for recovering the underlying physical dynamics. However, this presents two primary challenges: effectively utilizing differentiable information to 1) construct models with more accurate dynamic prediction and 2) enhance the stability of policy training. In this paper, we propose a Differentiable Information Enhanced MBRL method, MB-MIX, to address both challenges. Firstly, we adopt a Sobolev model training approach that penalizes incorrect model gradient outputs, enhancing prediction accuracy and yielding more precise models that faithfully capture system dynamics. Secondly, we introduce mixing lengths of truncated learning windows to reduce the variance in policy gradient estimation, resulting in improved stability during policy learning. To validate the effectiveness of our approach in differentiable environments, we provide theoretical analysis and empirical results. Notably, our approach outperforms previous model-based and model-free methods, in multiple challenging tasks involving controllable rigid robots such as humanoid robots' motion control and deformable object manipulation.
MMKE-Bench: A Multimodal Editing Benchmark for Diverse Visual Knowledge
Feb 27, 2025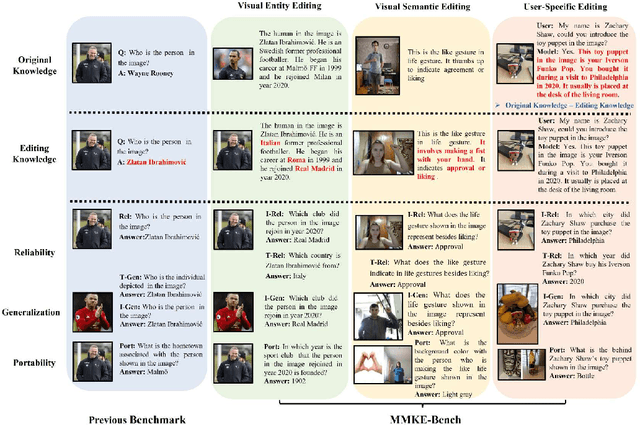

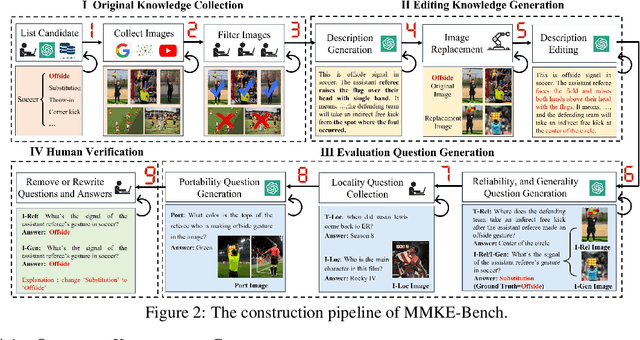
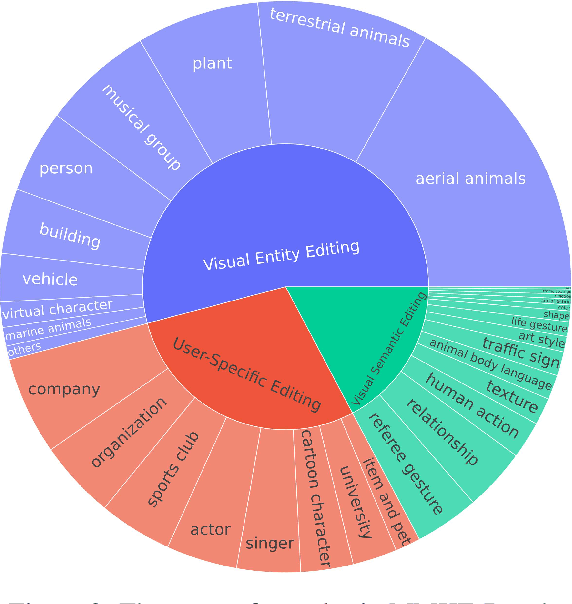
Knowledge editing techniques have emerged as essential tools for updating the factual knowledge of large language models (LLMs) and multimodal models (LMMs), allowing them to correct outdated or inaccurate information without retraining from scratch. However, existing benchmarks for multimodal knowledge editing primarily focus on entity-level knowledge represented as simple triplets, which fail to capture the complexity of real-world multimodal information. To address this issue, we introduce MMKE-Bench, a comprehensive MultiModal Knowledge Editing Benchmark, designed to evaluate the ability of LMMs to edit diverse visual knowledge in real-world scenarios. MMKE-Bench addresses these limitations by incorporating three types of editing tasks: visual entity editing, visual semantic editing, and user-specific editing. Besides, MMKE-Bench uses free-form natural language to represent and edit knowledge, offering a more flexible and effective format. The benchmark consists of 2,940 pieces of knowledge and 8,363 images across 33 broad categories, with evaluation questions automatically generated and human-verified. We assess five state-of-the-art knowledge editing methods on three prominent LMMs, revealing that no method excels across all criteria, and that visual and user-specific edits are particularly challenging. MMKE-Bench sets a new standard for evaluating the robustness of multimodal knowledge editing techniques, driving progress in this rapidly evolving field.
AdaSociety: An Adaptive Environment with Social Structures for Multi-Agent Decision-Making
Nov 06, 2024Traditional interactive environments limit agents' intelligence growth with fixed tasks. Recently, single-agent environments address this by generating new tasks based on agent actions, enhancing task diversity. We consider the decision-making problem in multi-agent settings, where tasks are further influenced by social connections, affecting rewards and information access. However, existing multi-agent environments lack a combination of adaptive physical surroundings and social connections, hindering the learning of intelligent behaviors. To address this, we introduce AdaSociety, a customizable multi-agent environment featuring expanding state and action spaces, alongside explicit and alterable social structures. As agents progress, the environment adaptively generates new tasks with social structures for agents to undertake. In AdaSociety, we develop three mini-games showcasing distinct social structures and tasks. Initial results demonstrate that specific social structures can promote both individual and collective benefits, though current reinforcement learning and LLM-based algorithms show limited effectiveness in leveraging social structures to enhance performance. Overall, AdaSociety serves as a valuable research platform for exploring intelligence in diverse physical and social settings. The code is available at https://github.com/bigai-ai/AdaSociety.
Learning to Balance Altruism and Self-interest Based on Empathy in Mixed-Motive Games
Oct 10, 2024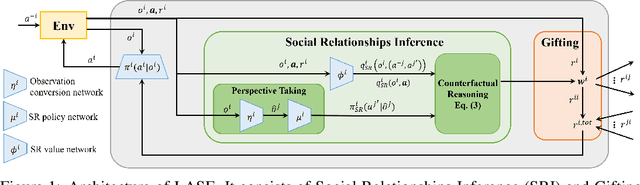



Real-world multi-agent scenarios often involve mixed motives, demanding altruistic agents capable of self-protection against potential exploitation. However, existing approaches often struggle to achieve both objectives. In this paper, based on that empathic responses are modulated by inferred social relationships between agents, we propose LASE Learning to balance Altruism and Self-interest based on Empathy), a distributed multi-agent reinforcement learning algorithm that fosters altruistic cooperation through gifting while avoiding exploitation by other agents in mixed-motive games. LASE allocates a portion of its rewards to co-players as gifts, with this allocation adapting dynamically based on the social relationship -- a metric evaluating the friendliness of co-players estimated by counterfactual reasoning. In particular, social relationship measures each co-player by comparing the estimated $Q$-function of current joint action to a counterfactual baseline which marginalizes the co-player's action, with its action distribution inferred by a perspective-taking module. Comprehensive experiments are performed in spatially and temporally extended mixed-motive games, demonstrating LASE's ability to promote group collaboration without compromising fairness and its capacity to adapt policies to various types of interactive co-players.
A Contextual Combinatorial Bandit Approach to Negotiation
Jun 30, 2024



Learning effective negotiation strategies poses two key challenges: the exploration-exploitation dilemma and dealing with large action spaces. However, there is an absence of learning-based approaches that effectively address these challenges in negotiation. This paper introduces a comprehensive formulation to tackle various negotiation problems. Our approach leverages contextual combinatorial multi-armed bandits, with the bandits resolving the exploration-exploitation dilemma, and the combinatorial nature handles large action spaces. Building upon this formulation, we introduce NegUCB, a novel method that also handles common issues such as partial observations and complex reward functions in negotiation. NegUCB is contextual and tailored for full-bandit feedback without constraints on the reward functions. Under mild assumptions, it ensures a sub-linear regret upper bound. Experiments conducted on three negotiation tasks demonstrate the superiority of our approach.
In-Context Editing: Learning Knowledge from Self-Induced Distributions
Jun 17, 2024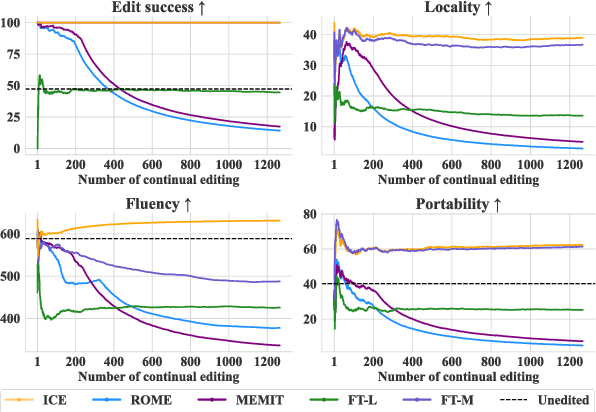
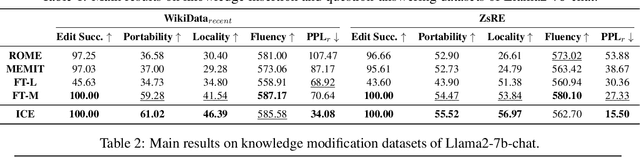
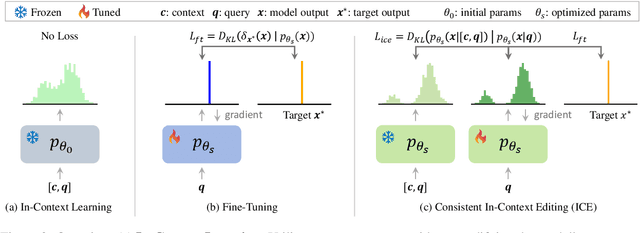
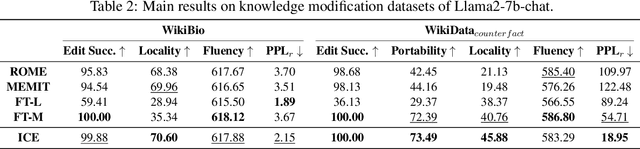
The existing fine-tuning paradigm for language models is brittle in knowledge editing scenarios, where the model must incorporate new information without extensive retraining. This brittleness often results in overfitting, reduced performance, and unnatural language generation. To address this, we propose Consistent In-Context Editing (ICE), a novel approach that leverages the model's in-context learning capability to tune toward a contextual distribution rather than a one-hot target. ICE introduces a straightforward optimization framework that includes both a target and a procedure, enhancing the robustness and effectiveness of gradient-based tuning methods. We provide analytical insights into ICE across four critical aspects of knowledge editing: accuracy, locality, generalization, and linguistic quality, showing its advantages. Experimental results across four datasets confirm the effectiveness of ICE and demonstrate its potential for continual editing, ensuring that updated information is incorporated while preserving the integrity of the model.
Panacea: Pareto Alignment via Preference Adaptation for LLMs
Feb 03, 2024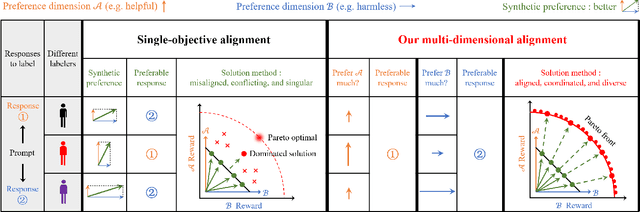



Current methods for large language model alignment typically use scalar human preference labels. However, this convention tends to oversimplify the multi-dimensional and heterogeneous nature of human preferences, leading to reduced expressivity and even misalignment. This paper presents Panacea, an innovative approach that reframes alignment as a multi-dimensional preference optimization problem. Panacea trains a single model capable of adapting online and Pareto-optimally to diverse sets of preferences without the need for further tuning. A major challenge here is using a low-dimensional preference vector to guide the model's behavior, despite it being governed by an overwhelmingly large number of parameters. To address this, Panacea is designed to use singular value decomposition (SVD)-based low-rank adaptation, which allows the preference vector to be simply injected online as singular values. Theoretically, we prove that Panacea recovers the entire Pareto front with common loss aggregation methods under mild conditions. Moreover, our experiments demonstrate, for the first time, the feasibility of aligning a single LLM to represent a spectrum of human preferences through various optimization methods. Our work marks a step forward in effectively and efficiently aligning models to diverse and intricate human preferences in a controllable and Pareto-optimal manner.