 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuroCon: Benchmarking Parliament Deliberation for Political Consensus Finding
May 26, 2025Achieving political consensus is crucial yet challenging for the effective functioning of social governance. However, although frontier AI systems represented by large language models (LLMs) have developed rapidly in recent years, their capabilities on this scope are still understudied. In this paper, we introduce EuroCon, a novel benchmark constructed from 2,225 high-quality deliberation records of the European Parliament over 13 years, ranging from 2009 to 2022, to evaluate the ability of LLMs to reach political consensus among divergent party positions across diverse parliament settings. Specifically, EuroCon incorporates four factors to build each simulated parliament setting: specific political issues, political goals, participating parties, and power structures based on seat distribution. We also develop an evaluation framework for EuroCon to simulate real voting outcomes in different parliament settings, assessing whether LLM-generated resolutions meet predefined political goals. Our experimental results demonstrate that even state-of-the-art models remain undersatisfied with complex tasks like passing resolutions by a two-thirds majority and addressing security issues, while revealing some common strategies LLMs use to find consensus under different power structures, such as prioritizing the stance of the dominant party, highlighting EuroCon's promise as an effective platform for studying LLMs' ability to find political consensus.
Amulet: ReAlignment During Test Time for Personalized Preference Adaptation of LLMs
Feb 26, 2025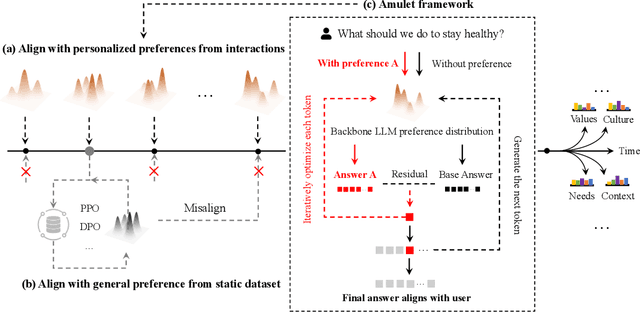
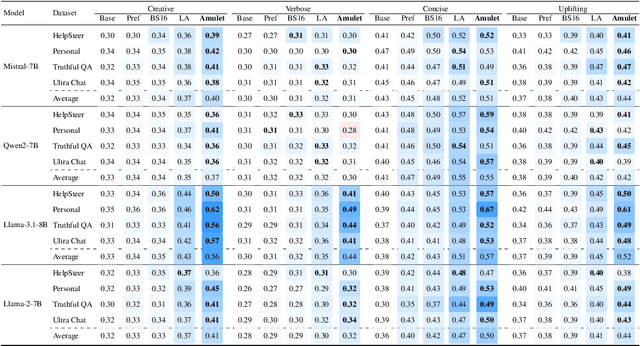
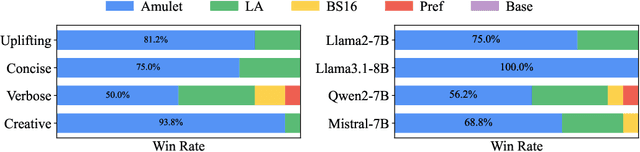

How to align large language models (LLMs) with user preferences from a static general dataset has been frequently studied. However, user preferences are usually personalized, changing, and diverse regarding culture, values, or time. This leads to the problem that the actual user preferences often do not coincide with those trained by the model developers in the practical use of LLMs. Since we cannot collect enough data and retrain for every demand, researching efficient real-time preference adaptation methods based on the backbone LLMs during test time is important. To this end, we introduce Amulet, a novel, training-free framework that formulates the decoding process of every token as a separate online learning problem with the guidance of simple user-provided prompts, thus enabling real-time optimization to satisfy users' personalized preferences. To reduce the computational cost brought by this optimization process for each token, we additionally provide a closed-form solution for each iteration step of the optimization process, thereby reducing the computational time cost to a negligible level. The detailed experimental results demonstrate that Amulet can achieve significant performance improvements in rich settings with combinations of different LLMs, datasets, and user preferences, while maintaining acceptable computational efficiency.
Magnetic Preference Optimization: Achieving Last-iterate Convergence for Language Models Alignment
Oct 22, 2024



Self-play methods have demonstrated remarkable success in enhancing model capabilities across various domains. In the context of Reinforcement Learning from Human Feedback (RLHF), self-play not only boosts Large Language Model (LLM) performance but also overcomes the limitations of traditional Bradley-Terry (BT) model assumptions by finding the Nash equilibrium (NE) of a preference-based, two-player constant-sum game. However, existing methods either guarantee only average-iterate convergence, incurring high storage and inference costs, or converge to the NE of a regularized game, failing to accurately reflect true human preferences. In this paper, we introduce Magnetic Preference Optimization (MPO), a novel approach capable of achieving last-iterate convergence to the NE of the original game, effectively overcoming the limitations of existing methods. Building upon Magnetic Mirror Descent (MMD), MPO attains a linear convergence rate, making it particularly suitable for fine-tuning LLMs. To ensure our algorithm is both theoretically sound and practically viable, we present a simple yet effective implementation that adapts the theoretical insights to the RLHF setting. Empirical results demonstrate that MPO can significantly enhance the performance of LLMs, highlighting the potential of self-play methods in alignment.
Efficient Model-agnostic Alignment via Bayesian Persuasion
May 29, 2024With recent advancements in large language models (LLMs), alignment has emerged as an effective technique for keeping LLMs consensus with human intent. Current methods primarily involve direct training through Supervised Fine-tuning (SFT) or Reinforcement Learning from Human Feedback (RLHF), both of which require substantial computational resources and extensive ground truth data. This paper explores an efficient method for aligning black-box large models using smaller models, introducing a model-agnostic and lightweight Bayesian Persuasion Alignment framework. We formalize this problem as an optimization of the signaling strategy from the small model's perspective. In the persuasion process, the small model (Advisor) observes the information item (i.e., state) and persuades large models (Receiver) to elicit improved responses. The Receiver then generates a response based on the input, the signal from the Advisor, and its updated belief about the information item. Through training using our framework, we demonstrate that the Advisor can significantly enhance the performance of various Receivers across a range of tasks. We theoretically analyze our persuasion framework and provide an upper bound on the Advisor's regret, confirming its effectiveness in learning the optimal signaling strategy. Our Empirical results demonstrates that GPT-2 can significantly improve the performance of various models, achieving an average enhancement of 16.1% in mathematical reasoning ability and 13.7% in code generation. We hope our work can provide an initial step toward rethinking the alignment framework from the Bayesian Persuasion perspective.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Incentive Compatibility for AI Alignment in Sociotechnical Systems: Positions and Prospects
Mar 01, 2024

The burgeoning integration of artificial intelligence (AI) into human society brings forth significant implications for societal governance and safety. While considerable strides have been made in addressing AI alignment challenges, existing methodologies primarily focus on technical facets, often neglecting the intricate sociotechnical nature of AI systems, which can lead to a misalignment between the development and deployment contexts. To this end, we posit a new problem worth exploring: Incentive Compatibility Sociotechnical Alignment Problem (ICSAP). We hope this can call for more researchers to explore how to leverage the principles of Incentive Compatibility (IC) from game theory to bridge the gap between technical and societal components to maintain AI consensus with human societies in different contexts. We further discuss three classical game problems for achieving IC: mechanism design, contract theory, and Bayesian persuasion, in addressing the perspectives, potentials, and challenges of solving ICSAP, and provide preliminary implementation conceptions.
CivRealm: A Learning and Reasoning Odyssey in Civilization for Decision-Making Agents
Jan 19, 2024



The generalization of decision-making agents encompasses two fundamental elements: learning from past experiences and reasoning in novel contexts. However, the predominant emphasis in most interactive environments is on learning, often at the expense of complexity in reasoning. In this paper, we introduce CivRealm, an environment inspired by the Civilization game. Civilization's profound alignment with human history and society necessitates sophisticated learning, while its ever-changing situations demand strong reasoning to generalize. Particularly, CivRealm sets up an imperfect-information general-sum game with a changing number of players; it presents a plethora of complex features, challenging the agent to deal with open-ended stochastic environments that require diplomacy and negotiation skills. Within CivRealm, we provide interfaces for two typical agent types: tensor-based agents that focus on learning, and language-based agents that emphasize reasoning. To catalyze further research, we present initial results for both paradigms. The canonical RL-based agents exhibit reasonable performance in mini-games, whereas both RL- and LLM-based agents struggle to make substantial progress in the full game. Overall, CivRealm stands as a unique learning and reasoning challenge for decision-making agents. The code is available at https://github.com/bigai-ai/civrealm.
AI Alignment: A Comprehensive Survey
Nov 01, 2023AI alignment aims to make AI systems behave in line with human intentions and values. As AI systems grow more capable, the potential large-scale risks associated with misaligned AI systems become salient. Hundreds of AI experts and public figures have expressed concerns about AI risks, arguing that "mitigating the risk of extinction from AI should be a global priority, alongside other societal-scale risks such as pandemics and nuclear war". To provide a comprehensive and up-to-date overview of the alignment field, in this survey paper, we delve into the core concepts, methodology, and practice of alignment. We identify the RICE principles as the key objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality. Guided by these four principles, we outline the landscape of current alignment research and decompose them into two key components: forward alignment and backward alignment. The former aims to make AI systems aligned via alignment training, while the latter aims to gain evidence about the systems' alignment and govern them appropriately to avoid exacerbating misalignment risks. Forward alignment and backward alignment form a recurrent process where the alignment of AI systems from the forward process is verified in the backward process, meanwhile providing updated objectives for forward alignment in the next round. On forward alignment, we discuss learning from feedback and learning under distribution shift. On backward alignment, we discuss assurance techniques and governance practices that apply to every stage of AI systems' lifecycle. We also release and continually update the website (www.alignmentsurvey.com) which features tutorials, collections of papers, blog posts, and other resources.
Measuring Value Understanding in Language Models through Discriminator-Critique Gap
Oct 19, 2023Recent advancements in Large Language Models (LLMs) have heightened concerns about their potential misalignment with human values. However, evaluating their grasp of these values is complex due to their intricate and adaptable nature. We argue that truly understanding values in LLMs requires considering both "know what" and "know why". To this end, we present the Value Understanding Measurement (VUM) framework that quantitatively assesses both "know what" and "know why" by measuring the discriminator-critique gap related to human values. Using the Schwartz Value Survey, we specify our evaluation values and develop a thousand-level dialogue dataset with GPT-4. Our assessment looks at both the value alignment of LLM's outputs compared to baseline answers and how LLM responses align with reasons for value recognition versus GPT-4's annotations. We evaluate five representative LLMs and provide strong evidence that the scaling law significantly impacts "know what" but not much on "know why", which has consistently maintained a high level. This may further suggest that LLMs might craft plausible explanations based on the provided context without truly understanding their inherent value, indicating potential risks.
ProAgent: Building Proactive Cooperative AI with Large Language Models
Aug 28, 2023


Building AIs with adaptive behaviors in human-AI cooperation stands as a pivotal focus in AGI research. Current methods for developing cooperative agents predominantly rely on learning-based methods, where policy generalization heavily hinges on past interactions with specific teammates. These approaches constrain the agent's capacity to recalibrate its strategy when confronted with novel teammates. We propose \textbf{ProAgent}, a novel framework that harnesses large language models (LLMs) to fashion a \textit{pro}active \textit{agent} empowered with the ability to anticipate teammates' forthcoming decisions and formulate enhanced plans for itself. ProAgent excels at cooperative reasoning with the capacity to dynamically adapt its behavior to enhance collaborative efforts with teammates. Moreover, the ProAgent framework exhibits a high degree of modularity and interpretability, facilitating seamless integration to address a wide array of coordination scenarios. Experimental evaluations conducted within the framework of \textit{Overcook-AI} unveil the remarkable performance superiority of ProAgent, outperforming five methods based on self-play and population-based training in cooperation with AI agents. Further, when cooperating with human proxy models, its performance exhibits an average improvement exceeding 10\% compared to the current state-of-the-art, COLE. The advancement was consistently observed across diverse scenarios involving interactions with both AI agents of varying characteristics and human counterparts. These findings inspire future research for human-robot collaborations. For a hands-on demonstration, please visit \url{https://pku-proagent.github.io}.