 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Editing: Learning Knowledge from Self-Induced Distributions
Jun 17, 2024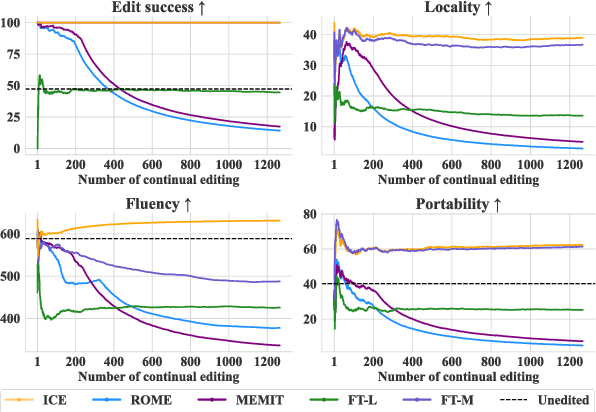
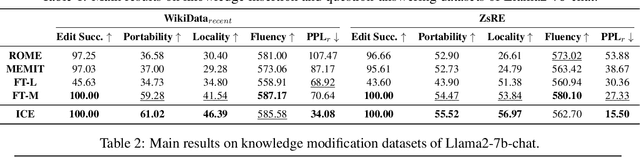
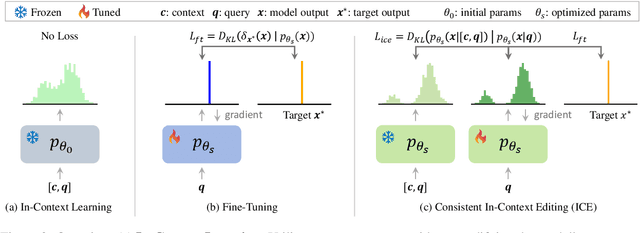
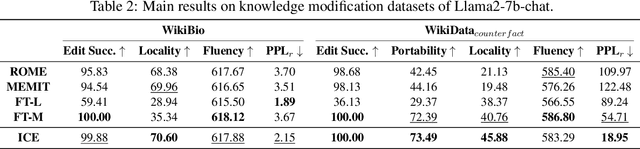
The existing fine-tuning paradigm for language models is brittle in knowledge editing scenarios, where the model must incorporate new information without extensive retraining. This brittleness often results in overfitting, reduced performance, and unnatural language generation. To address this, we propose Consistent In-Context Editing (ICE), a novel approach that leverages the model's in-context learning capability to tune toward a contextual distribution rather than a one-hot target. ICE introduces a straightforward optimization framework that includes both a target and a procedure, enhancing the robustness and effectiveness of gradient-based tuning methods. We provide analytical insights into ICE across four critical aspects of knowledge editing: accuracy, locality, generalization, and linguistic quality, showing its advantages. Experimental results across four datasets confirm the effectiveness of ICE and demonstrate its potential for continual editing, ensuring that updated information is incorporated while preserving the integrity of the model.
CivRealm: A Learning and Reasoning Odyssey in Civilization for Decision-Making Agents
Jan 19, 2024



The generalization of decision-making agents encompasses two fundamental elements: learning from past experiences and reasoning in novel contexts. However, the predominant emphasis in most interactive environments is on learning, often at the expense of complexity in reasoning. In this paper, we introduce CivRealm, an environment inspired by the Civilization game. Civilization's profound alignment with human history and society necessitates sophisticated learning, while its ever-changing situations demand strong reasoning to generalize. Particularly, CivRealm sets up an imperfect-information general-sum game with a changing number of players; it presents a plethora of complex features, challenging the agent to deal with open-ended stochastic environments that require diplomacy and negotiation skills. Within CivRealm, we provide interfaces for two typical agent types: tensor-based agents that focus on learning, and language-based agents that emphasize reasoning. To catalyze further research, we present initial results for both paradigms. The canonical RL-based agents exhibit reasonable performance in mini-games, whereas both RL- and LLM-based agents struggle to make substantial progress in the full game. Overall, CivRealm stands as a unique learning and reasoning challenge for decision-making agents. The code is available at https://github.com/bigai-ai/civrealm.