 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO: Towards Emotionally Appropriate and Contextually Aware Interactive Head Generation
Mar 18, 2026In natural face-to-face interaction, participants seamlessly alternate between speaking and listening, producing facial behaviors (FBs) that are finely informed by long-range context and naturally exhibit contextual appropriateness and emotional rationality. Interactive Head Generation (IHG) aims to synthesize lifelike avatar head video emulating such capabilities. Existing IHG methods typically condition on dual-track signals (i.e., human user's behaviors and pre-defined audio for avatar) within a short temporal window, jointly driving generation of avatar's audio-aligned lip articulation and non-verbal FBs. However, two main challenges persist in these methods: (i) the reliance on short-clip behavioral cues without long-range contextual modeling leads them to produce facial behaviors lacking contextual appropriateness; and (ii) the entangled, role-agnostic fusion of dual-track signals empirically introduces cross-signal interference, potentially compromising lip-region synchronization during speaking. To this end, we propose ECHO, a novel IHG framework comprising two key components: a Long-range Contextual Understanding (LCU) component that facilitates contextual understanding of both behavior-grounded dynamics and linguistic-driven affective semantics to promote contextual appropriateness and emotional rationality of synthesized avatar FBs; and a block-wise Spatial-aware Decoupled Cross-attention Modulation (SDCM) module, that preserves self-audio-driven lip articulation while adaptively integrating user contextual behavioral cues for non-lip facial regions, complemented by our designed two-stage training paradigm, to jointly enhance lip synchronization and visual fidelity. Extensive experiments demonstrate the effectiveness of proposed components and ECHO's superior IHG performance.
LLM-Confidence Reranker: A Training-Free Approach for Enhancing Retrieval-Augmented Generation Systems
Feb 14, 2026Large language models (LLMs) have revolutionized natural language processing, yet hallucinations in knowledge-intensive tasks remain a critical challenge. Retrieval-augmented generation (RAG) addresses this by integrating external knowledge, but its efficacy depends on accurate document retrieval and ranking. Although existing rerankers demonstrate effectiveness, they frequently necessitate specialized training, impose substantial computational expenses, and fail to fully exploit the semantic capabilities of LLMs, particularly their inherent confidence signals. We propose the LLM-Confidence Reranker (LCR), a training-free, plug-and-play algorithm that enhances reranking in RAG systems by leveraging black-box LLM confidence derived from Maximum Semantic Cluster Proportion (MSCP). LCR employs a two-stage process: confidence assessment via multinomial sampling and clustering, followed by binning and multi-level sorting based on query and document confidence thresholds. This approach prioritizes relevant documents while preserving original rankings for high-confidence queries, ensuring robustness. Evaluated on BEIR and TREC benchmarks with BM25 and Contriever retrievers, LCR--using only 7--9B-parameter pre-trained LLMs--consistently improves NDCG@5 by up to 20.6% across pre-trained LLM and fine-tuned Transformer rerankers, without degradation. Ablation studies validate the hypothesis that LLM confidence positively correlates with document relevance, elucidating LCR's mechanism. LCR offers computational efficiency, parallelism for scalability, and broad compatibility, mitigating hallucinations in applications like medical diagnosis.
* Published by ESWA
Less is More for RAG: Information Gain Pruning for Generator-Aligned Reranking and Evidence Selection
Jan 24, 2026Retrieval-augmented generation (RAG) grounds large language models with external evidence, but under a limited context budget, the key challenge is deciding which retrieved passages should be injected. We show that retrieval relevance metrics (e.g., NDCG) correlate weakly with end-to-end QA quality and can even become negatively correlated under multi-passage injection, where redundancy and mild conflicts destabilize generation. We propose \textbf{Information Gain Pruning (IGP)}, a deployment-friendly reranking-and-pruning module that selects evidence using a generator-aligned utility signal and filters weak or harmful passages before truncation, without changing existing budget interfaces. Across five open-domain QA benchmarks and multiple retrievers and generators, IGP consistently improves the quality--cost trade-off. In a representative multi-evidence setting, IGP delivers about +12--20% relative improvement in average F1 while reducing final-stage input tokens by roughly 76--79% compared to retriever-only baselines.
UGOD: Uncertainty-Guided Differentiable Opacity and Soft Dropout for Enhanced Sparse-View 3DGS
Aug 07, 20253D Gaussian Splatting (3DGS) has become a competitive approach for novel view synthesis (NVS) due to its advanced rendering efficiency through 3D Gaussian projection and blending. However, Gaussians are treated equally weighted for rendering in most 3DGS methods, making them prone to overfitting, which is particularly the case in sparse-view scenarios. To address this, we investigate how adaptive weighting of Gaussians affects rendering quality, which is characterised by learned uncertainties proposed. This learned uncertainty serves two key purposes: first, it guides the differentiable update of Gaussian opacity while preserving the 3DGS pipeline integrity; second, the uncertainty undergoes soft differentiable dropout regularisation, which strategically transforms the original uncertainty into continuous drop probabilities that govern the final Gaussian projection and blending process for rendering. Extensive experimental results over widely adopted datasets demonstrate that our method outperforms rivals in sparse-view 3D synthesis, achieving higher quality reconstruction with fewer Gaussians in most datasets compared to existing sparse-view approaches, e.g., compared to DropGaussian, our method achieves 3.27\% PSNR improvements on the MipNeRF 360 dataset.
Learning Personalised Human Internal Cognition from External Expressive Behaviours for Real Personality Recognition
Jul 31, 2025



Automatic real personality recognition (RPR) aims to evaluate human real personality traits from their expressive behaviours. However, most existing solutions generally act as external observers to infer observers' personality impressions based on target individuals' expressive behaviours, which significantly deviate from their real personalities and consistently lead to inferior recognition performance. Inspired by the association between real personality and human internal cognition underlying the generation of expressive behaviours, we propose a novel RPR approach that efficiently simulates personalised internal cognition from easy-accessible external short audio-visual behaviours expressed by the target individual. The simulated personalised cognition, represented as a set of network weights that enforce the personalised network to reproduce the individual-specific facial reactions, is further encoded as a novel graph containing two-dimensional node and edge feature matrices, with a novel 2D Graph Neural Network (2D-GNN) proposed for inferring real personality traits from it. To simulate real personality-related cognition, an end-to-end strategy is designed to jointly train our cognition simulation, 2D graph construction, and personality recognition modules.
RA-CLAP: Relation-Augmented Emotional Speaking Style Contrastive Language-Audio Pretraining For Speech Retrieval
May 26, 2025The Contrastive Language-Audio Pretraining (CLAP) model has demonstrated excellent performance in general audio description-related tasks, such as audio retrieval. However, in the emerging field of emotional speaking style description (ESSD), cross-modal contrastive pretraining remains largely unexplored. In this paper, we propose a novel speech retrieval task called emotional speaking style retrieval (ESSR), and ESS-CLAP, an emotional speaking style CLAP model tailored for learning relationship between speech and natural language descriptions. In addition, we further propose relation-augmented CLAP (RA-CLAP) to address the limitation of traditional methods that assume a strict binary relationship between caption and audio. The model leverages self-distillation to learn the potential local matching relationships between speech and descriptions, thereby enhancing generalization ability. The experimental results validate the effectiveness of RA-CLAP, providing valuable reference in ESSD.
REACT 2025: the Third Multiple Appropriate Facial Reaction Generation Challenge
May 22, 2025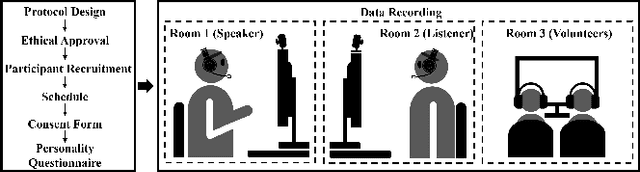

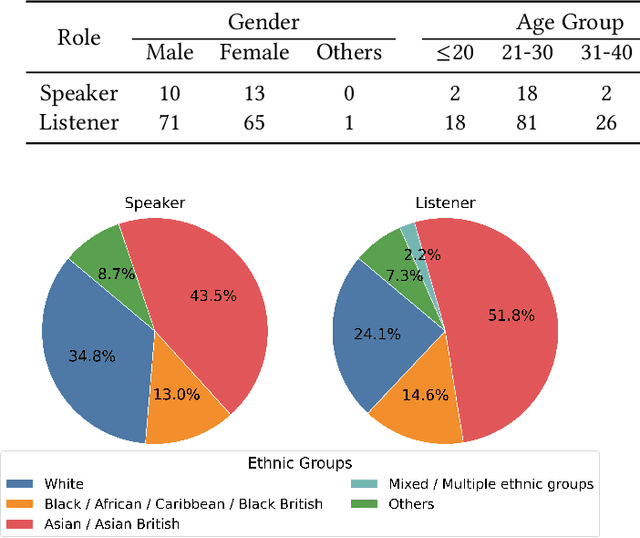
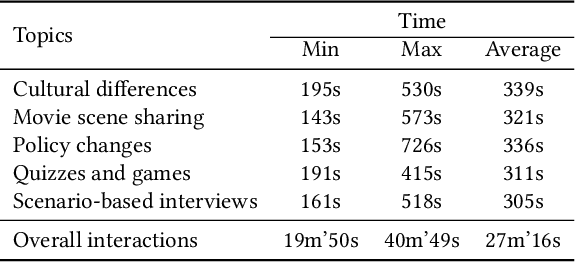
In dyadic interactions, a broad spectrum of human facial reactions might be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023 and REACT 2024 challenges, we are proposing the REACT 2025 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can be used to generate multiple appropriate, diverse, realistic and synchronised human-style facial reactions expressed by human listeners in response to an input stimulus (i.e., audio-visual behaviours expressed by their corresponding speakers). As a key of the challenge, we provide challenge participants with the first natural and large-scale multi-modal MAFRG dataset (called MARS) recording 137 human-human dyadic interactions containing a total of 2856 interaction sessions covering five different topics. In addition, this paper also presents the challenge guidelines and the performance of our baselines on the two proposed sub-challenges: Offline MAFRG and Online MAFRG, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2025
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
Iterative Prototype Refinement for Ambiguous Speech Emotion Recognition
Aug 01, 2024



Recognizing emotions from speech is a daunting task due to the subtlety and ambiguity of expressions. Traditional speech emotion recognition (SER) systems, which typically rely on a singular, precise emotion label, struggle with this complexity. Therefore, modeling the inherent ambiguity of emotions is an urgent problem. In this paper, we propose an iterative prototype refinement framework (IPR) for ambiguous SER. IPR comprises two interlinked components: contrastive learning and class prototypes. The former provides an efficient way to obtain high-quality representations of ambiguous samples. The latter are dynamically updated based on ambiguous labels -- the similarity of the ambiguous data to all prototypes. These refined embeddings yield precise pseudo labels, thus reinforcing representation quality. Experimental evaluations conducted on the IEMOCAP dataset validate the superior performance of IPR over state-of-the-art methods, thus proving the effectiveness of our proposed method.