 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeakerRPL v2: Robust Open-set Speaker Identification through Enhanced Few-shot Foundation Tuning and Model Fusion
Apr 15, 2026This paper proposes an improved approach for open-set speaker identification based on pretrained speaker foundation models. Building upon the previous Speaker Reciprocal Points Learning framework (V1), we first introduce an enhanced open-set learning objective by integrating reciprocal points learning with logit normalization (LogitNorm) and incorporating adaptive anchor learning to better constrain target speaker representations and improve robustness. Second, we propose a model fusion strategy to stabilize and enhance the few-shot tuning process, effectively reducing result randomness and improving generalization. Furthermore, we introduce a model selection method to ensure optimal performance in model fusion. Experimental evaluations on the VoxCeleb, ESD and 3D-Speaker datasets demonstrate the effectiveness and robustness of the proposed method under diverse conditions. On a newly proposed Vox1-O-like test set, our method reduces the EER from 1.28% to 0.09%, achieving a relative reduction of approximately 93%.
RA-CLAP: Relation-Augmented Emotional Speaking Style Contrastive Language-Audio Pretraining For Speech Retrieval
May 26, 2025The Contrastive Language-Audio Pretraining (CLAP) model has demonstrated excellent performance in general audio description-related tasks, such as audio retrieval. However, in the emerging field of emotional speaking style description (ESSD), cross-modal contrastive pretraining remains largely unexplored. In this paper, we propose a novel speech retrieval task called emotional speaking style retrieval (ESSR), and ESS-CLAP, an emotional speaking style CLAP model tailored for learning relationship between speech and natural language descriptions. In addition, we further propose relation-augmented CLAP (RA-CLAP) to address the limitation of traditional methods that assume a strict binary relationship between caption and audio. The model leverages self-distillation to learn the potential local matching relationships between speech and descriptions, thereby enhancing generalization ability. The experimental results validate the effectiveness of RA-CLAP, providing valuable reference in ESSD.
Learning Emotion-Invariant Speaker Representations for Speaker Verification
May 24, 2025In recent years, the rapid progress in speaker verification (SV) technology has been driven by the extraction of speaker representations based on deep learning. However, such representations are still vulnerable to emotion variability. To address this issue, we propose multiple improvements to train speaker encoders to increase emotion robustness. Firstly, we utilize CopyPaste-based data augmentation to gather additional parallel data, which includes different emotional expressions from the same speaker. Secondly, we apply cosine similarity loss to restrict parallel sample pairs and minimize intra-class variation of speaker representations to reduce their correlation with emotional information. Finally, we use emotion-aware masking (EM) based on the speech signal energy on the input parallel samples to further strengthen the speaker representation and make it emotion-invariant. We conduct a comprehensive ablation study to demonstrate the effectiveness of these various components. Experimental results show that our proposed method achieves a relative 19.29\% drop in EER compared to the baseline system.
Discrete Audio Representations for Automated Audio Captioning
May 21, 2025


Discrete audio representations, termed audio tokens, are broadly categorized into semantic and acoustic tokens, typically generated through unsupervised tokenization of continuous audio representations. However, their applicability to automated audio captioning (AAC) remains underexplored. This paper systematically investigates the viability of audio token-driven models for AAC through comparative analyses of various tokenization methods. Our findings reveal that audio tokenization leads to performance degradation in AAC models compared to those that directly utilize continuous audio representations. To address this issue, we introduce a supervised audio tokenizer trained with an audio tagging objective. Unlike unsupervised tokenizers, which lack explicit semantic understanding, the proposed tokenizer effectively captures audio event information. Experiments conducted on the Clotho dataset demonstrate that the proposed audio tokens outperform conventional audio tokens in the AAC task.
SC-MoE: Switch Conformer Mixture of Experts for Unified Streaming and Non-streaming Code-Switching ASR
Jun 26, 2024In this work, we propose a Switch-Conformer-based MoE system named SC-MoE for unified streaming and non-streaming code-switching (CS) automatic speech recognition (ASR), where we design a streaming MoE layer consisting of three language experts, which correspond to Mandarin, English, and blank, respectively, and equipped with a language identification (LID) network with a Connectionist Temporal Classification (CTC) loss as a router in the encoder of SC-MoE to achieve a real-time streaming CS ASR system. To further utilize the language information embedded in text, we also incorporate MoE layers into the decoder of SC-MoE. In addition, we introduce routers into every MoE layer of the encoder and the decoder and achieve better recognition performance. Experimental results show that the SC-MoE significantly improves CS ASR performances over baseline with comparable computational efficiency.
The RoyalFlush Automatic Speech Diarization and Recognition System for In-Car Multi-Channel Automatic Speech Recognition Challenge
May 09, 2024

This paper presents our system submission for the In-Car Multi-Channel Automatic Speech Recognition (ICMC-ASR) Challenge, which focuses on speaker diarization and speech recognition in complex multi-speaker scenarios. To address these challenges, we develop end-to-end speaker diarization models that notably decrease the diarization error rate (DER) by 49.58\% compared to the official baseline on the development set. For speech recognition, we utilize self-supervised learning representations to train end-to-end ASR models. By integrating these models, we achieve a character error rate (CER) of 16.93\% on the track 1 evaluation set, and a concatenated minimum permutation character error rate (cpCER) of 25.88\% on the track 2 evaluation set.
A Deep Representation Learning-based Speech Enhancement Method Using Complex Convolution Recurrent Variational Autoencoder
Dec 15, 2023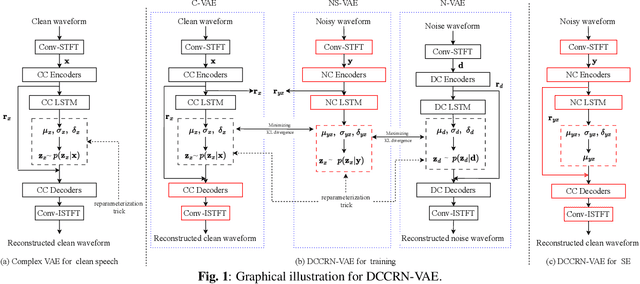
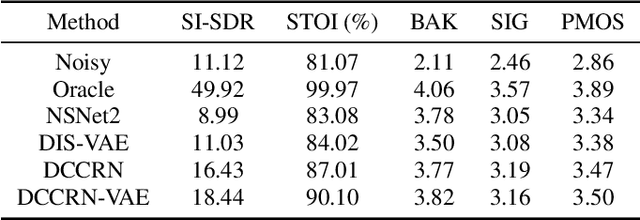
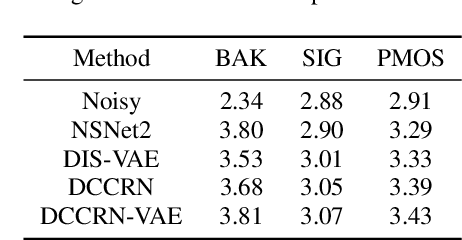
Generally, the performance of deep neural networks (DNNs) heavily depends on the quality of data representation learning. Our preliminary work has emphasized the significance of deep representation learning (DRL) in the context of speech enhancement (SE) applications. Specifically, our initial SE algorithm employed a gated recurrent unit variational autoencoder (VAE) with a Gaussian distribution to enhance the performance of certain existing SE systems. Building upon our preliminary framework, this paper introduces a novel approach for SE using deep complex convolutional recurrent networks with a VAE (DCCRN-VAE). DCCRN-VAE assumes that the latent variables of signals follow complex Gaussian distributions that are modeled by DCCRN, as these distributions can better capture the behaviors of complex signals. Additionally, we propose the application of a residual loss in DCCRN-VAE to further improve the quality of the enhanced speech. {Compared to our preliminary work, DCCRN-VAE introduces a more sophisticated DCCRN structure and probability distribution for DRL. Furthermore, in comparison to DCCRN, DCCRN-VAE employs a more advanced DRL strategy. The experimental results demonstrate that the proposed SE algorithm outperforms both our preliminary SE framework and the state-of-the-art DCCRN SE method in terms of scale-invariant signal-to-distortion ratio, speech quality, and speech intelligibility.
LE-SSL-MOS: Self-Supervised Learning MOS Prediction with Listener Enhancement
Nov 17, 2023



Recently, researchers have shown an increasing interest in automatically predicting the subjective evaluation for speech synthesis systems. This prediction is a challenging task, especially on the out-of-domain test set. In this paper, we proposed a novel fusion model for MOS prediction that combines supervised and unsupervised approaches. In the supervised aspect, we developed an SSL-based predictor called LE-SSL-MOS. The LE-SSL-MOS utilizes pre-trained self-supervised learning models and further improves prediction accuracy by utilizing the opinion scores of each utterance in the listener enhancement branch. In the unsupervised aspect, two steps are contained: we fine-tuned the unit language model (ULM) using highly intelligible domain data to improve the correlation of an unsupervised metric - SpeechLMScore. Another is that we utilized ASR confidence as a new metric with the help of ensemble learning. To our knowledge, this is the first architecture that fuses supervised and unsupervised methods for MOS prediction. With these approaches, our experimental results on the VoiceMOS Challenge 2023 show that LE-SSL-MOS performs better than the baseline. Our fusion system achieved an absolute improvement of 13% over LE-SSL-MOS on the noisy and enhanced speech track. Our system ranked 1st and 2nd, respectively, in the French speech synthesis track and the challenge's noisy and enhanced speech track.
Advancing the study of Large-Scale Learning in Overlapped Speech Detection
Aug 28, 2023Overlapped Speech Detection (OSD) is an important part of speech applications involving analysis of multi-party conversations. However, most of the existing OSD systems are trained and evaluated on specific dataset, which limits the application scenarios of these systems. To solve this problem, we conduct a study of large-scale learning (LSL) in OSD tasks and propose a general 16K single-channel OSD system. In our study, 522 hours of labeled audio in different languages and styles are collected and used as the large-scale dataset. Rigorous comparative experiments are designed and used to evaluate the effectiveness of LSL in OSD tasks and select the appropriate model of general OSD system. The results show that LSL can significantly improve the performance and robustness of OSD models, and the OSD model based on Conformer (CF-OSD) with LSL is currently the best 16K single-channel OSD system. Moreover, the CF-OSD with LSL establishes a state-of-the-art performance with an F1-score of 81.6% and 53.8% on Alimeeting test set and DIHARD II evaluation set, respectively.
The Royalflush System for VoxCeleb Speaker Recognition Challenge 2022
Sep 20, 2022
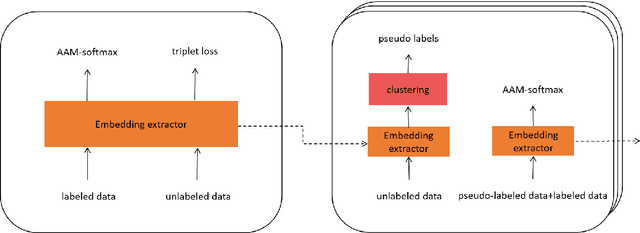
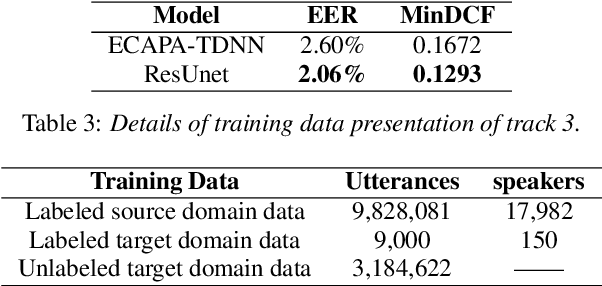

In this technical report, we describe the Royalflush submissions for the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22). Our submissions contain track 1, which is for supervised speaker verification and track 3, which is for semi-supervised speaker verification. For track 1, we develop a powerful U-Net-based speaker embedding extractor with a symmetric architecture. The proposed system achieves 2.06% in EER and 0.1293 in MinDCF on the validation set. Compared with the state-of-the-art ECAPA-TDNN, it obtains a relative improvement of 20.7% in EER and 22.70% in MinDCF. For track 3, we employ the joint training of source domain supervision and target domain self-supervision to get a speaker embedding extractor. The subsequent clustering process can obtain target domain pseudo-speaker labels. We adapt the speaker embedding extractor using all source and target domain data in a supervised manner, where it can fully leverage both domain information. Moreover, clustering and supervised domain adaptation can be repeated until the performance converges on the validation set. Our final submission is a fusion of 10 models and achieves 7.75% EER and 0.3517 MinDCF on the validation set.