 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Representation Learning-based Speech Enhancement Method Using Complex Convolution Recurrent Variational Autoencoder
Paper and Code
Dec 15, 2023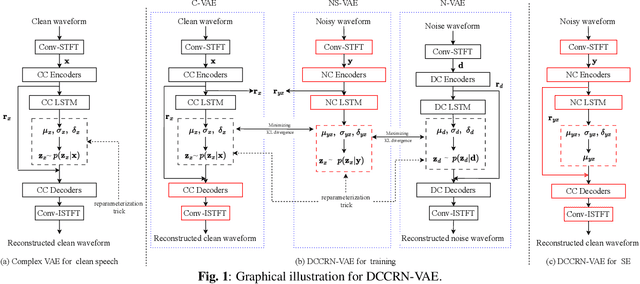
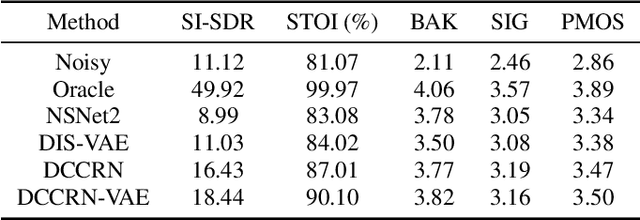
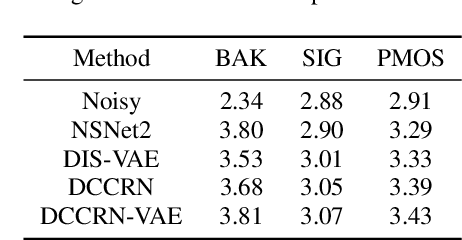
Generally, the performance of deep neural networks (DNNs) heavily depends on the quality of data representation learning. Our preliminary work has emphasized the significance of deep representation learning (DRL) in the context of speech enhancement (SE) applications. Specifically, our initial SE algorithm employed a gated recurrent unit variational autoencoder (VAE) with a Gaussian distribution to enhance the performance of certain existing SE systems. Building upon our preliminary framework, this paper introduces a novel approach for SE using deep complex convolutional recurrent networks with a VAE (DCCRN-VAE). DCCRN-VAE assumes that the latent variables of signals follow complex Gaussian distributions that are modeled by DCCRN, as these distributions can better capture the behaviors of complex signals. Additionally, we propose the application of a residual loss in DCCRN-VAE to further improve the quality of the enhanced speech. {Compared to our preliminary work, DCCRN-VAE introduces a more sophisticated DCCRN structure and probability distribution for DRL. Furthermore, in comparison to DCCRN, DCCRN-VAE employs a more advanced DRL strategy. The experimental results demonstrate that the proposed SE algorithm outperforms both our preliminary SE framework and the state-of-the-art DCCRN SE method in terms of scale-invariant signal-to-distortion ratio, speech quality, and speech intelligibility.