 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Royalflush System for VoxCeleb Speaker Recognition Challenge 2022
Paper and Code
Sep 20, 2022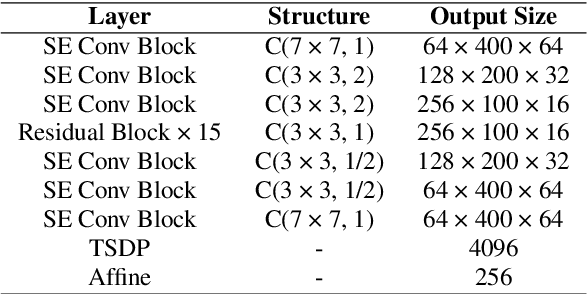
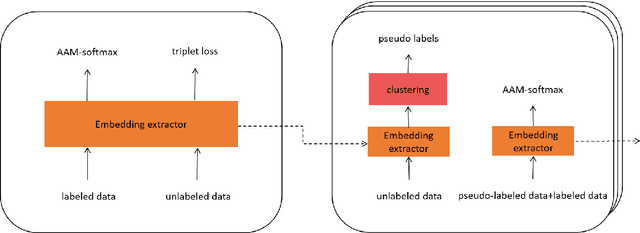
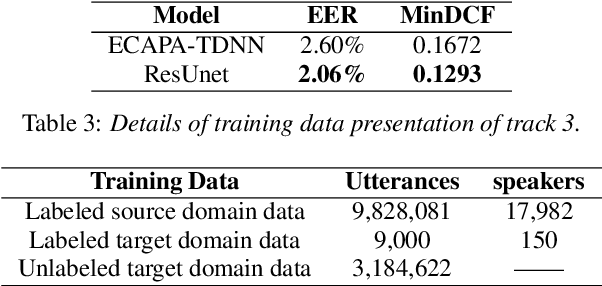

In this technical report, we describe the Royalflush submissions for the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22). Our submissions contain track 1, which is for supervised speaker verification and track 3, which is for semi-supervised speaker verification. For track 1, we develop a powerful U-Net-based speaker embedding extractor with a symmetric architecture. The proposed system achieves 2.06% in EER and 0.1293 in MinDCF on the validation set. Compared with the state-of-the-art ECAPA-TDNN, it obtains a relative improvement of 20.7% in EER and 22.70% in MinDCF. For track 3, we employ the joint training of source domain supervision and target domain self-supervision to get a speaker embedding extractor. The subsequent clustering process can obtain target domain pseudo-speaker labels. We adapt the speaker embedding extractor using all source and target domain data in a supervised manner, where it can fully leverage both domain information. Moreover, clustering and supervised domain adaptation can be repeated until the performance converges on the validation set. Our final submission is a fusion of 10 models and achieves 7.75% EER and 0.3517 MinDCF on the validation set.