 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoyalflush Speaker Diarization System for ICASSP 2022 Multi-channel Multi-party Meeting Transcription Challenge
Paper and Code
Feb 18, 2022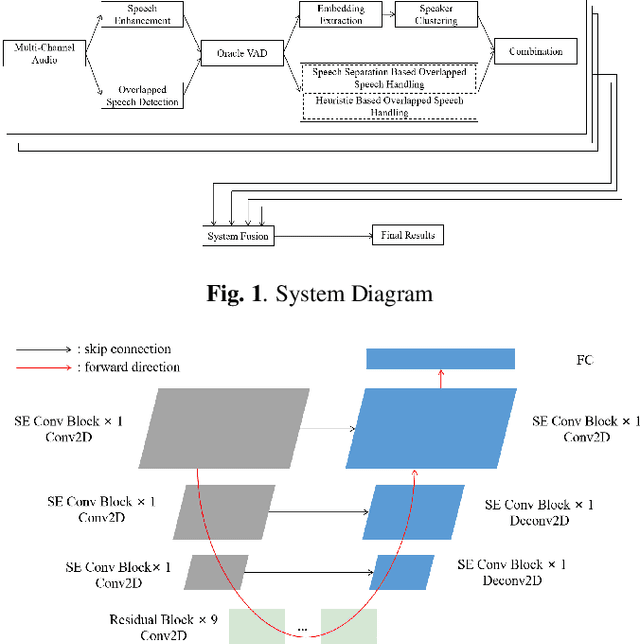
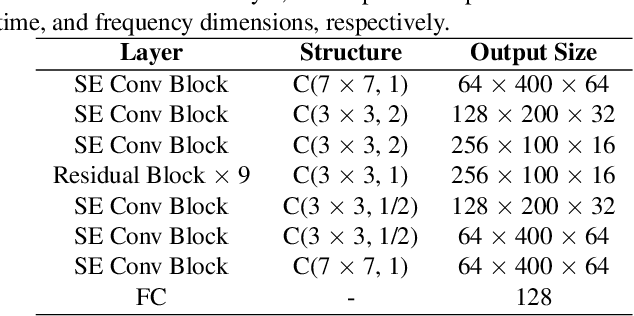
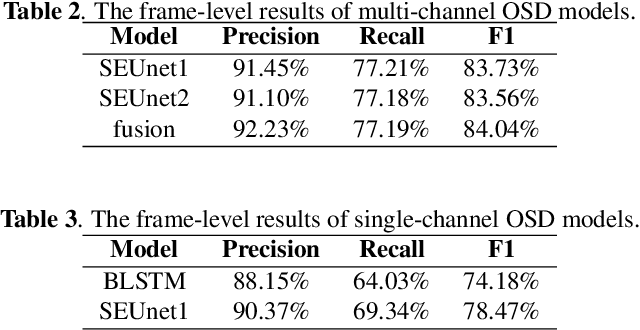

This paper describes the Royalflush speaker diarization system submitted to the Multi-channel Multi-party Meeting Transcription Challenge(M2MeT). Our system comprises speech enhancement, overlapped speech detection, speaker embedding extraction, speaker clustering, speech separation and system fusion. In this system, we made three contributions. First, we propose an architecture of combining the multi-channel and U-Net-based models, aiming at utilizing the benefits of these two individual architectures, for far-field overlapped speech detection. Second, in order to use overlapped speech detection model to help speaker diarization, a speech separation based overlapped speech handling approach, in which the speaker verification technique is further applied, is proposed. Third, we explore three speaker embedding methods, and obtained the state-of-the-art performance on the CNCeleb-E test set. With these proposals, our best individual system significantly reduces DER from 15.25% to 6.40%, and the fusion of four systems finally achieves a DER of 6.30% on the far-field Alimeeting evaluation set.