 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCC-DSA: A Novel Vascular Consistency Constrained DSA Imaging Model for Motion Artifact Suppression
Apr 12, 2026Digital Subtraction Angiography (DSA) is a clinically significant imaging technique for diagnosing cerebrovascular disease, as gold-standard. However, the artifacts caused by motion of high-attenuation tissues such as bones, teeth, and catheters, seriously reduce the visibility of blood vessels. This paper presents a novel Vascular Consistency Constrained DSA Imaging Model (VCC-DSA) for robust motion suppression and precise vascular imaging with the following designs: 1) We specially design a Learning-based Subtraction Mapping Paradigm, so that the ill-posed problem of existing learning-based methods can be solved to enhance the stability of the algorithm. 2) Our model effectively develops Residual Dense Blocks and details-shortcut to improve the performance under complex structures, such as moving bones overlapping with blood vessels, and small features, like peripheral vessels. 3) An innovative Vascular Consistency Strategy is proposed to extract intrinsically consistency from the various relative motions in mask-live images, so that spontaneously distils the vascular structure with contrast-agent development and robustly suppress motion artifacts, and also naturally alleviates the high matching requirements of data. 4) We creatively design a Mixup-based Data Self-evolution Strategy for data-intra self-enhancement in training loop, so that the training data gains dynamically optimized to promote model better learning the vascular features, and excluding the irrelevant structures in live/mask image and even the inevitable-artifacts/fake-structure in label. Prospectively, to further evaluate practical value, an actual general anesthesia animal experiment is specially conducted, besides the assessment on human clinical data. Compared with other method, our model improves the PSNR and SSIM by 73.4% and 8.56%, respectively.
Hierarchical Testing of a Hybrid Machine Learning-Physics Global Atmosphere Model
Feb 11, 2026Machine learning (ML)-based models have demonstrated high skill and computational efficiency, often outperforming conventional physics-based models in weather and subseasonal predictions. While prior studies have assessed their fidelity in capturing synoptic-scale atmospheric dynamics, their performance across timescales and under out-of-distribution forcing, such as +3K or +4K uniform-warming forcings, and the sources of biases remain elusive, to establish the model reliability for Earth science. Here, we design three sets of experiments targeting synoptic-scale phenomena, interannual variability, and out-of-distribution uniform-warming forcings. We evaluate the Neural General Circulation Model (NeuralGCM), a hybrid model integrating a dynamical core with ML-based component, against observations and physics-based Earth system models (ESMs). At the synoptic scale, NeuralGCM captures the evolution and propagation of extratropical cyclones with performance comparable to ESMs. At the interannual scale, when forced by El Niño-Southern Oscillation sea surface temperature (SST) anomalies, NeuralGCM successfully reproduces associated teleconnection patterns but exhibits deficiencies in capturing nonlinear response. Under out-of-distribution uniform-warming forcings, NeuralGCM simulates similar responses in global-average temperature and precipitation and reproduces large-scale tropospheric circulation features similar to those in ESMs. Notable weaknesses include overestimating the tracks and spatial extent of extratropical cyclones, biases in the teleconnected wave train triggered by tropical SST anomalies, and differences in upper-level warming and stratospheric circulation responses to SST warming compared to physics-based ESMs. The causes of these weaknesses were explored.
Point-SRA: Self-Representation Alignment for 3D Representation Learning
Jan 05, 2026Masked autoencoders (MAE) have become a dominant paradigm in 3D representation learning, setting new performance benchmarks across various downstream tasks. Existing methods with fixed mask ratio neglect multi-level representational correlations and intrinsic geometric structures, while relying on point-wise reconstruction assumptions that conflict with the diversity of point cloud. To address these issues, we propose a 3D representation learning method, termed Point-SRA, which aligns representations through self-distillation and probabilistic modeling. Specifically, we assign different masking ratios to the MAE to capture complementary geometric and semantic information, while the MeanFlow Transformer (MFT) leverages cross-modal conditional embeddings to enable diverse probabilistic reconstruction. Our analysis further reveals that representations at different time steps in MFT also exhibit complementarity. Therefore, a Dual Self-Representation Alignment mechanism is proposed at both the MAE and MFT levels. Finally, we design a Flow-Conditioned Fine-Tuning Architecture to fully exploit the point cloud distribution learned via MeanFlow. Point-SRA outperforms Point-MAE by 5.37% on ScanObjectNN. On intracranial aneurysm segmentation, it reaches 96.07% mean IoU for arteries and 86.87% for aneurysms. For 3D object detection, Point-SRA achieves 47.3% AP@50, surpassing MaskPoint by 5.12%.
MoFu: Scale-Aware Modulation and Fourier Fusion for Multi-Subject Video Generation
Dec 26, 2025Multi-subject video generation aims to synthesize videos from textual prompts and multiple reference images, ensuring that each subject preserves natural scale and visual fidelity. However, current methods face two challenges: scale inconsistency, where variations in subject size lead to unnatural generation, and permutation sensitivity, where the order of reference inputs causes subject distortion. In this paper, we propose MoFu, a unified framework that tackles both challenges. For scale inconsistency, we introduce Scale-Aware Modulation (SMO), an LLM-guided module that extracts implicit scale cues from the prompt and modulates features to ensure consistent subject sizes. To address permutation sensitivity, we present a simple yet effective Fourier Fusion strategy that processes the frequency information of reference features via the Fast Fourier Transform to produce a unified representation. Besides, we design a Scale-Permutation Stability Loss to jointly encourage scale-consistent and permutation-invariant generation. To further evaluate these challenges, we establish a dedicated benchmark with controlled variations in subject scale and reference permutation. Extensive experiments demonstrate that MoFu significantly outperforms existing methods in preserving natural scale, subject fidelity, and overall visual quality.
MyGO: Make your Goals Obvious, Avoiding Semantic Confusion in Prostate Cancer Lesion Region Segmentation
Jul 23, 2025Early diagnosis and accurate identification of lesion location and progression in prostate cancer (PCa) are critical for assisting clinicians in formulating effective treatment strategies. However, due to the high semantic homogeneity between lesion and non-lesion areas, existing medical image segmentation methods often struggle to accurately comprehend lesion semantics, resulting in the problem of semantic confusion. To address this challenge, we propose a novel Pixel Anchor Module, which guides the model to discover a sparse set of feature anchors that serve to capture and interpret global contextual information. This mechanism enhances the model's nonlinear representation capacity and improves segmentation accuracy within lesion regions. Moreover, we design a self-attention-based Top_k selection strategy to further refine the identification of these feature anchors, and incorporate a focal loss function to mitigate class imbalance, thereby facilitating more precise semantic interpretation across diverse regions. Our method achieves state-of-the-art performance on the PI-CAI dataset, demonstrating 69.73% IoU and 74.32% Dice scores, and significantly improving prostate cancer lesion detection.
Dyna3DGR: 4D Cardiac Motion Tracking with Dynamic 3D Gaussian Representation
Jul 22, 2025Accurate analysis of cardiac motion is crucial for evaluating cardiac function. While dynamic cardiac magnetic resonance imaging (CMR) can capture detailed tissue motion throughout the cardiac cycle, the fine-grained 4D cardiac motion tracking remains challenging due to the homogeneous nature of myocardial tissue and the lack of distinctive features. Existing approaches can be broadly categorized into image based and representation-based, each with its limitations. Image-based methods, including both raditional and deep learning-based registration approaches, either struggle with topological consistency or rely heavily on extensive training data. Representation-based methods, while promising, often suffer from loss of image-level details. To address these limitations, we propose Dynamic 3D Gaussian Representation (Dyna3DGR), a novel framework that combines explicit 3D Gaussian representation with implicit neural motion field modeling. Our method simultaneously optimizes cardiac structure and motion in a self-supervised manner, eliminating the need for extensive training data or point-to-point correspondences. Through differentiable volumetric rendering, Dyna3DGR efficiently bridges continuous motion representation with image-space alignment while preserving both topological and temporal consistency. Comprehensive evaluations on the ACDC dataset demonstrate that our approach surpasses state-of-the-art deep learning-based diffeomorphic registration methods in tracking accuracy. The code will be available in https://github.com/windrise/Dyna3DGR.
CustomTTT: Motion and Appearance Customized Video Generation via Test-Time Training
Dec 23, 2024Benefiting from large-scale pre-training of text-video pairs, current text-to-video (T2V) diffusion models can generate high-quality videos from the text description. Besides, given some reference images or videos, the parameter-efficient fine-tuning method, i.e. LoRA, can generate high-quality customized concepts, e.g., the specific subject or the motions from a reference video. However, combining the trained multiple concepts from different references into a single network shows obvious artifacts. To this end, we propose CustomTTT, where we can joint custom the appearance and the motion of the given video easily. In detail, we first analyze the prompt influence in the current video diffusion model and find the LoRAs are only needed for the specific layers for appearance and motion customization. Besides, since each LoRA is trained individually, we propose a novel test-time training technique to update parameters after combination utilizing the trained customized models. We conduct detailed experiments to verify the effectiveness of the proposed methods. Our method outperforms several state-of-the-art works in both qualitative and quantitative evaluations.
Neuro-symbolic Learning Yielding Logical Constraints
Oct 28, 2024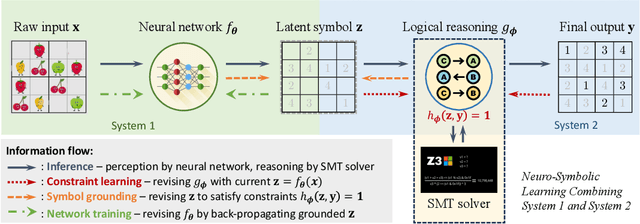
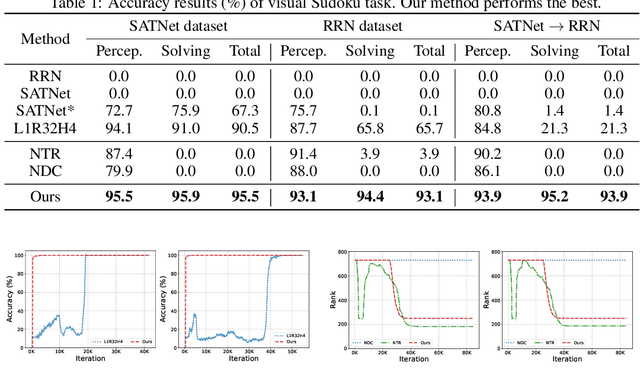
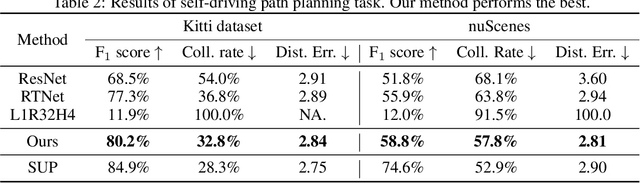
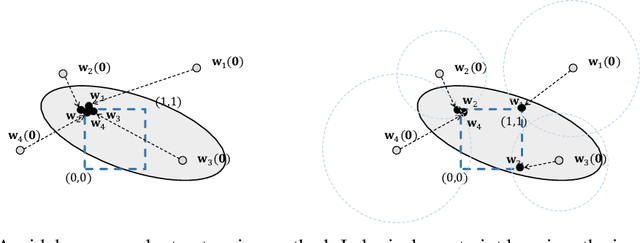
Neuro-symbolic systems combine the abilities of neural perception and logical reasoning. However, end-to-end learning of neuro-symbolic systems is still an unsolved challenge. This paper proposes a natural framework that fuses neural network training, symbol grounding, and logical constraint synthesis into a coherent and efficient end-to-end learning process. The capability of this framework comes from the improved interactions between the neural and the symbolic parts of the system in both the training and inference stages. Technically, to bridge the gap between the continuous neural network and the discrete logical constraint, we introduce a difference-of-convex programming technique to relax the logical constraints while maintaining their precision. We also employ cardinality constraints as the language for logical constraint learning and incorporate a trust region method to avoid the degeneracy of logical constraint in learning. Both theoretical analyses and empirical evaluations substantiate the effectiveness of the proposed framework.
Revisiting Multi-Modal LLM Evaluation
Aug 09, 2024
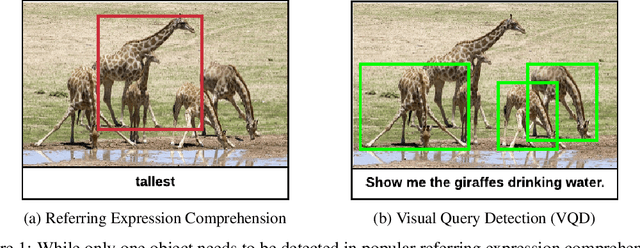

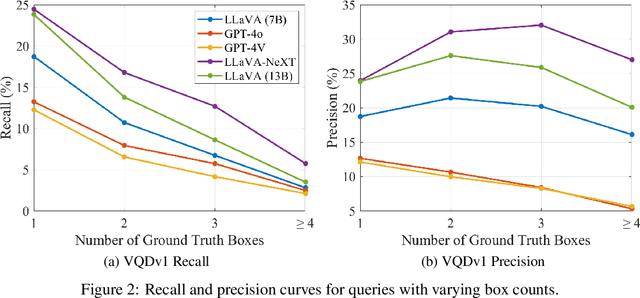
With the advent of multi-modal large language models (MLLMs), datasets used for visual question answering (VQA) and referring expression comprehension have seen a resurgence. However, the most popular datasets used to evaluate MLLMs are some of the earliest ones created, and they have many known problems, including extreme bias, spurious correlations, and an inability to permit fine-grained analysis. In this paper, we pioneer evaluating recent MLLMs (LLaVA 1.5, LLaVA-NeXT, BLIP2, InstructBLIP, GPT-4V, and GPT-4o) on datasets designed to address weaknesses in earlier ones. We assess three VQA datasets: 1) TDIUC, which permits fine-grained analysis on 12 question types; 2) TallyQA, which has simple and complex counting questions; and 3) DVQA, which requires optical character recognition for chart understanding. We also study VQDv1, a dataset that requires identifying all image regions that satisfy a given query. Our experiments reveal the weaknesses of many MLLMs that have not previously been reported. Our code is integrated into the widely used LAVIS framework for MLLM evaluation, enabling the rapid assessment of future MLLMs. Project webpage: https://kevinlujian.github.io/MLLM_Evaluations/
EMBANet: A Flexible Efffcient Multi-branch Attention Network
Jul 07, 2024This work presents a novel module, namely multi-branch concat (MBC), to process the input tensor and obtain the multi-scale feature map. The proposed MBC module brings new degrees of freedom (DoF) for the design of attention networks by allowing the type of transformation operators and the number of branches to be flexibly adjusted. Two important transformation operators, multiplex and split, are considered in this work, both of which can represent multi-scale features at a more granular level and increase the range of receptive fields. By integrating the MBC and attention module, a multi-branch attention (MBA) module is consequently developed to capture the channel-wise interaction of feature maps for establishing the long-range channel dependency. By substituting the 3x3 convolutions in the bottleneck blocks of the ResNet with the proposed MBA, a novel block namely efficient multi-branch attention (EMBA) is obtained, which can be easily plugged into the state-of-the-art backbone CNN models. Furthermore, a new backbone network called EMBANet is established by stacking the EMBA blocks. The proposed EMBANet is extensively evaluated on representative computer vision tasks including: classification, detection, and segmentation. And it demonstrates consistently superior performance over the popular backbones.