 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiNeXt: Revisiting LiDAR Completion with Efficient Non-Diffusion Architectures
Nov 13, 20253D LiDAR scene completion from point clouds is a fundamental component of perception systems in autonomous vehicles. Previous methods have predominantly employed diffusion models for high-fidelity reconstruction. However, their multi-step iterative sampling incurs significant computational overhead, limiting its real-time applicability. To address this, we propose LiNeXt-a lightweight, non-diffusion network optimized for rapid and accurate point cloud completion. Specifically, LiNeXt first applies the Noise-to-Coarse (N2C) Module to denoise the input noisy point cloud in a single pass, thereby obviating the multi-step iterative sampling of diffusion-based methods. The Refine Module then takes the coarse point cloud and its intermediate features from the N2C Module to perform more precise refinement, further enhancing structural completeness. Furthermore, we observe that LiDAR point clouds exhibit a distance-dependent spatial distribution, being densely sampled at proximal ranges and sparsely sampled at distal ranges. Accordingly, we propose the Distance-aware Selected Repeat strategy to generate a more uniformly distributed noisy point cloud. On the SemanticKITTI dataset, LiNeXt achieves a 199.8x speedup in inference, reduces Chamfer Distance by 50.7%, and uses only 6.1% of the parameters compared with LiDiff. These results demonstrate the superior efficiency and effectiveness of LiNeXt for real-time scene completion.
RWKV-PCSSC: Exploring RWKV Model for Point Cloud Semantic Scene Completion
Nov 13, 2025



Semantic Scene Completion (SSC) aims to generate a complete semantic scene from an incomplete input. Existing approaches often employ dense network architectures with a high parameter count, leading to increased model complexity and resource demands. To address these limitations, we propose RWKV-PCSSC, a lightweight point cloud semantic scene completion network inspired by the Receptance Weighted Key Value (RWKV) mechanism. Specifically, we introduce a RWKV Seed Generator (RWKV-SG) module that can aggregate features from a partial point cloud to produce a coarse point cloud with coarse features. Subsequently, the point-wise feature of the point cloud is progressively restored through multiple stages of the RWKV Point Deconvolution (RWKV-PD) modules. By leveraging a compact and efficient design, our method achieves a lightweight model representation. Experimental results demonstrate that RWKV-PCSSC reduces the parameter count by 4.18$\times$ and improves memory efficiency by 1.37$\times$ compared to state-of-the-art methods PointSSC. Furthermore, our network achieves state-of-the-art performance on established indoor (SSC-PC, NYUCAD-PC) and outdoor (PointSSC) scene dataset, as well as on our proposed datasets (NYUCAD-PC-V2, 3D-FRONT-PC).
* 13 pages, 8 figures, published to ACM MM
Value-Aligned Prompt Moderation via Zero-Shot Agentic Rewriting for Safe Image Generation
Nov 12, 2025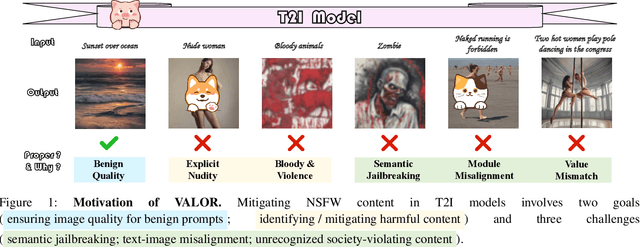
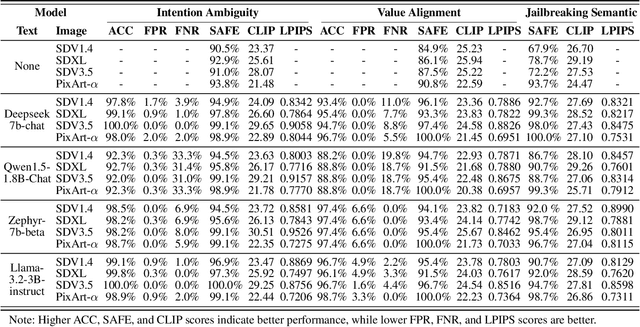


Generative vision-language models like Stable Diffusion demonstrate remarkable capabilities in creative media synthesis, but they also pose substantial risks of producing unsafe, offensive, or culturally inappropriate content when prompted adversarially. Current defenses struggle to align outputs with human values without sacrificing generation quality or incurring high costs. To address these challenges, we introduce VALOR (Value-Aligned LLM-Overseen Rewriter), a modular, zero-shot agentic framework for safer and more helpful text-to-image generation. VALOR integrates layered prompt analysis with human-aligned value reasoning: a multi-level NSFW detector filters lexical and semantic risks; a cultural value alignment module identifies violations of social norms, legality, and representational ethics; and an intention disambiguator detects subtle or indirect unsafe implications. When unsafe content is detected, prompts are selectively rewritten by a large language model under dynamic, role-specific instructions designed to preserve user intent while enforcing alignment. If the generated image still fails a safety check, VALOR optionally performs a stylistic regeneration to steer the output toward a safer visual domain without altering core semantics. Experiments across adversarial, ambiguous, and value-sensitive prompts show that VALOR significantly reduces unsafe outputs by up to 100.00% while preserving prompt usefulness and creativity. These results highlight VALOR as a scalable and effective approach for deploying safe, aligned, and helpful image generation systems in open-world settings.
DeepTracer: Tracing Stolen Model via Deep Coupled Watermarks
Nov 12, 2025Model watermarking techniques can embed watermark information into the protected model for ownership declaration by constructing specific input-output pairs. However, existing watermarks are easily removed when facing model stealing attacks, and make it difficult for model owners to effectively verify the copyright of stolen models. In this paper, we analyze the root cause of the failure of current watermarking methods under model stealing scenarios and then explore potential solutions. Specifically, we introduce a robust watermarking framework, DeepTracer, which leverages a novel watermark samples construction method and a same-class coupling loss constraint. DeepTracer can incur a high-coupling model between watermark task and primary task that makes adversaries inevitably learn the hidden watermark task when stealing the primary task functionality. Furthermore, we propose an effective watermark samples filtering mechanism that elaborately select watermark key samples used in model ownership verification to enhance the reliability of watermarks. Extensive experiments across multiple datasets and models demonstrate that our method surpasses existing approaches in defending against various model stealing attacks, as well as watermark attacks, and achieves new state-of-the-art effectiveness and robustness.
A Support-Set Algorithm for Optimization Problems with Nonnegative and Orthogonal Constraints
Nov 05, 2025In this paper, we investigate optimization problems with nonnegative and orthogonal constraints, where any feasible matrix of size $n \times p$ exhibits a sparsity pattern such that each row accommodates at most one nonzero entry. Our analysis demonstrates that, by fixing the support set, the global solution of the minimization subproblem for the proximal linearization of the objective function can be computed in closed form with at most $n$ nonzero entries. Exploiting this structural property offers a powerful avenue for dramatically enhancing computational efficiency. Guided by this insight, we propose a support-set algorithm preserving strictly the feasibility of iterates. A central ingredient is a strategically devised update scheme for support sets that adjusts the placement of nonzero entries. We establish the global convergence of the support-set algorithm to a first-order stationary point, and show that its iteration complexity required to reach an $\epsilon$-approximate first-order stationary point is $O (\epsilon^{-2})$. Numerical results are strongly in favor of our algorithm in real-world applications, including nonnegative PCA, clustering, and community detection.
AILoRA: Function-Aware Asymmetric Initialization for Low-Rank Adaptation of Large Language Models
Oct 09, 2025Parameter-efficient finetuning (PEFT) aims to mitigate the substantial computational and memory overhead involved in adapting large-scale pretrained models to diverse downstream tasks. Among numerous PEFT strategies, Low-Rank Adaptation (LoRA) has emerged as one of the most widely adopted approaches due to its robust empirical performance and low implementation complexity. In practical deployment, LoRA is typically applied to the $W^Q$ and $W^V$ projection matrices of self-attention modules, enabling an effective trade-off between model performance and parameter efficiency. While LoRA has achieved considerable empirical success, it still encounters challenges such as suboptimal performance and slow convergence. To address these limitations, we introduce \textbf{AILoRA}, a novel parameter-efficient method that incorporates function-aware asymmetric low-rank priors. Our empirical analysis reveals that the projection matrices $W^Q$ and $W^V$ in the self-attention mechanism exhibit distinct parameter characteristics, stemming from their functional differences. Specifically, $W^Q$ captures task-specific semantic space knowledge essential for attention distributions computation, making its parameters highly sensitive to downstream task variations. In contrast, $W^V$ encodes token-level feature representations that tend to remain stable across tasks and layers. Leveraging these insights, AILoRA performs a function-aware initialization by injecting the principal components of $W^Q$ to retain task-adaptive capacity, and the minor components of $W^V$ to preserve generalizable feature representations. This asymmetric initialization strategy enables LoRA modules to better capture the specialized roles of attention parameters, thereby enhancing both finetuning performance and convergence efficiency.
Comet: Accelerating Private Inference for Large Language Model by Predicting Activation Sparsity
May 12, 2025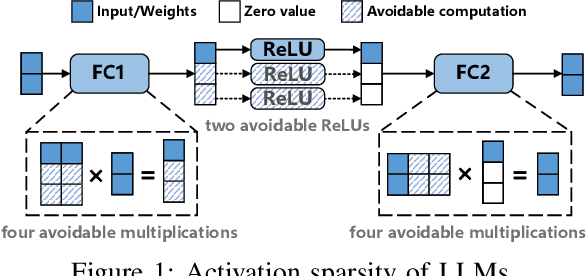
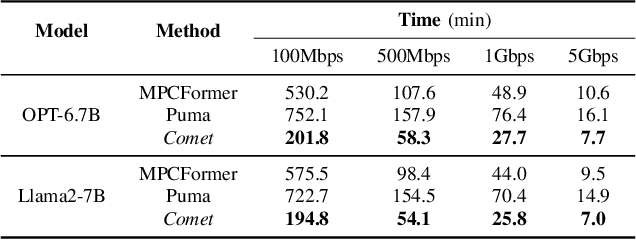
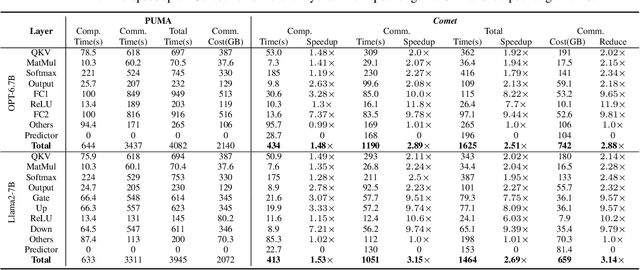
With the growing use of large language models (LLMs) hosted on cloud platforms to offer inference services, privacy concerns about the potential leakage of sensitive information are escalating. Secure multi-party computation (MPC) is a promising solution to protect the privacy in LLM inference. However, MPC requires frequent inter-server communication, causing high performance overhead. Inspired by the prevalent activation sparsity of LLMs, where most neuron are not activated after non-linear activation functions, we propose an efficient private inference system, Comet. This system employs an accurate and fast predictor to predict the sparsity distribution of activation function output. Additionally, we introduce a new private inference protocol. It efficiently and securely avoids computations involving zero values by exploiting the spatial locality of the predicted sparse distribution. While this computation-avoidance approach impacts the spatiotemporal continuity of KV cache entries, we address this challenge with a low-communication overhead cache refilling strategy that merges miss requests and incorporates a prefetching mechanism. Finally, we evaluate Comet on four common LLMs and compare it with six state-of-the-art private inference systems. Comet achieves a 1.87x-2.63x speedup and a 1.94x-2.64x communication reduction.
The Distributionally Robust Optimization Model of Sparse Principal Component Analysis
Mar 04, 2025We consider sparse principal component analysis (PCA) under a stochastic setting where the underlying probability distribution of the random parameter is uncertain. This problem is formulated as a distributionally robust optimization (DRO) model based on a constructive approach to capturing uncertainty in the covariance matrix, which constitutes a nonsmooth constrained min-max optimization problem. We further prove that the inner maximization problem admits a closed-form solution, reformulating the original DRO model into an equivalent minimization problem on the Stiefel manifold. This transformation leads to a Riemannian optimization problem with intricate nonsmooth terms, a challenging formulation beyond the reach of existing algorithms. To address this issue, we devise an efficient smoothing manifold proximal gradient algorithm. We prove the Riemannian gradient consistency and global convergence of our algorithm to a stationary point of the nonsmooth minimization problem. Moreover, we establish the iteration complexity of our algorithm. Finally, numerical experiments are conducted to validate the effectiveness and scalability of our algorithm, as well as to highlight the necessity and rationality of adopting the DRO model for sparse PCA.
Antelope: Potent and Concealed Jailbreak Attack Strategy
Dec 11, 2024Due to the remarkable generative potential of diffusion-based models, numerous researches have investigated jailbreak attacks targeting these frameworks. A particularly concerning threat within image models is the generation of Not-Safe-for-Work (NSFW) content. Despite the implementation of security filters, numerous efforts continue to explore ways to circumvent these safeguards. Current attack methodologies primarily encompass adversarial prompt engineering or concept obfuscation, yet they frequently suffer from slow search efficiency, conspicuous attack characteristics and poor alignment with targets. To overcome these challenges, we propose Antelope, a more robust and covert jailbreak attack strategy designed to expose security vulnerabilities inherent in generative models. Specifically, Antelope leverages the confusion of sensitive concepts with similar ones, facilitates searches in the semantically adjacent space of these related concepts and aligns them with the target imagery, thereby generating sensitive images that are consistent with the target and capable of evading detection. Besides, we successfully exploit the transferability of model-based attacks to penetrate online black-box services. Experimental evaluations demonstrate that Antelope outperforms existing baselines across multiple defensive mechanisms, underscoring its efficacy and versatility.
Buster: Incorporating Backdoor Attacks into Text Encoder to Mitigate NSFW Content Generation
Dec 10, 2024



In the digital age, the proliferation of deep learning models has led to significant concerns about the generation of Not Safe for Work (NSFW) content. Existing defense methods primarily involve model fine-tuning and post-hoc content moderation. However, these approaches often lack scalability in eliminating harmful content, degrade the quality of benign image generation, or incur high inference costs. To tackle these challenges, we propose an innovative framework called \textbf{Buster}, which injects backdoor attacks into the text encoder to prevent NSFW content generation. Specifically, Buster leverages deep semantic information rather than explicit prompts as triggers, redirecting NSFW prompts towards targeted benign prompts. This approach demonstrates exceptional resilience and scalability in mitigating NSFW content. Remarkably, Buster fine-tunes the text encoder of Text-to-Image models within just five minutes, showcasing high efficiency. Our extensive experiments reveal that Buster outperforms all other baselines, achieving superior NSFW content removal rate while preserving the quality of harmless images.