 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Limited Node Labels
Jun 18, 2024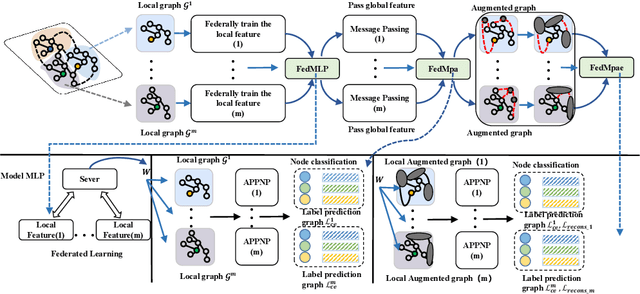
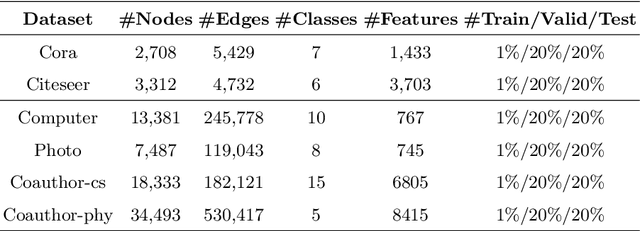
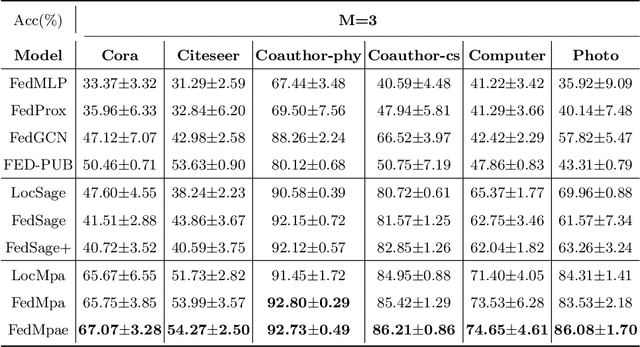
Subgraph federated learning (SFL) is a research methodology that has gained significant attention for its potential to handle distributed graph-structured data. In SFL, the local model comprises graph neural networks (GNNs) with a partial graph structure. However, some SFL models have overlooked the significance of missing cross-subgraph edges, which can lead to local GNNs being unable to message-pass global representations to other parties' GNNs. Moreover, existing SFL models require substantial labeled data, which limits their practical applications. To overcome these limitations, we present a novel SFL framework called FedMpa that aims to learn cross-subgraph node representations. FedMpa first trains a multilayer perceptron (MLP) model using a small amount of data and then propagates the federated feature to the local structures. To further improve the embedding representation of nodes with local subgraphs, we introduce the FedMpae method, which reconstructs the local graph structure with an innovation view that applies pooling operation to form super-nodes. Our extensive experiments on six graph datasets demonstrate that FedMpa is highly effective in node classification. Furthermore, our ablation experiments verify the effectiveness of FedMpa.
PrUE: Distilling Knowledge from Sparse Teacher Networks
Jul 03, 2022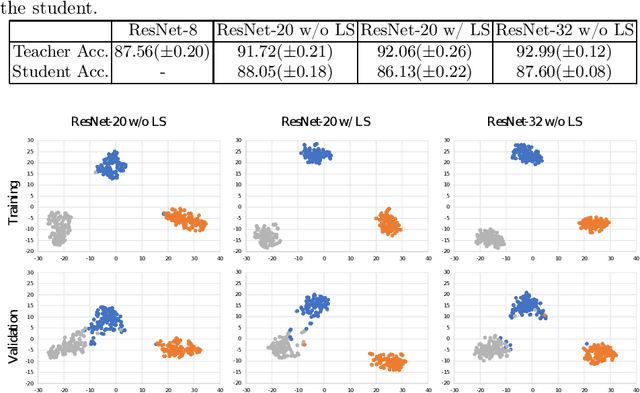
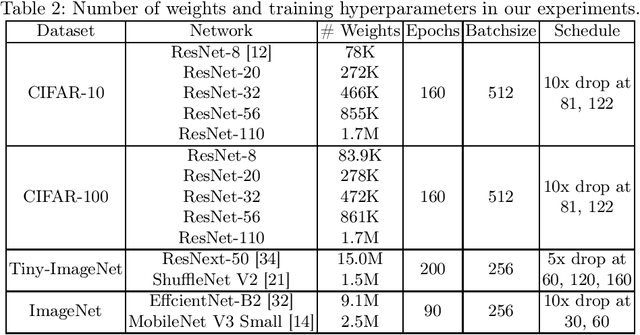
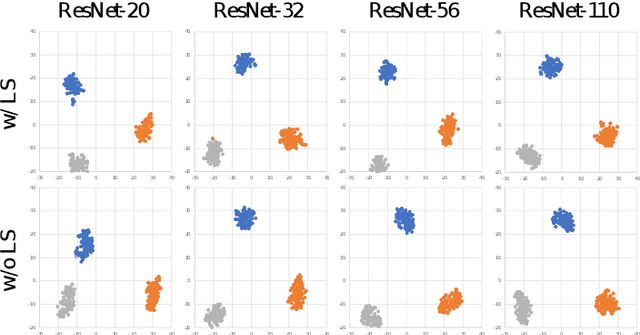

Although deep neural networks have enjoyed remarkable success across a wide variety of tasks, their ever-increasing size also imposes significant overhead on deployment. To compress these models, knowledge distillation was proposed to transfer knowledge from a cumbersome (teacher) network into a lightweight (student) network. However, guidance from a teacher does not always improve the generalization of students, especially when the size gap between student and teacher is large. Previous works argued that it was due to the high certainty of the teacher, resulting in harder labels that were difficult to fit. To soften these labels, we present a pruning method termed Prediction Uncertainty Enlargement (PrUE) to simplify the teacher. Specifically, our method aims to decrease the teacher's certainty about data, thereby generating soft predictions for students. We empirically investigate the effectiveness of the proposed method with experiments on CIFAR-10/100, Tiny-ImageNet, and ImageNet. Results indicate that student networks trained with sparse teachers achieve better performance. Besides, our method allows researchers to distill knowledge from deeper networks to improve students further. Our code is made public at: \url{https://github.com/wangshaopu/prue}.