 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptAL: Sample-Aware Dynamic Soft Prompts for Few-Shot Active Learning
Jul 22, 2025Active learning (AL) aims to optimize model training and reduce annotation costs by selecting the most informative samples for labeling. Typically, AL methods rely on the empirical distribution of labeled data to define the decision boundary and perform uncertainty or diversity estimation, subsequently identifying potential high-quality samples. In few-shot scenarios, the empirical distribution often diverges significantly from the target distribution, causing the decision boundary to shift away from its optimal position. However, existing methods overlook the role of unlabeled samples in enhancing the empirical distribution to better align with the target distribution, resulting in a suboptimal decision boundary and the selection of samples that inadequately represent the target distribution. To address this, we propose a hybrid AL framework, termed \textbf{PromptAL} (Sample-Aware Dynamic Soft \textbf{Prompts} for Few-Shot \textbf{A}ctive \textbf{L}earning). This framework accounts for the contribution of each unlabeled data point in aligning the current empirical distribution with the target distribution, thereby optimizing the decision boundary. Specifically, PromptAL first leverages unlabeled data to construct sample-aware dynamic soft prompts that adjust the model's predictive distribution and decision boundary. Subsequently, based on the adjusted decision boundary, it integrates uncertainty estimation with both global and local diversity to select high-quality samples that more accurately represent the target distribution. Experimental results on six in-domain and three out-of-domain datasets show that PromptAL achieves superior performance over nine baselines. Our codebase is openly accessible.
Prompt2Gaussia: Uncertain Prompt-learning for Script Event Prediction
Aug 04, 2023



Script Event Prediction (SEP) aims to predict the subsequent event for a given event chain from a candidate list. Prior research has achieved great success by integrating external knowledge to enhance the semantics, but it is laborious to acquisite the appropriate knowledge resources and retrieve the script-related knowledge. In this paper, we regard public pre-trained language models as knowledge bases and automatically mine the script-related knowledge via prompt-learning. Still, the scenario-diversity and label-ambiguity in scripts make it uncertain to construct the most functional prompt and label token in prompt learning, i.e., prompt-uncertainty and verbalizer-uncertainty. Considering the innate ability of Gaussian distribution to express uncertainty, we deploy the prompt tokens and label tokens as random variables following Gaussian distributions, where a prompt estimator and a verbalizer estimator are proposed to estimate their probabilistic representations instead of deterministic representations. We take the lead to explore prompt-learning in SEP and provide a fresh perspective to enrich the script semantics. Our method is evaluated on the most widely used benchmark and a newly proposed large-scale one. Experiments show that our method, which benefits from knowledge evoked from pre-trained language models, outperforms prior baselines by 1.46\% and 1.05\% on two benchmarks, respectively.
Enhancing Multimodal Entity and Relation Extraction with Variational Information Bottleneck
Apr 05, 2023


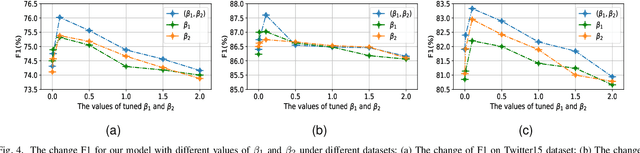
This paper studies the multimodal named entity recognition (MNER) and multimodal relation extraction (MRE), which are important for multimedia social platform analysis. The core of MNER and MRE lies in incorporating evident visual information to enhance textual semantics, where two issues inherently demand investigations. The first issue is modality-noise, where the task-irrelevant information in each modality may be noises misleading the task prediction. The second issue is modality-gap, where representations from different modalities are inconsistent, preventing from building the semantic alignment between the text and image. To address these issues, we propose a novel method for MNER and MRE by Multi-Modal representation learning with Information Bottleneck (MMIB). For the first issue, a refinement-regularizer probes the information-bottleneck principle to balance the predictive evidence and noisy information, yielding expressive representations for prediction. For the second issue, an alignment-regularizer is proposed, where a mutual information-based item works in a contrastive manner to regularize the consistent text-image representations. To our best knowledge, we are the first to explore variational IB estimation for MNER and MRE. Experiments show that MMIB achieves the state-of-the-art performances on three public benchmarks.
URM4DMU: an user represention model for darknet markets users
Mar 19, 2023

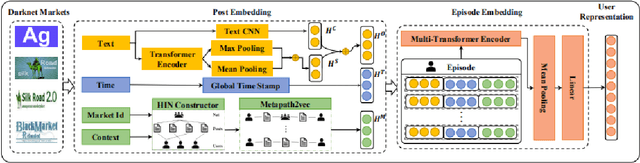

Darknet markets provide a large platform for trading illicit goods and services due to their anonymity. Learning an invariant representation of each user based on their posts on different markets makes it easy to aggregate user information across different platforms, which helps identify anonymous users. Traditional user representation methods mainly rely on modeling the text information of posts and cannot capture the temporal content and the forum interaction of posts. While recent works mainly use CNN to model the text information of posts, failing to effectively model posts whose length changes frequently in an episode. To address the above problems, we propose a model named URM4DMU(User Representation Model for Darknet Markets Users) which mainly improves the post representation by augmenting convolutional operators and self-attention with an adaptive gate mechanism. It performs much better when combined with the temporal content and the forum interaction of posts. We demonstrate the effectiveness of URM4DMU on four darknet markets. The average improvements on MRR value and Recall@10 are 22.5% and 25.5% over the state-of-the-art method respectively.
Event Causality Extraction with Event Argument Correlations
Jan 27, 2023


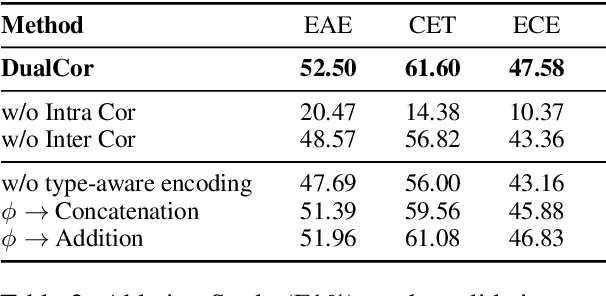
Event Causality Identification (ECI), which aims to detect whether a causality relation exists between two given textual events, is an important task for event causality understanding. However, the ECI task ignores crucial event structure and cause-effect causality component information, making it struggle for downstream applications. In this paper, we explore a novel task, namely Event Causality Extraction (ECE), aiming to extract the cause-effect event causality pairs with their structured event information from plain texts. The ECE task is more challenging since each event can contain multiple event arguments, posing fine-grained correlations between events to decide the causeeffect event pair. Hence, we propose a method with a dual grid tagging scheme to capture the intra- and inter-event argument correlations for ECE. Further, we devise a event type-enhanced model architecture to realize the dual grid tagging scheme. Experiments demonstrate the effectiveness of our method, and extensive analyses point out several future directions for ECE.
PrUE: Distilling Knowledge from Sparse Teacher Networks
Jul 03, 2022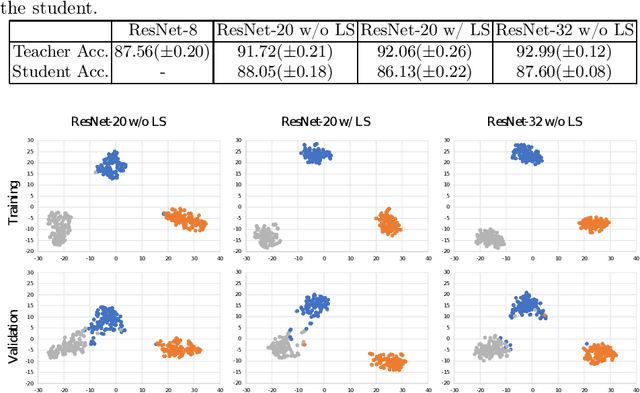
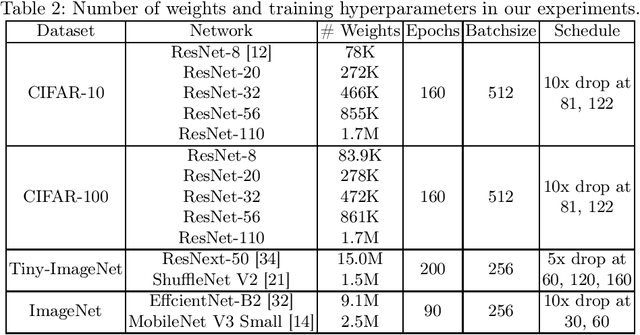
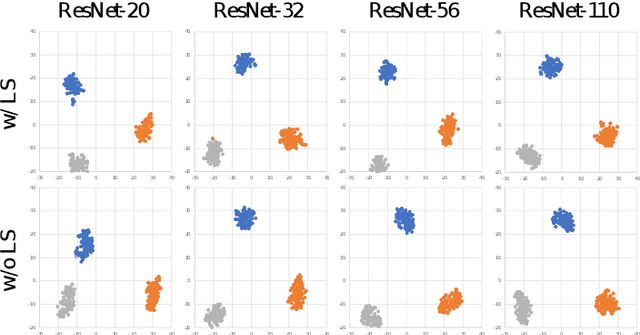

Although deep neural networks have enjoyed remarkable success across a wide variety of tasks, their ever-increasing size also imposes significant overhead on deployment. To compress these models, knowledge distillation was proposed to transfer knowledge from a cumbersome (teacher) network into a lightweight (student) network. However, guidance from a teacher does not always improve the generalization of students, especially when the size gap between student and teacher is large. Previous works argued that it was due to the high certainty of the teacher, resulting in harder labels that were difficult to fit. To soften these labels, we present a pruning method termed Prediction Uncertainty Enlargement (PrUE) to simplify the teacher. Specifically, our method aims to decrease the teacher's certainty about data, thereby generating soft predictions for students. We empirically investigate the effectiveness of the proposed method with experiments on CIFAR-10/100, Tiny-ImageNet, and ImageNet. Results indicate that student networks trained with sparse teachers achieve better performance. Besides, our method allows researchers to distill knowledge from deeper networks to improve students further. Our code is made public at: \url{https://github.com/wangshaopu/prue}.
Document-Level Event Extraction via Human-Like Reading Process
Feb 07, 2022
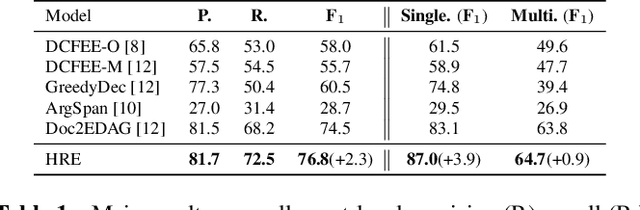
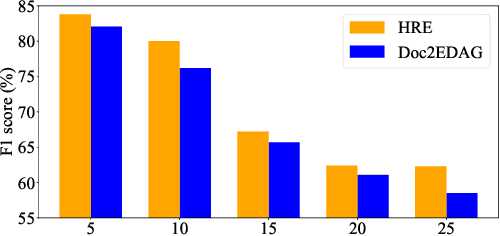
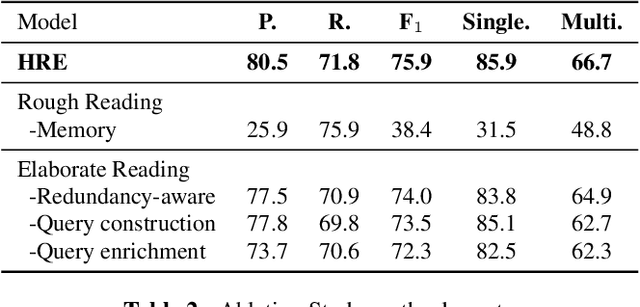
Document-level Event Extraction (DEE) is particularly tricky due to the two challenges it poses: scattering-arguments and multi-events. The first challenge means that arguments of one event record could reside in different sentences in the document, while the second one reflects one document may simultaneously contain multiple such event records. Motivated by humans' reading cognitive to extract information of interests, in this paper, we propose a method called HRE (Human Reading inspired Extractor for Document Events), where DEE is decomposed into these two iterative stages, rough reading and elaborate reading. Specifically, the first stage browses the document to detect the occurrence of events, and the second stage serves to extract specific event arguments. For each concrete event role, elaborate reading hierarchically works from sentences to characters to locate arguments across sentences, thus the scattering-arguments problem is tackled. Meanwhile, rough reading is explored in a multi-round manner to discover undetected events, thus the multi-events problem is handled. Experiment results show the superiority of HRE over prior competitive methods.
Label Enhanced Event Detection with Heterogeneous Graph Attention Networks
Dec 03, 2020
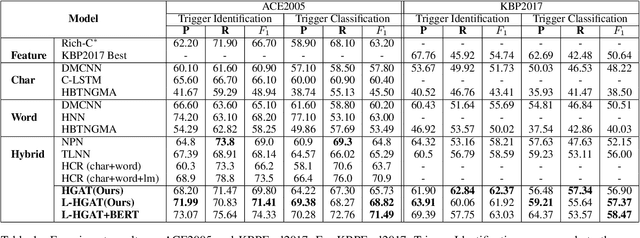
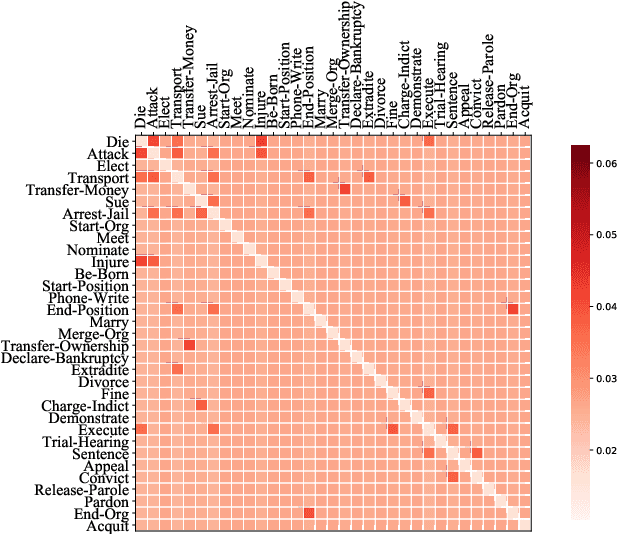
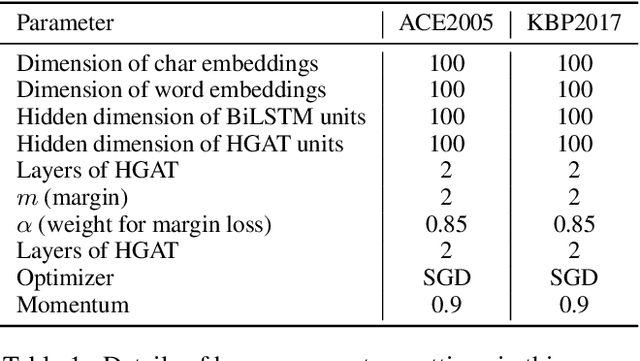
Event Detection (ED) aims to recognize instances of specified types of event triggers in text. Different from English ED, Chinese ED suffers from the problem of word-trigger mismatch due to the uncertain word boundaries. Existing approaches injecting word information into character-level models have achieved promising progress to alleviate this problem, but they are limited by two issues. First, the interaction between characters and lexicon words is not fully exploited. Second, they ignore the semantic information provided by event labels. We thus propose a novel architecture named Label enhanced Heterogeneous Graph Attention Networks (L-HGAT). Specifically, we transform each sentence into a graph, where character nodes and word nodes are connected with different types of edges, so that the interaction between words and characters is fully reserved. A heterogeneous graph attention networks is then introduced to propagate relational message and enrich information interaction. Furthermore, we convert each label into a trigger-prototype-based embedding, and design a margin loss to guide the model distinguish confusing event labels. Experiments on two benchmark datasets show that our model achieves significant improvement over a range of competitive baseline methods.
Event Detection with Relation-Aware Graph Convolutional Neural Networks
Feb 25, 2020
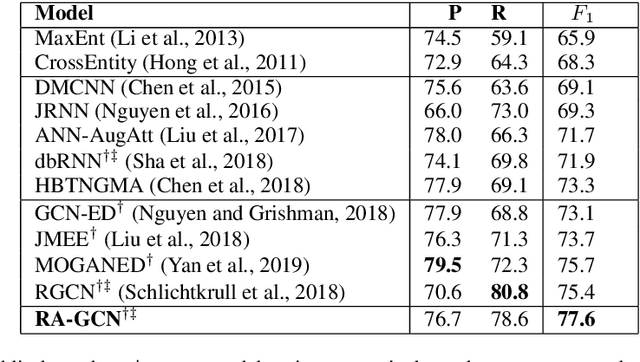
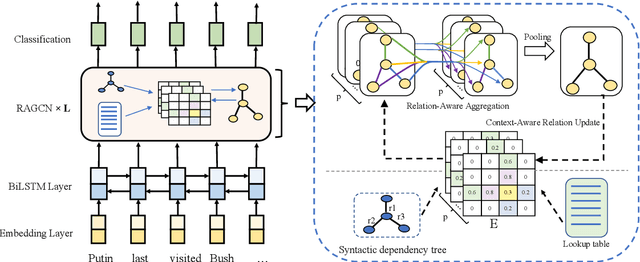
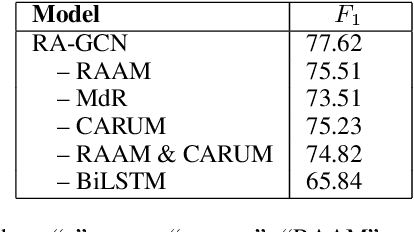
Event detection (ED), a key subtask of information extraction, aims to recognize instances of specific types of events in text. Recently, graph convolutional networks (GCNs) over dependency trees have been widely used to capture syntactic structure information and get convincing performances in event detection. However, these works ignore the syntactic relation labels on the tree, which convey rich and useful linguistic knowledge for event detection. In this paper, we investigate a novel architecture named Relation-Aware GCN (RA-GCN), which efficiently exploits syntactic relation labels and models the relation between words specifically. We first propose a relation-aware aggregation module to produce expressive word representation by aggregating syntactically connected words through specific relation. Furthermore, a context-aware relation update module is designed to explicitly update the relation representation between words, and these two modules work in the mutual promotion way. Experimental results on the ACE2005 dataset show that our model achieves a new state-of-the-art performance for event detection.