 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrUE: Distilling Knowledge from Sparse Teacher Networks
Paper and Code
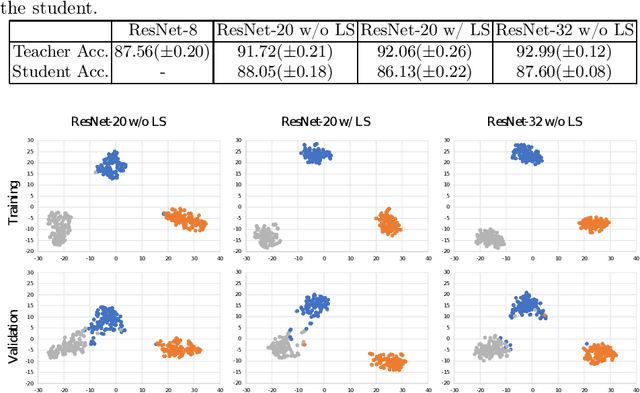
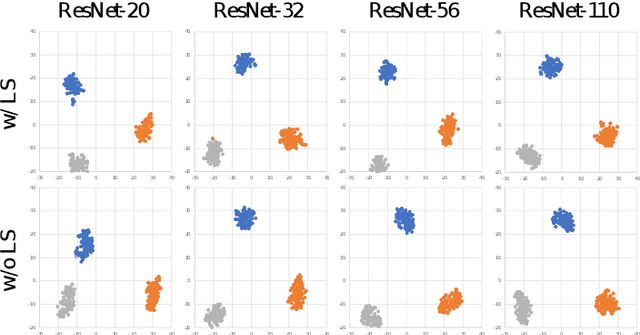

Although deep neural networks have enjoyed remarkable success across a wide variety of tasks, their ever-increasing size also imposes significant overhead on deployment. To compress these models, knowledge distillation was proposed to transfer knowledge from a cumbersome (teacher) network into a lightweight (student) network. However, guidance from a teacher does not always improve the generalization of students, especially when the size gap between student and teacher is large. Previous works argued that it was due to the high certainty of the teacher, resulting in harder labels that were difficult to fit. To soften these labels, we present a pruning method termed Prediction Uncertainty Enlargement (PrUE) to simplify the teacher. Specifically, our method aims to decrease the teacher's certainty about data, thereby generating soft predictions for students. We empirically investigate the effectiveness of the proposed method with experiments on CIFAR-10/100, Tiny-ImageNet, and ImageNet. Results indicate that student networks trained with sparse teachers achieve better performance. Besides, our method allows researchers to distill knowledge from deeper networks to improve students further. Our code is made public at: \url{https://github.com/wangshaopu/prue}.