 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRE: Encouraging Exploration in the Trust Region
Feb 03, 2026Entropy regularization is a standard technique in reinforcement learning (RL) to enhance exploration, yet it yields negligible effects or even degrades performance in Large Language Models (LLMs). We attribute this failure to the cumulative tail risk inherent to LLMs with massive vocabularies and long generation horizons. In such environments, standard global entropy maximization indiscriminately dilutes probability mass into the vast tail of invalid tokens rather than focusing on plausible candidates, thereby disrupting coherent reasoning. To address this, we propose Trust Region Entropy (TRE), a method that encourages exploration strictly within the model's trust region. Extensive experiments across mathematical reasoning (MATH), combinatorial search (Countdown), and preference alignment (HH) tasks demonstrate that TRE consistently outperforms vanilla PPO, standard entropy regularization, and other exploration baselines. Our code is available at https://github.com/WhyChaos/TRE-Encouraging-Exploration-in-the-Trust-Region.
CDRNP: Cross-Domain Recommendation to Cold-Start Users via Neural Process
Jan 23, 2024



Cross-domain recommendation (CDR) has been proven as a promising way to tackle the user cold-start problem, which aims to make recommendations for users in the target domain by transferring the user preference derived from the source domain. Traditional CDR studies follow the embedding and mapping (EMCDR) paradigm, which transfers user representations from the source to target domain by learning a user-shared mapping function, neglecting the user-specific preference. Recent CDR studies attempt to learn user-specific mapping functions in meta-learning paradigm, which regards each user's CDR as an individual task, but neglects the preference correlations among users, limiting the beneficial information for user representations. Moreover, both of the paradigms neglect the explicit user-item interactions from both domains during the mapping process. To address the above issues, this paper proposes a novel CDR framework with neural process (NP), termed as CDRNP. Particularly, it develops the meta-learning paradigm to leverage user-specific preference, and further introduces a stochastic process by NP to capture the preference correlations among the overlapping and cold-start users, thus generating more powerful mapping functions by mapping the user-specific preference and common preference correlations to a predictive probability distribution. In addition, we also introduce a preference remainer to enhance the common preference from the overlapping users, and finally devises an adaptive conditional decoder with preference modulation to make prediction for cold-start users with items in the target domain. Experimental results demonstrate that CDRNP outperforms previous SOTA methods in three real-world CDR scenarios.
Enhancing Multimodal Entity and Relation Extraction with Variational Information Bottleneck
Apr 05, 2023


This paper studies the multimodal named entity recognition (MNER) and multimodal relation extraction (MRE), which are important for multimedia social platform analysis. The core of MNER and MRE lies in incorporating evident visual information to enhance textual semantics, where two issues inherently demand investigations. The first issue is modality-noise, where the task-irrelevant information in each modality may be noises misleading the task prediction. The second issue is modality-gap, where representations from different modalities are inconsistent, preventing from building the semantic alignment between the text and image. To address these issues, we propose a novel method for MNER and MRE by Multi-Modal representation learning with Information Bottleneck (MMIB). For the first issue, a refinement-regularizer probes the information-bottleneck principle to balance the predictive evidence and noisy information, yielding expressive representations for prediction. For the second issue, an alignment-regularizer is proposed, where a mutual information-based item works in a contrastive manner to regularize the consistent text-image representations. To our best knowledge, we are the first to explore variational IB estimation for MNER and MRE. Experiments show that MMIB achieves the state-of-the-art performances on three public benchmarks.
Label Enhanced Event Detection with Heterogeneous Graph Attention Networks
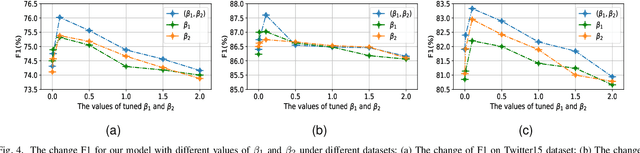
Dec 03, 2020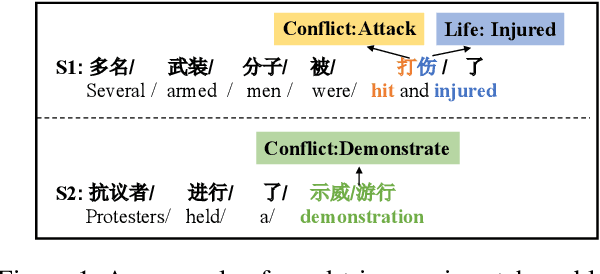
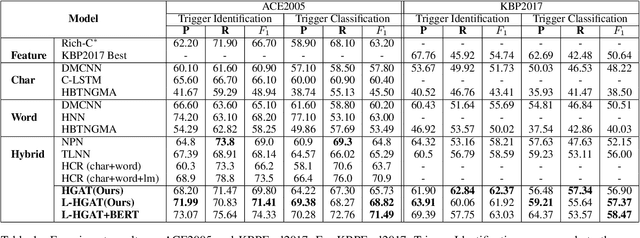
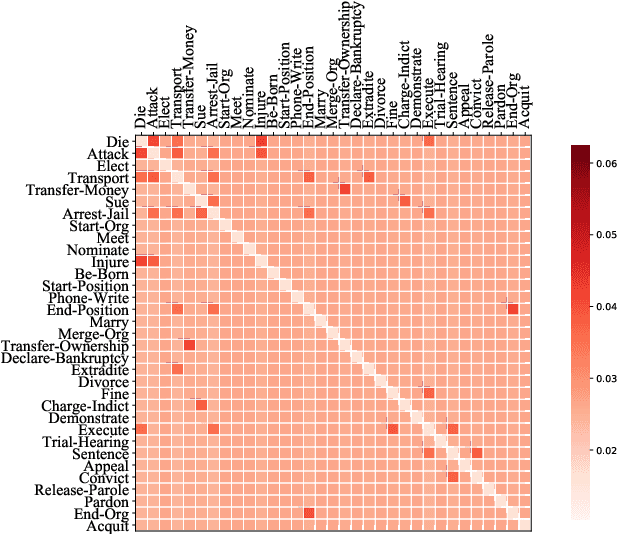
Event Detection (ED) aims to recognize instances of specified types of event triggers in text. Different from English ED, Chinese ED suffers from the problem of word-trigger mismatch due to the uncertain word boundaries. Existing approaches injecting word information into character-level models have achieved promising progress to alleviate this problem, but they are limited by two issues. First, the interaction between characters and lexicon words is not fully exploited. Second, they ignore the semantic information provided by event labels. We thus propose a novel architecture named Label enhanced Heterogeneous Graph Attention Networks (L-HGAT). Specifically, we transform each sentence into a graph, where character nodes and word nodes are connected with different types of edges, so that the interaction between words and characters is fully reserved. A heterogeneous graph attention networks is then introduced to propagate relational message and enrich information interaction. Furthermore, we convert each label into a trigger-prototype-based embedding, and design a margin loss to guide the model distinguish confusing event labels. Experiments on two benchmark datasets show that our model achieves significant improvement over a range of competitive baseline methods.