 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHerculean: An Agentic Benchmark for Financial Intelligence
May 14, 2026As AI agents improve, the central question is no longer whether they can solve isolated well-defined financial tasks, but whether they can reliably carry out financial professional work. Existing financial benchmarks offer only a partial view of this ability, as they primarily evaluate static competencies such as question answering, retrieval, summarization, and classification. We introduce Herculean, the first skilled benchmark for agentic financial intelligence spanning four representative workflows, including Trading, Hedging, Market Insights, and Auditing. Each workflow is instantiated as a standardized MCP-based skill environment with its own tools, interaction dynamics, constraints, and success criteria, enabling consistent end-to-end assessment of heterogeneous agent systems. Across frontier agents, we find agents perform relatively well on Trading and Market Insights, but struggle substantially on Hedging and Auditing, where long-horizon coordination, state consistency, and structured verification are critical. Overall, our results point to a key gap in current agents in turning financial reasoning into dependable workflow execution in high-stakes financial workflows.
From Sparse to Dense: Spatio-Temporal Fusion for Multi-View 3D Human Pose Estimation with DenseWarper
May 14, 2026In multi-view 3D human pose estimation, models typically rely on images captured simultaneously from different camera views to predict a pose at a specific moment. While providing accurate spatial information, this traditional approach often overlooks the rich temporal dependencies between adjacent frames. We propose a novel 3D human pose estimation input method: the sparse interleaved input to address this. This method leverages images captured from different camera views at various time points (e.g., View 1 at time $t$ and View 2 at time $t+δ$), allowing our model to capture rich spatio-temporal information and effectively boost performance. More importantly, this approach offers two key advantages: First, it can theoretically increase the output pose frame rate by N times with N cameras, thereby breaking through single-view frame rate limitations and enhancing the temporal resolution of the production. Second, using a sparse subset of available frames, our method can reduce data redundancy and simultaneously achieve better performance. We introduce the DenseWarper model, which leverages epipolar geometry for efficient spatio-temporal heatmap exchange. We conducted extensive experiments on the Human3.6M and MPI-INF-3DHP datasets. Results demonstrate that our method, utilizing only sparse interleaved images as input, outperforms traditional dense multi-view input approaches and achieves state-of-the-art performance. The source code for this work is available at: https://github.com/lingli1724/DenseWarper-ICLR2026
Moira: Language-driven Hierarchical Reinforcement Learning for Pair Trading
May 03, 2026Many sequential decision-making problems exhibit hierarchical structure, where high-level semantic choices constrain downstream actions and feedback is delayed and ambiguous. Learning in such settings is challenging due to credit assignment: performance degradation may arise from flawed abstractions, suboptimal execution, or their interaction. We study this challenge through pair trading, a domain that naturally combines long-horizon semantic reasoning for asset pair selection with short-horizon execution under partial observability. We formulate pair trading as a hierarchical reinforcement learning problem and propose a language-driven optimization framework in which both high-level and low-level policies are parameterized by large language models (LLMs) and optimized exclusively through prompt updates. Our approach leverages pretrained LLMs as hierarchical policies and uses trajectory- and episode-level textual feedback to adapt abstractions and execution without gradient-based fine-tuning. By explicitly separating abstraction selection from execution, the framework reduces non-stationarity across hierarchical levels and enables targeted adaptation under delayed feedback. Experiments on real-world market data show consistent improvements over traditional and LLM-based baselines, demonstrating the effectiveness of language-driven hierarchical reinforcement learning.
Neural Network-based Partial-Linear Single-Index Models for Environmental Mixtures Analysis
Dec 12, 2025Evaluating the health effects of complex environmental mixtures remains a central challenge in environmental health research. Existing approaches vary in their flexibility, interpretability, scalability, and support for diverse outcome types, often limiting their utility in real-world applications. To address these limitations, we propose a neural network-based partial-linear single-index (NeuralPLSI) modeling framework that bridges semiparametric regression modeling interpretability with the expressive power of deep learning. The NeuralPLSI model constructs an interpretable exposure index via a learnable projection and models its relationship with the outcome through a flexible neural network. The framework accommodates continuous, binary, and time-to-event outcomes, and supports inference through a bootstrap-based procedure that yields confidence intervals for key model parameters. We evaluated NeuralPLSI through simulation studies under a range of scenarios and applied it to data from the National Health and Nutrition Examination Survey (NHANES) to demonstrate its practical utility. Together, our contributions establish NeuralPLSI as a scalable, interpretable, and versatile modeling tool for mixture analysis. To promote adoption and reproducibility, we release a user-friendly open-source software package that implements the proposed methodology and supports downstream visualization and inference (\texttt{https://github.com/hyungrok-do/NeuralPLSI}).
Are LLMs The Way Forward? A Case Study on LLM-Guided Reinforcement Learning for Decentralized Autonomous Driving
Nov 16, 2025Autonomous vehicle navigation in complex environments such as dense and fast-moving highways and merging scenarios remains an active area of research. A key limitation of RL is its reliance on well-specified reward functions, which often fail to capture the full semantic and social complexity of diverse, out-of-distribution situations. As a result, a rapidly growing line of research explores using Large Language Models (LLMs) to replace or supplement RL for direct planning and control, on account of their ability to reason about rich semantic context. However, LLMs present significant drawbacks: they can be unstable in zero-shot safety-critical settings, produce inconsistent outputs, and often depend on expensive API calls with network latency. This motivates our investigation into whether small, locally deployed LLMs (< 14B parameters) can meaningfully support autonomous highway driving through reward shaping rather than direct control. We present a case study comparing RL-only, LLM-only, and hybrid approaches, where LLMs augment RL rewards by scoring state-action transitions during training, while standard RL policies execute at test time. Our findings reveal that RL-only agents achieve moderate success rates (73-89%) with reasonable efficiency, LLM-only agents can reach higher success rates (up to 94%) but with severely degraded speed performance, and hybrid approaches consistently fall between these extremes. Critically, despite explicit efficiency instructions, LLM-influenced approaches exhibit systematic conservative bias with substantial model-dependent variability, highlighting important limitations of current small LLMs for safety-critical control tasks.
OpenCUA: Open Foundations for Computer-Use Agents
Aug 12, 2025Vision-language models have demonstrated impressive capabilities as computer-use agents (CUAs) capable of automating diverse computer tasks. As their commercial potential grows, critical details of the most capable CUA systems remain closed. As these agents will increasingly mediate digital interactions and execute consequential decisions on our behalf, the research community needs access to open CUA frameworks to study their capabilities, limitations, and risks. To bridge this gap, we propose OpenCUA, a comprehensive open-source framework for scaling CUA data and foundation models. Our framework consists of: (1) an annotation infrastructure that seamlessly captures human computer-use demonstrations; (2) AgentNet, the first large-scale computer-use task dataset spanning 3 operating systems and 200+ applications and websites; (3) a scalable pipeline that transforms demonstrations into state-action pairs with reflective long Chain-of-Thought reasoning that sustain robust performance gains as data scales. Our end-to-end agent models demonstrate strong performance across CUA benchmarks. In particular, OpenCUA-32B achieves an average success rate of 34.8% on OSWorld-Verified, establishing a new state-of-the-art (SOTA) among open-source models and surpassing OpenAI CUA (GPT-4o). Further analysis confirms that our approach generalizes well across domains and benefits significantly from increased test-time computation. We release our annotation tool, datasets, code, and models to build open foundations for further CUA research.
Moving Out: Physically-grounded Human-AI Collaboration
Jul 24, 2025The ability to adapt to physical actions and constraints in an environment is crucial for embodied agents (e.g., robots) to effectively collaborate with humans. Such physically grounded human-AI collaboration must account for the increased complexity of the continuous state-action space and constrained dynamics caused by physical constraints. In this paper, we introduce \textit{Moving Out}, a new human-AI collaboration benchmark that resembles a wide range of collaboration modes affected by physical attributes and constraints, such as moving heavy items together and maintaining consistent actions to move a big item around a corner. Using Moving Out, we designed two tasks and collected human-human interaction data to evaluate models' abilities to adapt to diverse human behaviors and unseen physical attributes. To address the challenges in physical environments, we propose a novel method, BASS (Behavior Augmentation, Simulation, and Selection), to enhance the diversity of agents and their understanding of the outcome of actions. Our experiments show that BASS outperforms state-of-the-art models in AI-AI and human-AI collaboration. The project page is available at \href{https://live-robotics-uva.github.io/movingout_ai/}{https://live-robotics-uva.github.io/movingout\_ai/}.
The Blessing of Reasoning: LLM-Based Contrastive Explanations in Black-Box Recommender Systems
Feb 24, 2025

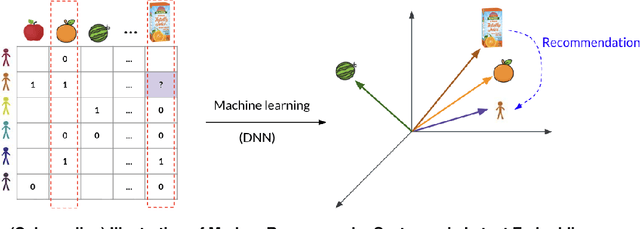
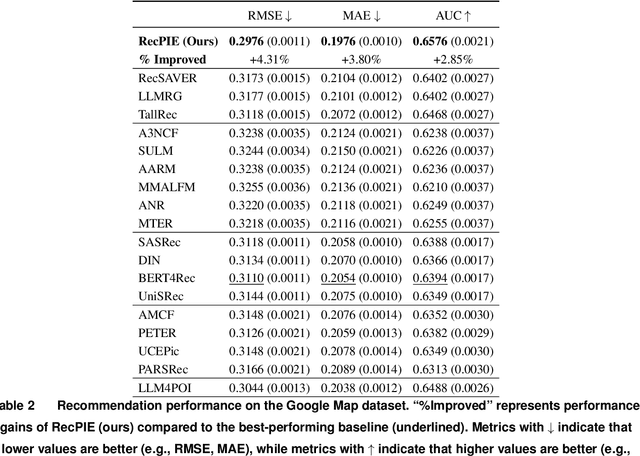
Modern recommender systems use ML models to predict consumer preferences from consumption history. Although these "black-box" models achieve impressive predictive performance, they often suffer from a lack of transparency and explainability. Contrary to the presumed tradeoff between explainability and accuracy, we show that integrating large language models (LLMs) with deep neural networks (DNNs) can improve both. We propose LR-Recsys, which augments DNN-based systems with LLM reasoning capabilities. LR-Recsys introduces a contrastive-explanation generator that produces human-readable positive explanations and negative explanations. These explanations are embedded via a fine-tuned autoencoder and combined with consumer and product features to improve predictions. Beyond offering explainability, we show that LR-Recsys also improves learning efficiency and predictive accuracy, as supported by high-dimensional, multi-environment statistical learning theory. LR-Recsys outperforms state-of-the-art recommender systems by 3-14% on three real-world datasets. Importantly, our analysis reveals that these gains primarily derive from LLMs' reasoning capabilities rather than their external domain knowledge. LR-RecSys presents an effective approach to combine LLMs with traditional DNNs, two of the most widely used ML models today. The explanations generated by LR-Recsys provide actionable insights for consumers, sellers, and platforms, helping to build trust, optimize product offerings, and inform targeting strategies.
Warm-starting Push-Relabel
May 28, 2024



Push-Relabel is one of the most celebrated network flow algorithms. Maintaining a pre-flow that saturates a cut, it enjoys better theoretical and empirical running time than other flow algorithms, such as Ford-Fulkerson. In practice, Push-Relabel is even faster than what theoretical guarantees can promise, in part because of the use of good heuristics for seeding and updating the iterative algorithm. However, it remains unclear how to run Push-Relabel on an arbitrary initialization that is not necessarily a pre-flow or cut-saturating. We provide the first theoretical guarantees for warm-starting Push-Relabel with a predicted flow, where our learning-augmented version benefits from fast running time when the predicted flow is close to an optimal flow, while maintaining robust worst-case guarantees. Interestingly, our algorithm uses the gap relabeling heuristic, which has long been employed in practice, even though prior to our work there was no rigorous theoretical justification for why it can lead to run-time improvements. We then provide experiments that show our warm-started Push-Relabel also works well in practice.
Diversifying by Intent in Recommender Systems
May 20, 2024It has become increasingly clear that recommender systems overly focusing on short-term engagement can inadvertently hurt long-term user experience. However, it is challenging to optimize long-term user experience directly as the desired signal is sparse, noisy and manifests over a long horizon. In this work, we show the benefits of incorporating higher-level user understanding, specifically user intents that can persist across multiple interactions or recommendation sessions, for whole-page recommendation toward optimizing long-term user experience. User intent has primarily been investigated within the context of search, but remains largely under-explored for recommender systems. To bridge this gap, we develop a probabilistic intent-based whole-page diversification framework in the final stage of a recommender system. Starting with a prior belief of user intents, the proposed diversification framework sequentially selects items at each position based on these beliefs, and subsequently updates posterior beliefs about the intents. It ensures that different user intents are represented in a page towards optimizing long-term user experience. We experiment with the intent diversification framework on one of the world's largest content recommendation platforms, serving billions of users daily. Our framework incorporates the user's exploration intent, capturing their propensity to explore new interests and content. Live experiments show that the proposed framework leads to an increase in user retention and overall user enjoyment, validating its effectiveness in facilitating long-term planning. In particular, it enables users to consistently discover and engage with diverse contents that align with their underlying intents over time, thereby leading to an improved long-term user experience.