 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Semantic ID for Generative Recommendation
Jan 27, 2026Generative recommendation provides a novel paradigm in which each item is represented by a discrete semantic ID (SID) learned from rich content. Most existing methods treat SIDs as predefined and train recommenders under static indexing. In practice, SIDs are typically optimized only for content reconstruction rather than recommendation accuracy. This leads to an objective mismatch: the system optimizes an indexing loss to learn the SID and a recommendation loss for interaction prediction, but because the tokenizer is trained independently, the recommendation loss cannot update it. A natural approach is to make semantic indexing differentiable so that recommendation gradients can directly influence SID learning, but this often causes codebook collapse, where only a few codes are used. We attribute this issue to early deterministic assignments that limit codebook exploration, resulting in imbalance and unstable optimization. In this paper, we propose DIGER (Differentiable Semantic ID for Generative Recommendation), a first step toward effective differentiable semantic IDs for generative recommendation. DIGER introduces Gumbel noise to explicitly encourage early-stage exploration over codes, mitigating codebook collapse and improving code utilization. To balance exploration and convergence, we further design two uncertainty decay strategies that gradually reduce the Gumbel noise, enabling a smooth transition from early exploration to exploitation of learned SIDs. Extensive experiments on multiple public datasets demonstrate consistent improvements from differentiable semantic IDs. These results confirm the effectiveness of aligning indexing and recommendation objectives through differentiable SIDs and highlight differentiable semantic indexing as a promising research direction.
Hyperbolic Residual Quantization: Discrete Representations for Data with Latent Hierarchies
May 18, 2025Hierarchical data arise in countless domains, from biological taxonomies and organizational charts to legal codes and knowledge graphs. Residual Quantization (RQ) is widely used to generate discrete, multitoken representations for such data by iteratively quantizing residuals in a multilevel codebook. However, its reliance on Euclidean geometry can introduce fundamental mismatches that hinder modeling of hierarchical branching, necessary for faithful representation of hierarchical data. In this work, we propose Hyperbolic Residual Quantization (HRQ), which embeds data natively in a hyperbolic manifold and performs residual quantization using hyperbolic operations and distance metrics. By adapting the embedding network, residual computation, and distance metric to hyperbolic geometry, HRQ imparts an inductive bias that aligns naturally with hierarchical branching. We claim that HRQ in comparison to RQ can generate more useful for downstream tasks discrete hierarchical representations for data with latent hierarchies. We evaluate HRQ on two tasks: supervised hierarchy modeling using WordNet hypernym trees, where the model is supervised to learn the latent hierarchy - and hierarchy discovery, where, while latent hierarchy exists in the data, the model is not directly trained or evaluated on a task related to the hierarchy. Across both scenarios, HRQ hierarchical tokens yield better performance on downstream tasks compared to Euclidean RQ with gains of up to $20\%$ for the hierarchy modeling task. Our results demonstrate that integrating hyperbolic geometry into discrete representation learning substantially enhances the ability to capture latent hierarchies.
The 1st EReL@MIR Workshop on Efficient Representation Learning for Multimodal Information Retrieval
Apr 21, 2025Multimodal representation learning has garnered significant attention in the AI community, largely due to the success of large pre-trained multimodal foundation models like LLaMA, GPT, Mistral, and CLIP. These models have achieved remarkable performance across various tasks of multimodal information retrieval (MIR), including web search, cross-modal retrieval, and recommender systems, etc. However, due to their enormous parameter sizes, significant efficiency challenges emerge across training, deployment, and inference stages when adapting these models' representation for IR tasks. These challenges present substantial obstacles to the practical adaptation of foundation models for representation learning in information retrieval tasks. To address these pressing issues, we propose organizing the first EReL@MIR workshop at the Web Conference 2025, inviting participants to explore novel solutions, emerging problems, challenges, efficiency evaluation metrics and benchmarks. This workshop aims to provide a platform for both academic and industry researchers to engage in discussions, share insights, and foster collaboration toward achieving efficient and effective representation learning for multimodal information retrieval in the era of large foundation models.
Large Language Model driven Policy Exploration for Recommender Systems
Jan 23, 2025



Recent advancements in Recommender Systems (RS) have incorporated Reinforcement Learning (RL), framing the recommendation as a Markov Decision Process (MDP). However, offline RL policies trained on static user data are vulnerable to distribution shift when deployed in dynamic online environments. Additionally, excessive focus on exploiting short-term relevant items can hinder exploration, leading to suboptimal recommendations and negatively impacting long-term user gains. Online RL-based RS also face challenges in production deployment, due to the risks of exposing users to untrained or unstable policies. Large Language Models (LLMs) offer a promising solution to mimic user objectives and preferences for pre-training policies offline to enhance the initial recommendations in online settings. Effectively managing distribution shift and balancing exploration are crucial for improving RL-based RS, especially when leveraging LLM-based pre-training. To address these challenges, we propose an Interaction-Augmented Learned Policy (iALP) that utilizes user preferences distilled from an LLM. Our approach involves prompting the LLM with user states to extract item preferences, learning rewards based on feedback, and updating the RL policy using an actor-critic framework. Furthermore, to deploy iALP in an online scenario, we introduce an adaptive variant, A-iALP, that implements a simple fine-tuning strategy (A-iALP$_{ft}$), and an adaptive approach (A-iALP$_{ap}$) designed to mitigate issues with compromised policies and limited exploration. Experiments across three simulated environments demonstrate that A-iALP introduces substantial performance improvements
Efficient and Effective Adaptation of Multimodal Foundation Models in Sequential Recommendation
Nov 05, 2024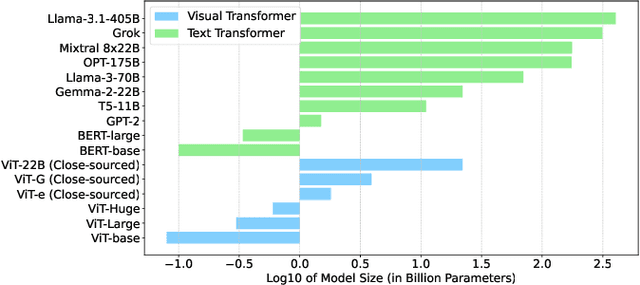
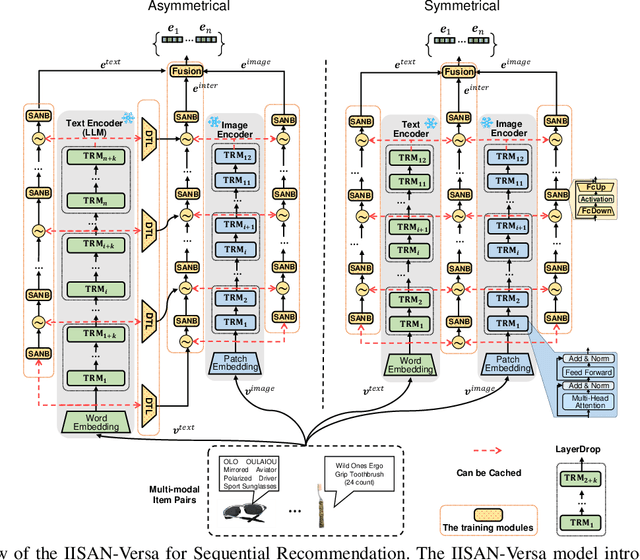
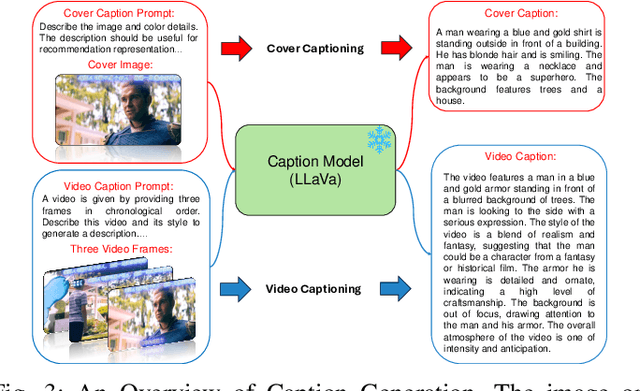
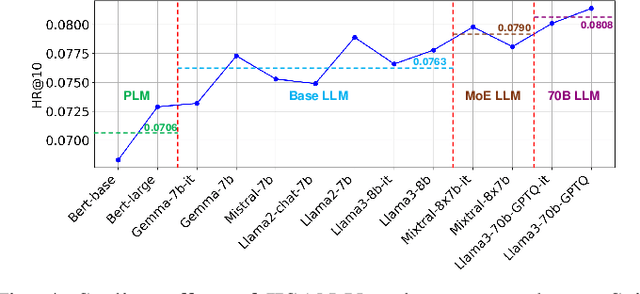
Multimodal foundation models (MFMs) have revolutionized sequential recommender systems through advanced representation learning. While Parameter-efficient Fine-tuning (PEFT) is commonly used to adapt these models, studies often prioritize parameter efficiency, neglecting GPU memory and training speed. To address this, we introduced the IISAN framework, significantly enhancing efficiency. However, IISAN was limited to symmetrical MFMs and identical text and image encoders, preventing the use of state-of-the-art Large Language Models. To overcome this, we developed IISAN-Versa, a versatile plug-and-play architecture compatible with both symmetrical and asymmetrical MFMs. IISAN-Versa employs a Decoupled PEFT structure and utilizes both intra- and inter-modal adaptation. It effectively handles asymmetry through a simple yet effective combination of group layer-dropping and dimension transformation alignment. Our research demonstrates that IISAN-Versa effectively adapts large text encoders, and we further identify a scaling effect where larger encoders generally perform better. IISAN-Versa also demonstrates strong versatility in our defined multimodal scenarios, which include raw titles and captions generated from images and videos. Additionally, IISAN-Versa achieved state-of-the-art performance on the Microlens public benchmark. We will release our code and datasets to support future research.
Seeing Eye to AI: Human Alignment via Gaze-Based Response Rewards for Large Language Models
Oct 02, 2024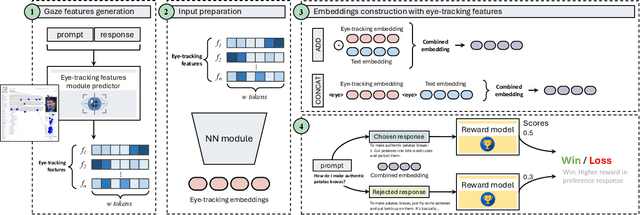

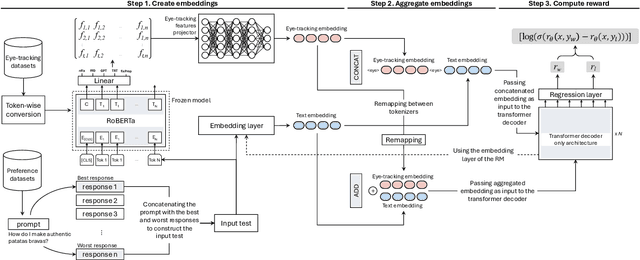

Advancements in Natural Language Processing (NLP), have led to the emergence of Large Language Models (LLMs) such as GPT, Llama, Claude, and Gemini, which excel across a range of tasks but require extensive fine-tuning to align their outputs with human expectations. A widely used method for achieving this alignment is Reinforcement Learning from Human Feedback (RLHF), which, despite its success, faces challenges in accurately modelling human preferences. In this paper, we introduce GazeReward, a novel framework that integrates implicit feedback -- and specifically eye-tracking (ET) data -- into the Reward Model (RM). In addition, we explore how ET-based features can provide insights into user preferences. Through ablation studies we test our framework with different integration methods, LLMs, and ET generator models, demonstrating that our approach significantly improves the accuracy of the RM on established human preference datasets. This work advances the ongoing discussion on optimizing AI alignment with human values, exploring the potential of cognitive data for shaping future NLP research.
PERSOMA: PERsonalized SOft ProMpt Adapter Architecture for Personalized Language Prompting
Aug 02, 2024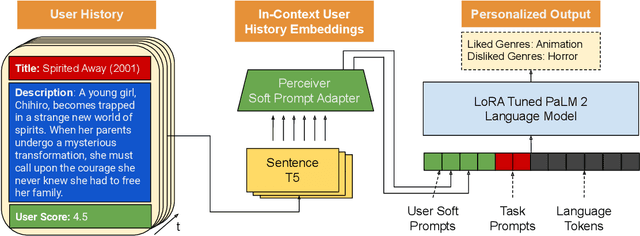



Understanding the nuances of a user's extensive interaction history is key to building accurate and personalized natural language systems that can adapt to evolving user preferences. To address this, we introduce PERSOMA, Personalized Soft Prompt Adapter architecture. Unlike previous personalized prompting methods for large language models, PERSOMA offers a novel approach to efficiently capture user history. It achieves this by resampling and compressing interactions as free form text into expressive soft prompt embeddings, building upon recent research utilizing embedding representations as input for LLMs. We rigorously validate our approach by evaluating various adapter architectures, first-stage sampling strategies, parameter-efficient tuning techniques like LoRA, and other personalization methods. Our results demonstrate PERSOMA's superior ability to handle large and complex user histories compared to existing embedding-based and text-prompt-based techniques.
IISAN: Efficiently Adapting Multimodal Representation for Sequential Recommendation with Decoupled PEFT
Apr 11, 2024Multimodal foundation models are transformative in sequential recommender systems, leveraging powerful representation learning capabilities. While Parameter-efficient Fine-tuning (PEFT) is commonly used to adapt foundation models for recommendation tasks, most research prioritizes parameter efficiency, often overlooking critical factors like GPU memory efficiency and training speed. Addressing this gap, our paper introduces IISAN (Intra- and Inter-modal Side Adapted Network for Multimodal Representation), a simple plug-and-play architecture using a Decoupled PEFT structure and exploiting both intra- and inter-modal adaptation. IISAN matches the performance of full fine-tuning (FFT) and state-of-the-art PEFT. More importantly, it significantly reduces GPU memory usage - from 47GB to just 3GB for multimodal sequential recommendation tasks. Additionally, it accelerates training time per epoch from 443s to 22s compared to FFT. This is also a notable improvement over the Adapter and LoRA, which require 37-39 GB GPU memory and 350-380 seconds per epoch for training. Furthermore, we propose a new composite efficiency metric, TPME (Training-time, Parameter, and GPU Memory Efficiency) to alleviate the prevalent misconception that "parameter efficiency represents overall efficiency". TPME provides more comprehensive insights into practical efficiency comparisons between different methods. Besides, we give an accessible efficiency analysis of all PEFT and FFT approaches, which demonstrate the superiority of IISAN. We release our codes and other materials at https://github.com/GAIR-Lab/IISAN.
Reinforcement Learning-based Recommender Systems with Large Language Models for State Reward and Action Modeling
Mar 25, 2024Reinforcement Learning (RL)-based recommender systems have demonstrated promising performance in meeting user expectations by learning to make accurate next-item recommendations from historical user-item interactions. However, existing offline RL-based sequential recommendation methods face the challenge of obtaining effective user feedback from the environment. Effectively modeling the user state and shaping an appropriate reward for recommendation remains a challenge. In this paper, we leverage language understanding capabilities and adapt large language models (LLMs) as an environment (LE) to enhance RL-based recommenders. The LE is learned from a subset of user-item interaction data, thus reducing the need for large training data, and can synthesise user feedback for offline data by: (i) acting as a state model that produces high quality states that enrich the user representation, and (ii) functioning as a reward model to accurately capture nuanced user preferences on actions. Moreover, the LE allows to generate positive actions that augment the limited offline training data. We propose a LE Augmentation (LEA) method to further improve recommendation performance by optimising jointly the supervised component and the RL policy, using the augmented actions and historical user signals. We use LEA, the state and reward models in conjunction with state-of-the-art RL recommenders and report experimental results on two publicly available datasets.
Latent User Intent Modeling for Sequential Recommenders
Nov 17, 2022Sequential recommender models are essential components of modern industrial recommender systems. These models learn to predict the next items a user is likely to interact with based on his/her interaction history on the platform. Most sequential recommenders however lack a higher-level understanding of user intents, which often drive user behaviors online. Intent modeling is thus critical for understanding users and optimizing long-term user experience. We propose a probabilistic modeling approach and formulate user intent as latent variables, which are inferred based on user behavior signals using variational autoencoders (VAE). The recommendation policy is then adjusted accordingly given the inferred user intent. We demonstrate the effectiveness of the latent user intent modeling via offline analyses as well as live experiments on a large-scale industrial recommendation platform.