 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Adaptive Visualizations for Critical Decision Making
Nov 14, 2025Effective decision-making often relies on timely insights from complex visual data. While Information Visualization (InfoVis) dashboards can support this process, they rarely adapt to users' cognitive state, and less so in real time. We present Symbiotik, an intelligent, context-aware adaptive visualization system that leverages neurophysiological signals to estimate mental workload (MWL) and dynamically adapt visual dashboards using reinforcement learning (RL). Through a user study with 120 participants and three visualization types, we demonstrate that our approach improves task performance and engagement. Symbiotik offers a scalable, real-time adaptation architecture, and a validated methodology for neuroadaptive user interfaces.
Integrating Cognitive Processing Signals into Language Models: A Review of Advances, Applications and Future Directions
Apr 09, 2025Recently, the integration of cognitive neuroscience in Natural Language Processing (NLP) has gained significant attention. This article provides a critical and timely overview of recent advancements in leveraging cognitive signals, particularly Eye-tracking (ET) signals, to enhance Language Models (LMs) and Multimodal Large Language Models (MLLMs). By incorporating user-centric cognitive signals, these approaches address key challenges, including data scarcity and the environmental costs of training large-scale models. Cognitive signals enable efficient data augmentation, faster convergence, and improved human alignment. The review emphasises the potential of ET data in tasks like Visual Question Answering (VQA) and mitigating hallucinations in MLLMs, and concludes by discussing emerging challenges and research trends.
A Comparative Study of Scanpath Models in Graph-Based Visualization
Apr 01, 2025
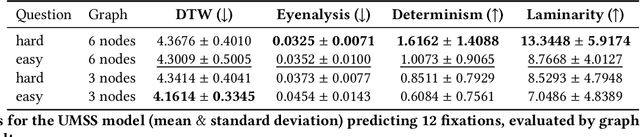
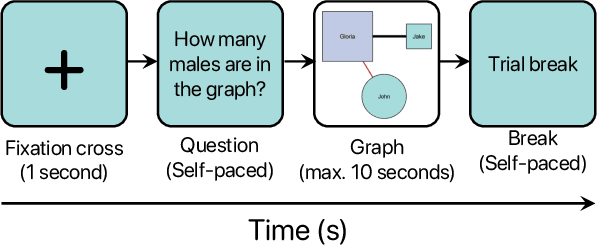
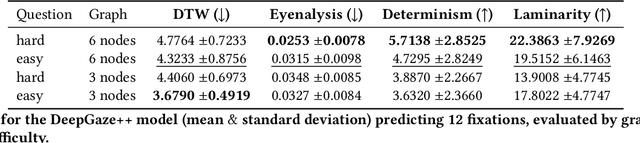
Information Visualization (InfoVis) systems utilize visual representations to enhance data interpretation. Understanding how visual attention is allocated is essential for optimizing interface design. However, collecting Eye-tracking (ET) data presents challenges related to cost, privacy, and scalability. Computational models provide alternatives for predicting gaze patterns, thereby advancing InfoVis research. In our study, we conducted an ET experiment with 40 participants who analyzed graphs while responding to questions of varying complexity within the context of digital forensics. We compared human scanpaths with synthetic ones generated by models such as DeepGaze, UMSS, and Gazeformer. Our research evaluates the accuracy of these models and examines how question complexity and number of nodes influence performance. This work contributes to the development of predictive modeling in visual analytics, offering insights that can enhance the design and effectiveness of InfoVis systems.
OASST-ETC Dataset: Alignment Signals from Eye-tracking Analysis of LLM Responses
Mar 13, 2025
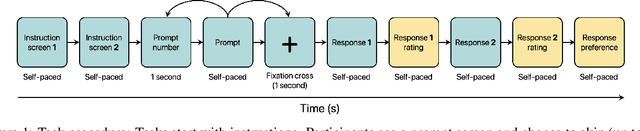


While Large Language Models (LLMs) have significantly advanced natural language processing, aligning them with human preferences remains an open challenge. Although current alignment methods rely primarily on explicit feedback, eye-tracking (ET) data offers insights into real-time cognitive processing during reading. In this paper, we present OASST-ETC, a novel eye-tracking corpus capturing reading patterns from 24 participants, while evaluating LLM-generated responses from the OASST1 dataset. Our analysis reveals distinct reading patterns between preferred and non-preferred responses, which we compare with synthetic eye-tracking data. Furthermore, we examine the correlation between human reading measures and attention patterns from various transformer-based models, discovering stronger correlations in preferred responses. This work introduces a unique resource for studying human cognitive processing in LLM evaluation and suggests promising directions for incorporating eye-tracking data into alignment methods. The dataset and analysis code are publicly available.
Seeing Eye to AI: Human Alignment via Gaze-Based Response Rewards for Large Language Models
Oct 02, 2024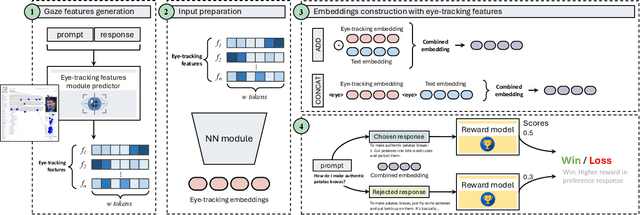

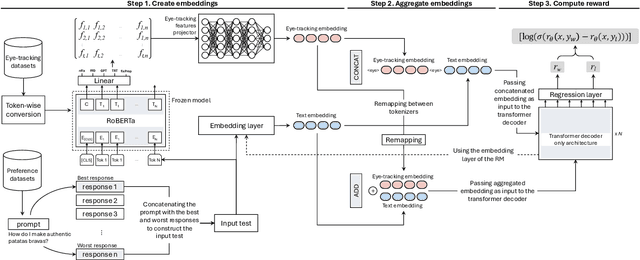

Advancements in Natural Language Processing (NLP), have led to the emergence of Large Language Models (LLMs) such as GPT, Llama, Claude, and Gemini, which excel across a range of tasks but require extensive fine-tuning to align their outputs with human expectations. A widely used method for achieving this alignment is Reinforcement Learning from Human Feedback (RLHF), which, despite its success, faces challenges in accurately modelling human preferences. In this paper, we introduce GazeReward, a novel framework that integrates implicit feedback -- and specifically eye-tracking (ET) data -- into the Reward Model (RM). In addition, we explore how ET-based features can provide insights into user preferences. Through ablation studies we test our framework with different integration methods, LLMs, and ET generator models, demonstrating that our approach significantly improves the accuracy of the RM on established human preference datasets. This work advances the ongoing discussion on optimizing AI alignment with human values, exploring the potential of cognitive data for shaping future NLP research.