 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Scanpath Models in Graph-Based Visualization
Paper and Code
Apr 01, 2025
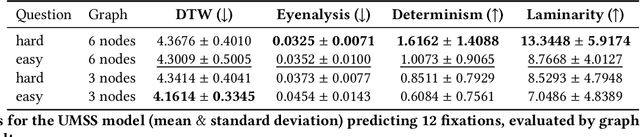
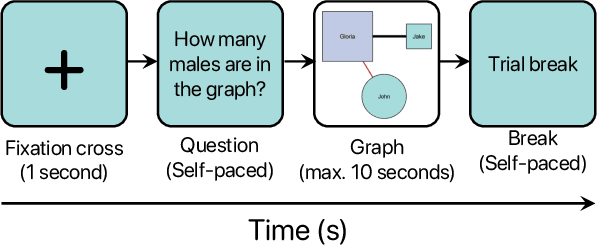
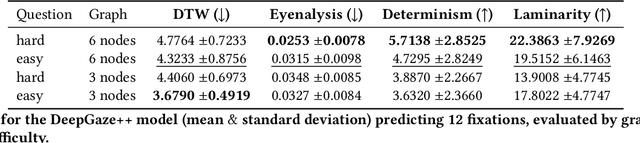
Information Visualization (InfoVis) systems utilize visual representations to enhance data interpretation. Understanding how visual attention is allocated is essential for optimizing interface design. However, collecting Eye-tracking (ET) data presents challenges related to cost, privacy, and scalability. Computational models provide alternatives for predicting gaze patterns, thereby advancing InfoVis research. In our study, we conducted an ET experiment with 40 participants who analyzed graphs while responding to questions of varying complexity within the context of digital forensics. We compared human scanpaths with synthetic ones generated by models such as DeepGaze, UMSS, and Gazeformer. Our research evaluates the accuracy of these models and examines how question complexity and number of nodes influence performance. This work contributes to the development of predictive modeling in visual analytics, offering insights that can enhance the design and effectiveness of InfoVis systems.