 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Adaptive Visualizations for Critical Decision Making
Nov 14, 2025Effective decision-making often relies on timely insights from complex visual data. While Information Visualization (InfoVis) dashboards can support this process, they rarely adapt to users' cognitive state, and less so in real time. We present Symbiotik, an intelligent, context-aware adaptive visualization system that leverages neurophysiological signals to estimate mental workload (MWL) and dynamically adapt visual dashboards using reinforcement learning (RL). Through a user study with 120 participants and three visualization types, we demonstrate that our approach improves task performance and engagement. Symbiotik offers a scalable, real-time adaptation architecture, and a validated methodology for neuroadaptive user interfaces.
A Comparative Study of Scanpath Models in Graph-Based Visualization
Apr 01, 2025
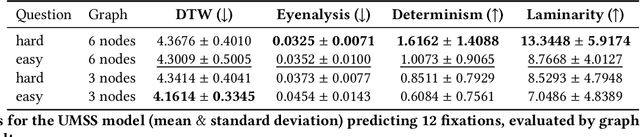
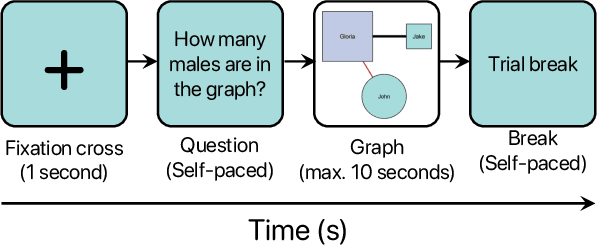
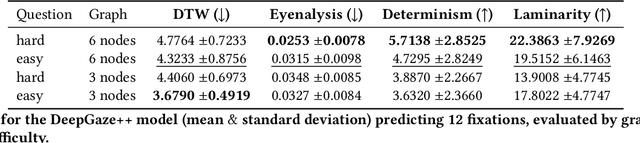
Information Visualization (InfoVis) systems utilize visual representations to enhance data interpretation. Understanding how visual attention is allocated is essential for optimizing interface design. However, collecting Eye-tracking (ET) data presents challenges related to cost, privacy, and scalability. Computational models provide alternatives for predicting gaze patterns, thereby advancing InfoVis research. In our study, we conducted an ET experiment with 40 participants who analyzed graphs while responding to questions of varying complexity within the context of digital forensics. We compared human scanpaths with synthetic ones generated by models such as DeepGaze, UMSS, and Gazeformer. Our research evaluates the accuracy of these models and examines how question complexity and number of nodes influence performance. This work contributes to the development of predictive modeling in visual analytics, offering insights that can enhance the design and effectiveness of InfoVis systems.
Transfer Learning for Covert Speech Classification Using EEG Hilbert Envelope and Temporal Fine Structure
Feb 06, 2025



Brain-Computer Interfaces (BCIs) can decode imagined speech from neural activity. However, these systems typically require extensive training sessions where participants imaginedly repeat words, leading to mental fatigue and difficulties identifying the onset of words, especially when imagining sequences of words. This paper addresses these challenges by transferring a classifier trained in overt speech data to covert speech classification. We used electroencephalogram (EEG) features derived from the Hilbert envelope and temporal fine structure, and used them to train a bidirectional long-short-term memory (BiLSTM) model for classification. Our method reduces the burden of extensive training and achieves state-of-the-art classification accuracy: 86.44% for overt speech and 79.82% for covert speech using the overt speech classifier.