 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond One-Size-Fits-All: A Study of Neural and Behavioural Variability Across Different Recommendation Categories
Jun 16, 2025Traditionally, Recommender Systems (RS) have primarily measured performance based on the accuracy and relevance of their recommendations. However, this algorithmic-centric approach overlooks how different types of recommendations impact user engagement and shape the overall quality of experience. In this paper, we shift the focus to the user and address for the first time the challenge of decoding the neural and behavioural variability across distinct recommendation categories, considering more than just relevance. Specifically, we conducted a controlled study using a comprehensive e-commerce dataset containing various recommendation types, and collected Electroencephalography and behavioural data. We analysed both neural and behavioural responses to recommendations that were categorised as Exact, Substitute, Complement, or Irrelevant products within search query results. Our findings offer novel insights into user preferences and decision-making processes, revealing meaningful relationships between behavioural and neural patterns for each category, but also indicate inter-subject variability.
Seeing Eye to AI: Human Alignment via Gaze-Based Response Rewards for Large Language Models
Oct 02, 2024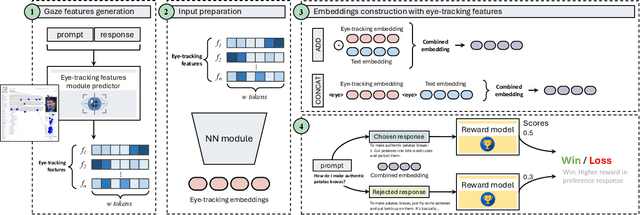

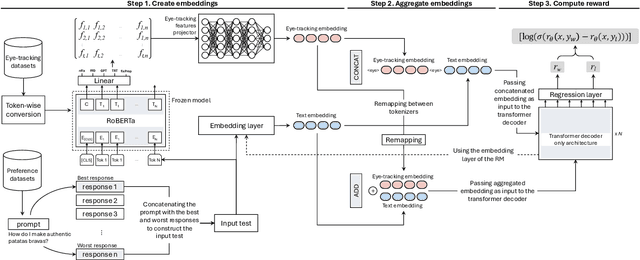

Advancements in Natural Language Processing (NLP), have led to the emergence of Large Language Models (LLMs) such as GPT, Llama, Claude, and Gemini, which excel across a range of tasks but require extensive fine-tuning to align their outputs with human expectations. A widely used method for achieving this alignment is Reinforcement Learning from Human Feedback (RLHF), which, despite its success, faces challenges in accurately modelling human preferences. In this paper, we introduce GazeReward, a novel framework that integrates implicit feedback -- and specifically eye-tracking (ET) data -- into the Reward Model (RM). In addition, we explore how ET-based features can provide insights into user preferences. Through ablation studies we test our framework with different integration methods, LLMs, and ET generator models, demonstrating that our approach significantly improves the accuracy of the RM on established human preference datasets. This work advances the ongoing discussion on optimizing AI alignment with human values, exploring the potential of cognitive data for shaping future NLP research.
Diffusion Models for Tabular Data Imputation and Synthetic Data Generation
Jul 02, 2024



Data imputation and data generation have important applications for many domains, like healthcare and finance, where incomplete or missing data can hinder accurate analysis and decision-making. Diffusion models have emerged as powerful generative models capable of capturing complex data distributions across various data modalities such as image, audio, and time series data. Recently, they have been also adapted to generate tabular data. In this paper, we propose a diffusion model for tabular data that introduces three key enhancements: (1) a conditioning attention mechanism, (2) an encoder-decoder transformer as the denoising network, and (3) dynamic masking. The conditioning attention mechanism is designed to improve the model's ability to capture the relationship between the condition and synthetic data. The transformer layers help model interactions within the condition (encoder) or synthetic data (decoder), while dynamic masking enables our model to efficiently handle both missing data imputation and synthetic data generation tasks within a unified framework. We conduct a comprehensive evaluation by comparing the performance of diffusion models with transformer conditioning against state-of-the-art techniques, such as Variational Autoencoders, Generative Adversarial Networks and Diffusion Models, on benchmark datasets. Our evaluation focuses on the assessment of the generated samples with respect to three important criteria, namely: (1) Machine Learning efficiency, (2) statistical similarity, and (3) privacy risk mitigation. For the task of data imputation, we consider the efficiency of the generated samples across different levels of missing features.
Future Trends in the Design of Memetic Algorithms: the Case of the Linear Ordering Problem
May 14, 2024The way heuristic optimizers are designed has evolved over the decades, as computing power has increased. Initially, trajectory metaheuristics used to shape the state of the art in many problems, whereas today, population-based mechanisms tend to be more effective.Such has been the case for the Linear Ordering Problem (LOP), a field in which strategies such as Iterated Local Search and Variable Neighborhood Search led the way during the 1990s, but which have now been surpassed by evolutionary and memetic schemes. This paper focuses on understanding how the design of LOP optimizers will change in the future, as computing power continues to increase, yielding two main contributions. On the one hand, a metaheuristic was designed that is capable of effectively exploiting a large amount of computational resources, specifically, computing power equivalent to what a recent core can output during runs lasting over four months. Our analysis of this aspect relied on parallelization, and allowed us to conclude that as the power of the computational resources increases, it will be necessary to boost the capacities of the intensification methods applied in the memetic algorithms to keep the population from stagnating. And on the other, the best-known results for today's most challenging set of instances (xLOLIB2) were significantly outperformed. Instances with sizes ranging from 300 to 1000 were analyzed, and new bounds were established that provide a frame of reference for future research.
Robust Wake-Up Word Detection by Two-stage Multi-resolution Ensembles
Oct 17, 2023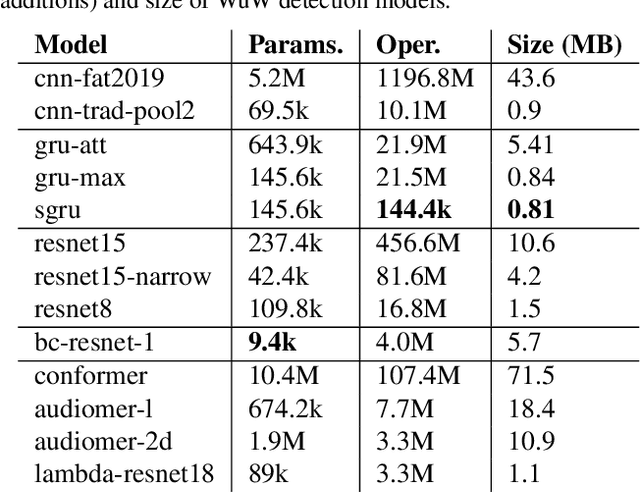
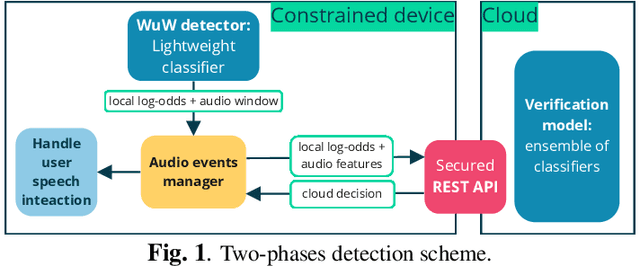
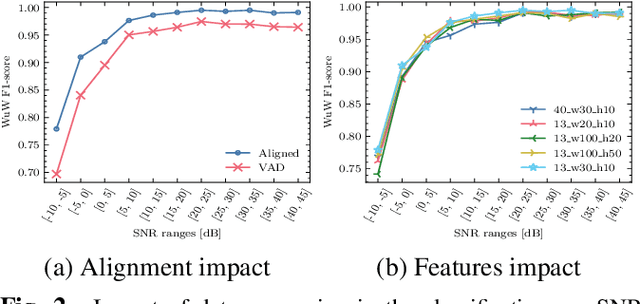
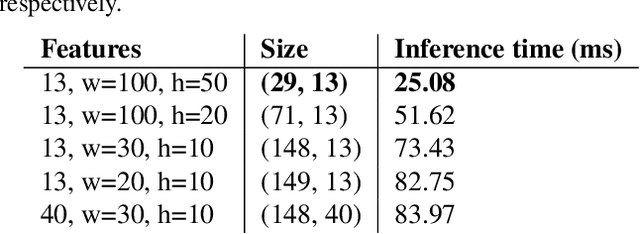
Voice-based interfaces rely on a wake-up word mechanism to initiate communication with devices. However, achieving a robust, energy-efficient, and fast detection remains a challenge. This paper addresses these real production needs by enhancing data with temporal alignments and using detection based on two phases with multi-resolution. It employs two models: a lightweight on-device model for real-time processing of the audio stream and a verification model on the server-side, which is an ensemble of heterogeneous architectures that refine detection. This scheme allows the optimization of two operating points. To protect privacy, audio features are sent to the cloud instead of raw audio. The study investigated different parametric configurations for feature extraction to select one for on-device detection and another for the verification model. Furthermore, thirteen different audio classifiers were compared in terms of performance and inference time. The proposed ensemble outperforms our stronger classifier in every noise condition.
Scheduling Inference Workloads on Distributed Edge Clusters with Reinforcement Learning
Jan 31, 2023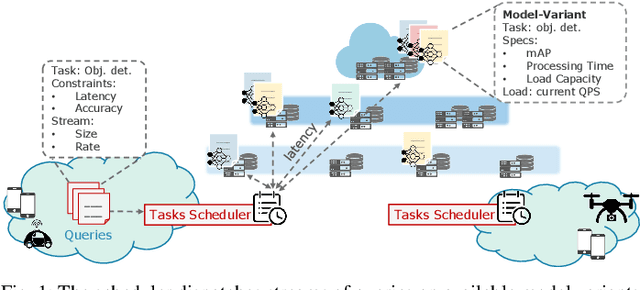
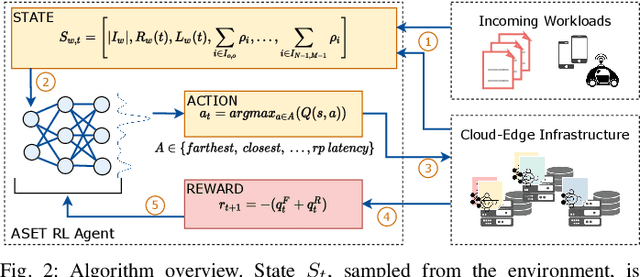
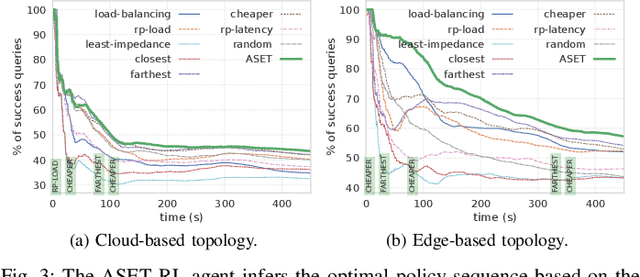
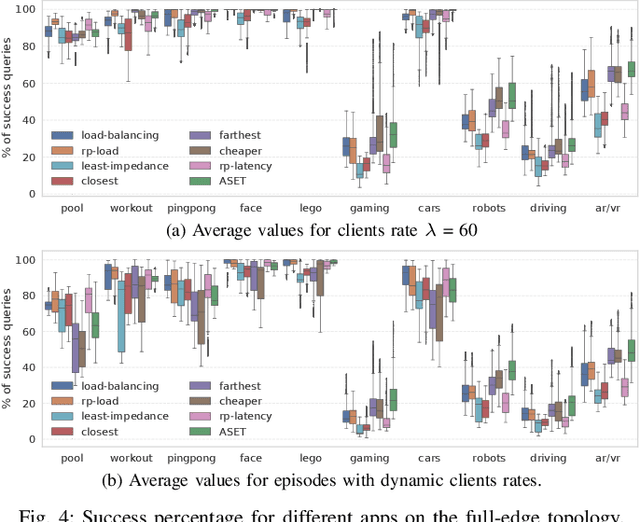
Many real-time applications (e.g., Augmented/Virtual Reality, cognitive assistance) rely on Deep Neural Networks (DNNs) to process inference tasks. Edge computing is considered a key infrastructure to deploy such applications, as moving computation close to the data sources enables us to meet stringent latency and throughput requirements. However, the constrained nature of edge networks poses several additional challenges to the management of inference workloads: edge clusters can not provide unlimited processing power to DNN models, and often a trade-off between network and processing time should be considered when it comes to end-to-end delay requirements. In this paper, we focus on the problem of scheduling inference queries on DNN models in edge networks at short timescales (i.e., few milliseconds). By means of simulations, we analyze several policies in the realistic network settings and workloads of a large ISP, highlighting the need for a dynamic scheduling policy that can adapt to network conditions and workloads. We therefore design ASET, a Reinforcement Learning based scheduling algorithm able to adapt its decisions according to the system conditions. Our results show that ASET effectively provides the best performance compared to static policies when scheduling over a distributed pool of edge resources.
Efficient Keyword Spotting through long-range interactions with Temporal Lambda Networks
Apr 16, 2021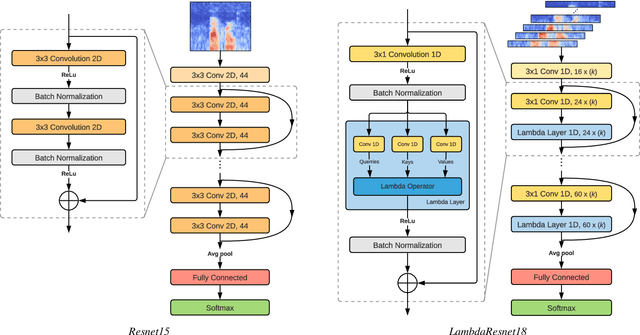
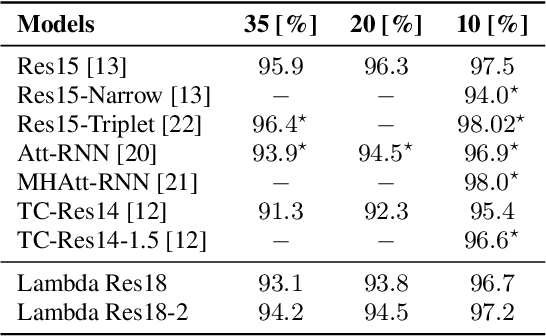
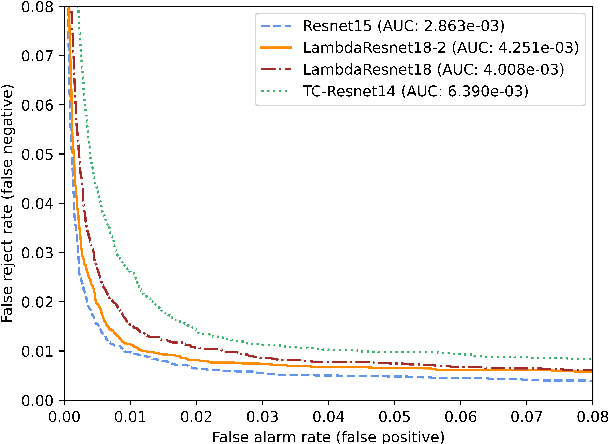
Recent models based on attention mechanisms have shown unprecedented performance in the speech recognition domain. These are computational expensive and unnecessarily complex for the keyword spotting task where its main usage is in small-footprint devices. This work explores the application of the Lambda networks, a framework for capturing long-range interactions, within this spotting task. The proposed architecture is inspired by current state-of-the-art models for keyword spotting built on residual connections. Our main contribution consists on swapping the residual blocks by temporal Lambda layers thus bypassing the expensive computation of attention maps, largely reducing the model complexity. Furthermore, the proposed Lambda network is built upon uni-dimensional convolutions which also dramatically decreases the number of floating point operations performed along the inference stage. This architecture does not only reach state-of-the-art accuracies on the Google Speech Commands dataset, but it is 85% and 65% lighter than its multi headed attention (MHAtt-RNN) and residual convolutional (Res15) counterparts, while being up to 100x faster than them. To the best of our knowledge, this is the first attempt to examine the Lambda framework within the speech domain and therefore, we unravel further research and development of future speech interfaces based on this architecture.
Speech Enhancement for Wake-Up-Word detection in Voice Assistants
Jan 29, 2021
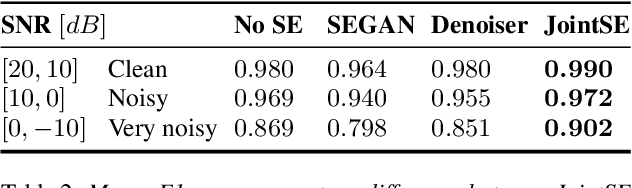
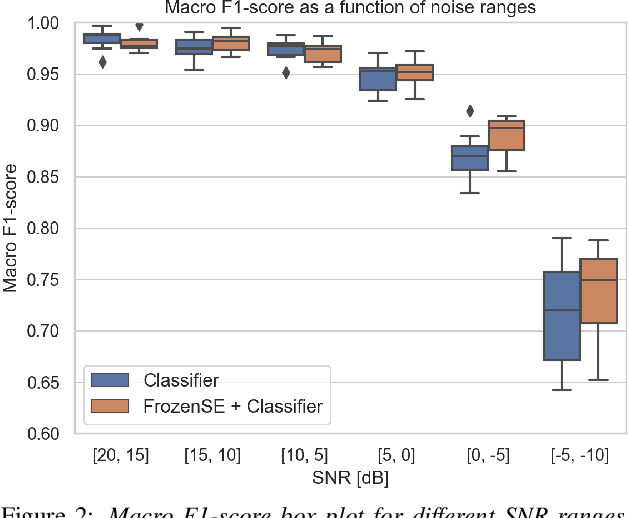
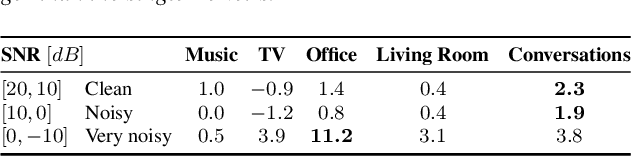
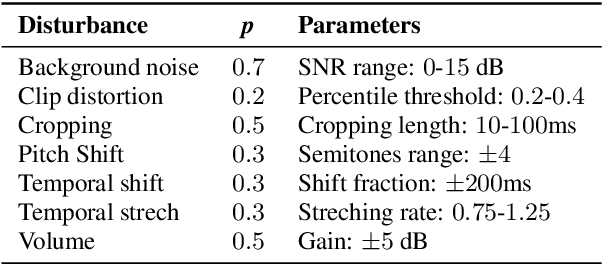
Keyword spotting and in particular Wake-Up-Word (WUW) detection is a very important task for voice assistants. A very common issue of voice assistants is that they get easily activated by background noise like music, TV or background speech that accidentally triggers the device. In this paper, we propose a Speech Enhancement (SE) model adapted to the task of WUW detection that aims at increasing the recognition rate and reducing the false alarms in the presence of these types of noises. The SE model is a fully-convolutional denoising auto-encoder at waveform level and is trained using a log-Mel Spectrogram and waveform reconstruction losses together with the BCE loss of a simple WUW classification network. A new database has been purposely prepared for the task of recognizing the WUW in challenging conditions containing negative samples that are very phonetically similar to the keyword. The database is extended with public databases and an exhaustive data augmentation to simulate different noises and environments. The results obtained by concatenating the SE with a simple and state-of-the-art WUW detectors show that the SE does not have a negative impact on the recognition rate in quiet environments while increasing the performance in the presence of noise, especially when the SE and WUW detector are trained jointly end-to-end.
Enabling Zero-shot Multilingual Spoken Language Translation with Language-Specific Encoders and Decoders
Nov 02, 2020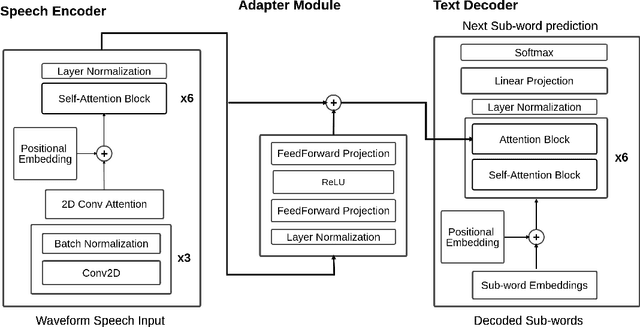
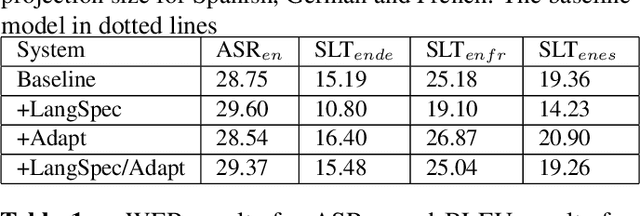
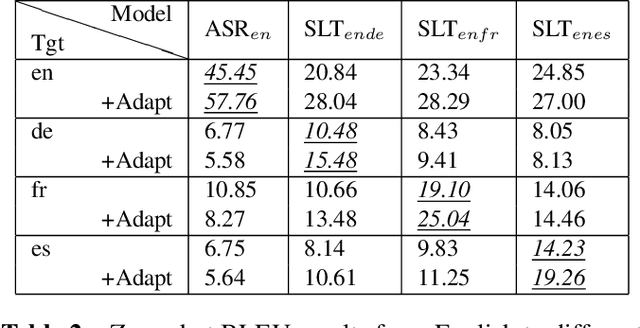
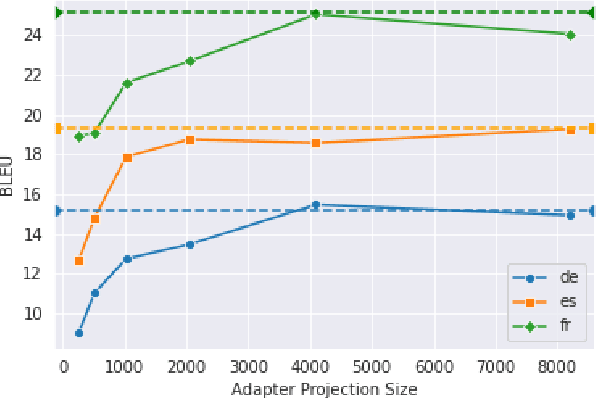
Current end-to-end approaches to Spoken Language Translation (SLT) rely on limited training resources, especially for multilingual settings. On the other hand, Multilingual Neural Machine Translation (MultiNMT) approaches rely on higher quality and more massive data sets. Our proposed method extends a MultiNMT architecture based on language-specific encoders-decoders to the task of Multilingual SLT (MultiSLT) Our experiments on four different languages show that coupling the speech encoder to the MultiNMT architecture produces similar quality translations compared to a bilingual baseline ($\pm 0.2$ BLEU) while effectively allowing for zero-shot MultiSLT. Additionally, we propose using Adapter networks for SLT that produce consistent improvements of +1 BLEU points in all tested languages.
Seeing and Hearing Egocentric Actions: How Much Can We Learn?
Oct 15, 2019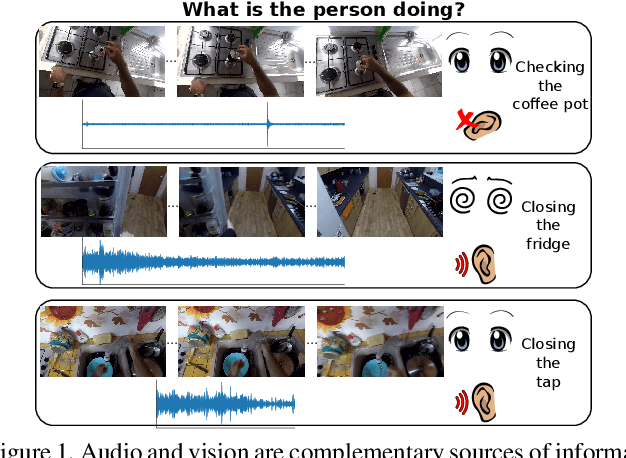
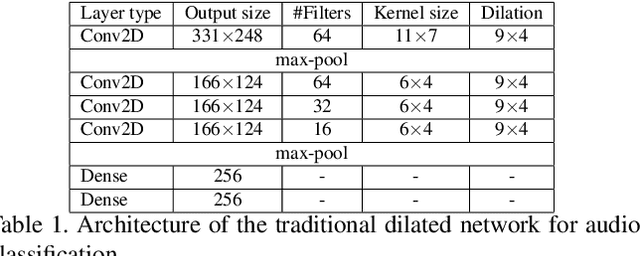
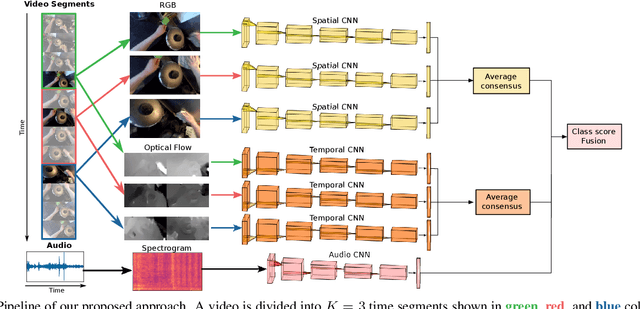
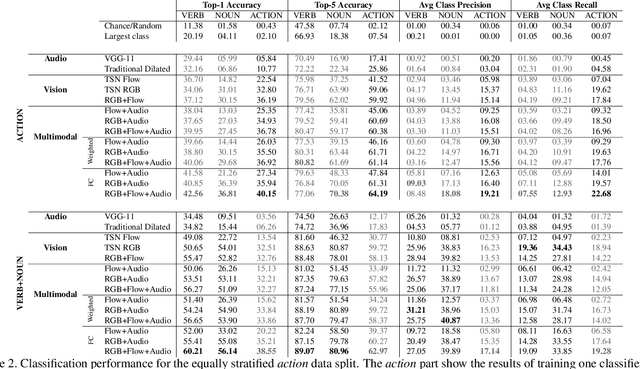
Our interaction with the world is an inherently multimodal experience. However, the understanding of human-to-object interactions has historically been addressed focusing on a single modality. In particular, a limited number of works have considered to integrate the visual and audio modalities for this purpose. In this work, we propose a multimodal approach for egocentric action recognition in a kitchen environment that relies on audio and visual information. Our model combines a sparse temporal sampling strategy with a late fusion of audio, spatial, and temporal streams. Experimental results on the EPIC-Kitchens dataset show that multimodal integration leads to better performance than unimodal approaches. In particular, we achieved a 5.18% improvement over the state of the art on verb classification.