 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
Temporal Context Consistency Above All: Enhancing Long-Term Anticipation by Learning and Enforcing Temporal Constraints
Dec 27, 2024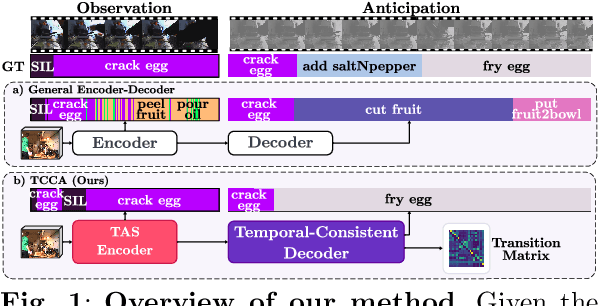
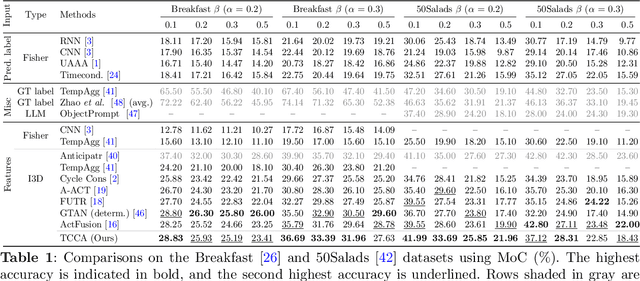
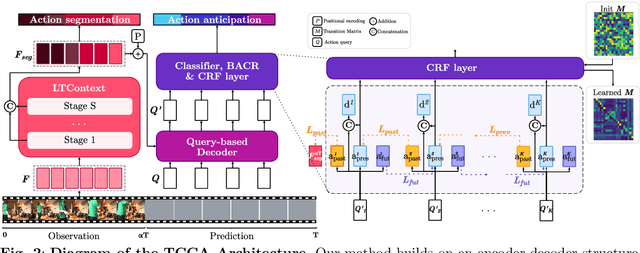
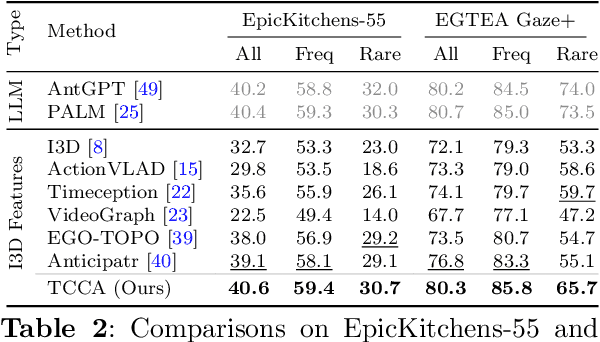
This paper proposes a method for long-term action anticipation (LTA), the task of predicting action labels and their duration in a video given the observation of an initial untrimmed video interval. We build on an encoder-decoder architecture with parallel decoding and make two key contributions. First, we introduce a bi-directional action context regularizer module on the top of the decoder that ensures temporal context coherence in temporally adjacent segments. Second, we learn from classified segments a transition matrix that models the probability of transitioning from one action to another and the sequence is optimized globally over the full prediction interval. In addition, we use a specialized encoder for the task of action segmentation to increase the quality of the predictions in the observation interval at inference time, leading to a better understanding of the past. We validate our methods on four benchmark datasets for LTA, the EpicKitchen-55, EGTEA+, 50Salads and Breakfast demonstrating superior or comparable performance to state-of-the-art methods, including probabilistic models and also those based on Large Language Models, that assume trimmed video as input. The code will be released upon acceptance.
2by2: Weakly-Supervised Learning for Global Action Segmentation
Dec 17, 2024This paper presents a simple yet effective approach for the poorly investigated task of global action segmentation, aiming at grouping frames capturing the same action across videos of different activities. Unlike the case of videos depicting all the same activity, the temporal order of actions is not roughly shared among all videos, making the task even more challenging. We propose to use activity labels to learn, in a weakly-supervised fashion, action representations suitable for global action segmentation. For this purpose, we introduce a triadic learning approach for video pairs, to ensure intra-video action discrimination, as well as inter-video and inter-activity action association. For the backbone architecture, we use a Siamese network based on sparse transformers that takes as input video pairs and determine whether they belong to the same activity. The proposed approach is validated on two challenging benchmark datasets: Breakfast and YouTube Instructions, outperforming state-of-the-art methods.
3M-TRANSFORMER: A Multi-Stage Multi-Stream Multimodal Transformer for Embodied Turn-Taking Prediction
Nov 01, 2023Predicting turn-taking in multiparty conversations has many practical applications in human-computer/robot interaction. However, the complexity of human communication makes it a challenging task. Recent advances have shown that synchronous multi-perspective egocentric data can significantly improve turn-taking prediction compared to asynchronous, single-perspective transcriptions. Building on this research, we propose a new multimodal transformer-based architecture for predicting turn-taking in embodied, synchronized multi-perspective data. Our experimental results on the recently introduced EgoCom dataset show a substantial performance improvement of up to 14.01% on average compared to existing baselines and alternative transformer-based approaches. The source code, and the pre-trained models of our 3M-Transformer will be available upon acceptance.
Debiased-CAM to mitigate systematic error with faithful visual explanations of machine learning
Jan 30, 2022Model explanations such as saliency maps can improve user trust in AI by highlighting important features for a prediction. However, these become distorted and misleading when explaining predictions of images that are subject to systematic error (bias). Furthermore, the distortions persist despite model fine-tuning on images biased by different factors (blur, color temperature, day/night). We present Debiased-CAM to recover explanation faithfulness across various bias types and levels by training a multi-input, multi-task model with auxiliary tasks for explanation and bias level predictions. In simulation studies, the approach not only enhanced prediction accuracy, but also generated highly faithful explanations about these predictions as if the images were unbiased. In user studies, debiased explanations improved user task performance, perceived truthfulness and perceived helpfulness. Debiased training can provide a versatile platform for robust performance and explanation faithfulness for a wide range of applications with data biases.
Enhancing Egocentric 3D Pose Estimation with Third Person Views
Jan 07, 2022


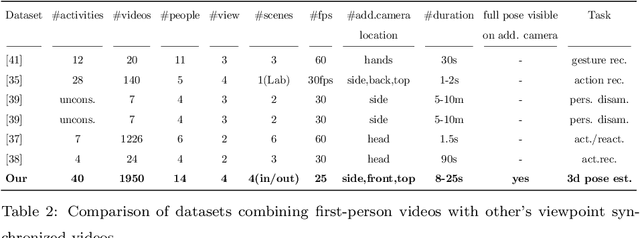
In this paper, we propose a novel approach to enhance the 3D body pose estimation of a person computed from videos captured from a single wearable camera. The key idea is to leverage high-level features linking first- and third-views in a joint embedding space. To learn such embedding space we introduce First2Third-Pose, a new paired synchronized dataset of nearly 2,000 videos depicting human activities captured from both first- and third-view perspectives. We explicitly consider spatial- and motion-domain features, combined using a semi-Siamese architecture trained in a self-supervised fashion. Experimental results demonstrate that the joint multi-view embedded space learned with our dataset is useful to extract discriminatory features from arbitrary single-view egocentric videos, without needing domain adaptation nor knowledge of camera parameters. We achieve significant improvement of egocentric 3D body pose estimation performance on two unconstrained datasets, over three supervised state-of-the-art approaches. Our dataset and code will be available for research purposes.
Learning grounded word meaning representations on similarity graphs
Sep 07, 2021
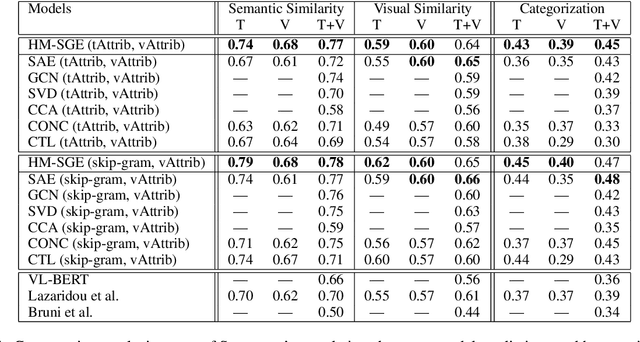
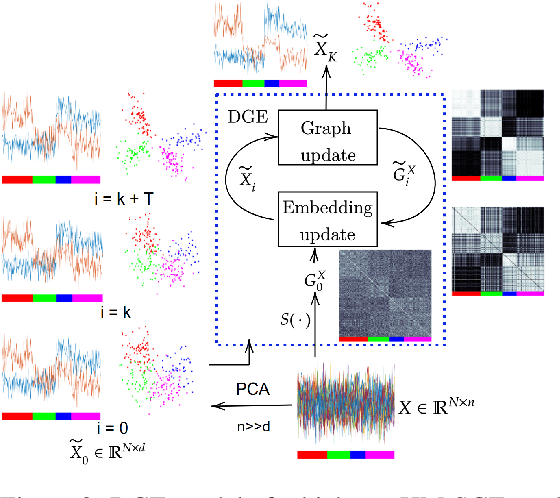
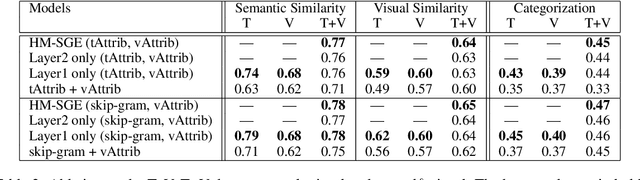
This paper introduces a novel approach to learn visually grounded meaning representations of words as low-dimensional node embeddings on an underlying graph hierarchy. The lower level of the hierarchy models modality-specific word representations through dedicated but communicating graphs, while the higher level puts these representations together on a single graph to learn a representation jointly from both modalities. The topology of each graph models similarity relations among words, and is estimated jointly with the graph embedding. The assumption underlying this model is that words sharing similar meaning correspond to communities in an underlying similarity graph in a low-dimensional space. We named this model Hierarchical Multi-Modal Similarity Graph Embedding (HM-SGE). Experimental results validate the ability of HM-SGE to simulate human similarity judgements and concept categorization, outperforming the state of the art.
Graph Constrained Data Representation Learning for Human Motion Segmentation
Jul 28, 2021
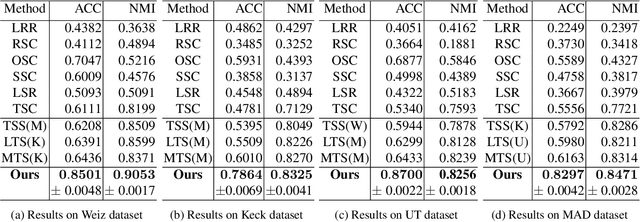

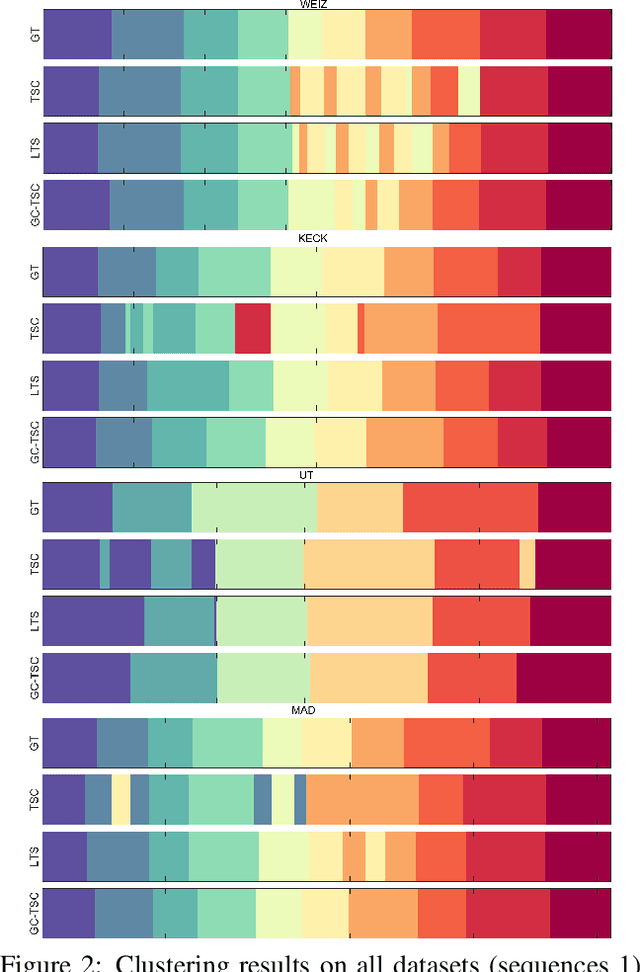
Recently, transfer subspace learning based approaches have shown to be a valid alternative to unsupervised subspace clustering and temporal data clustering for human motion segmentation (HMS). These approaches leverage prior knowledge from a source domain to improve clustering performance on a target domain, and currently they represent the state of the art in HMS. Bucking this trend, in this paper, we propose a novel unsupervised model that learns a representation of the data and digs clustering information from the data itself. Our model is reminiscent of temporal subspace clustering, but presents two critical differences. First, we learn an auxiliary data matrix that can deviate from the initial data, hence confer more degrees of freedom to the coding matrix. Second, we introduce a regularization term for this auxiliary data matrix that preserves the local geometrical structure present in the high-dimensional space. The proposed model is efficiently optimized by using an original Alternating Direction Method of Multipliers (ADMM) formulation allowing to learn jointly the auxiliary data representation, a nonnegative dictionary and a coding matrix. Experimental results on four benchmark datasets for HMS demonstrate that our approach achieves significantly better clustering performance then state-of-the-art methods, including both unsupervised and more recent semi-supervised transfer learning approaches.
Interaction-GCN: a Graph Convolutional Network based framework for social interaction recognition in egocentric videos
Apr 28, 2021
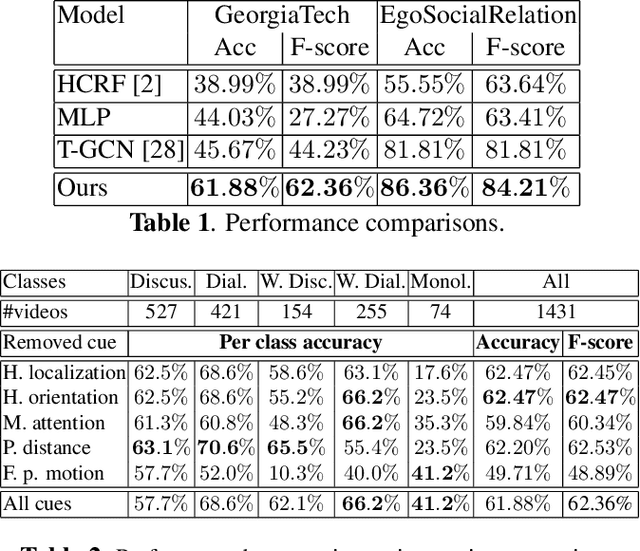
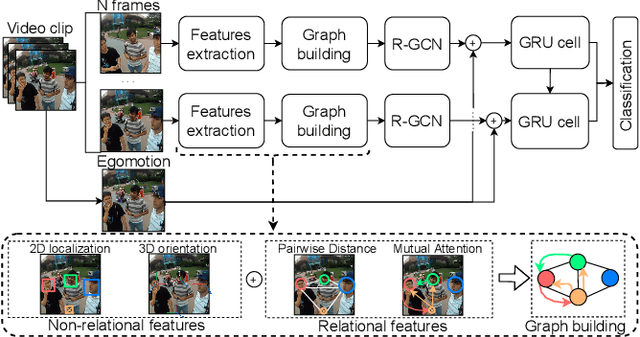
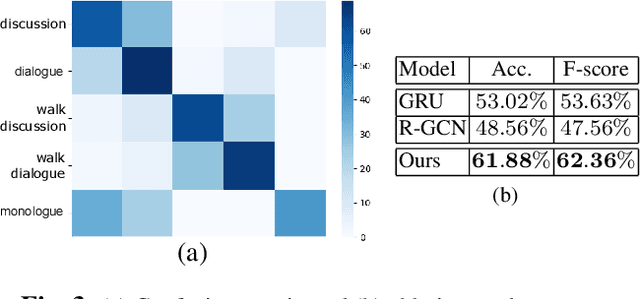
In this paper we propose a new framework to categorize social interactions in egocentric videos, we named InteractionGCN. Our method extracts patterns of relational and non-relational cues at the frame level and uses them to build a relational graph from which the interactional context at the frame level is estimated via a Graph Convolutional Network based approach. Then it propagates this context over time, together with first-person motion information, through a Gated Recurrent Unit architecture. Ablation studies and experimental evaluation on two publicly available datasets validate the proposed approach and establish state of the art results.
Modeling long-term interactions to enhance action recognition
Apr 23, 2021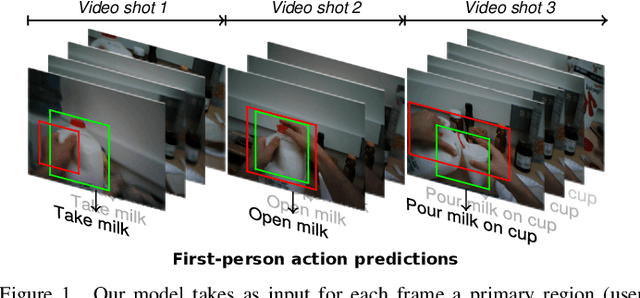

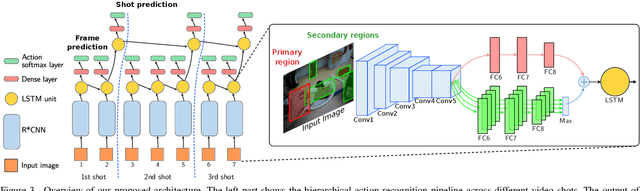
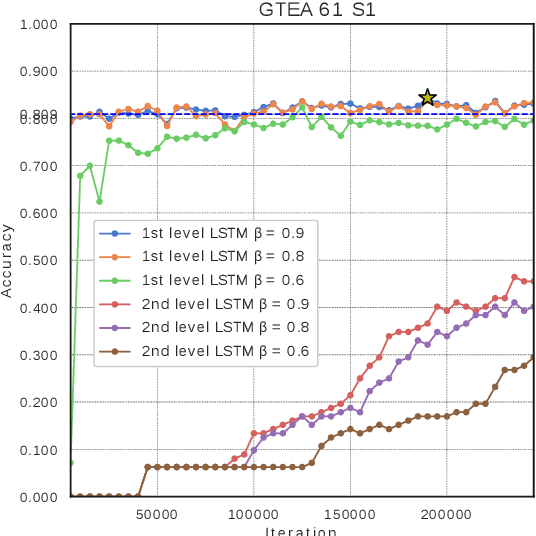
In this paper, we propose a new approach to under-stand actions in egocentric videos that exploits the semantics of object interactions at both frame and temporal levels. At the frame level, we use a region-based approach that takes as input a primary region roughly corresponding to the user hands and a set of secondary regions potentially corresponding to the interacting objects and calculates the action score through a CNN formulation. This information is then fed to a Hierarchical LongShort-Term Memory Network (HLSTM) that captures temporal dependencies between actions within and across shots. Ablation studies thoroughly validate the proposed approach, showing in particular that both levels of the HLSTM architecture contribute to performance improvement. Furthermore, quantitative comparisons show that the proposed approach outperforms the state-of-the-art in terms of action recognition on standard benchmarks,without relying on motion information