 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining On-Policy Optimization and Distillation for Long-Context Reasoning in Large Language Models
May 12, 2026Adapting large language models (LLMs) to long-context tasks requires post-training methods that remain accurate and coherent over thousands of tokens. Existing approaches are limited in several ways: 1) off-policy methods such as supervised fine-tuning (SFT) and knowledge distillation (KD) suffer from exposure bias and limited recovery from model-generated errors over long horizons; 2) on-policy reinforcement learning methods such as Group Relative Policy Optimization (GRPO) better align training with model-generated states, but are unstable and sample-inefficient due to sparse rewards; 3) on-policy distillation (OPD) provides dense token-level guidance, but does not directly optimize arbitrary reward signals. In this paper, we propose Distilled Group Relative Policy Optimization (dGRPO), a method for long-context reasoning that augments GRPO with dense guidance from a stronger teacher via OPD. We also introduce LongBlocks, a synthetic long-context dataset spanning multi-hop reasoning, contextual grounding, and long-form generation. We conduct extensive experiments and ablations comparing off-policy training, sparse-reward GRPO, and our combined approach, leading to an improved recipe for long-context alignment. Overall, our results show that combining outcome-based policy optimization with knowledge distillation in a single objective provides a more stable and effective path to long-context reasoning, while preserving short-context capabilities.
AMALIA Technical Report: A Fully Open Source Large Language Model for European Portuguese
Mar 27, 2026Despite rapid progress in open large language models (LLMs), European Portuguese (pt-PT) remains underrepresented in both training data and native evaluation, with machine-translated benchmarks likely missing the variant's linguistic and cultural nuances. We introduce AMALIA, a fully open LLM that prioritizes pt-PT by using more high-quality pt-PT data during both the mid- and post-training stages. To evaluate pt-PT more faithfully, we release a suite of pt-PT benchmarks that includes translated standard tasks and four new datasets targeting pt-PT generation, linguistic competence, and pt-PT/pt-BR bias. Experiments show that AMALIA matches strong baselines on translated benchmarks while substantially improving performance on pt-PT-specific evaluations, supporting the case for targeted training and native benchmarking for European Portuguese.
EuroLLM-22B: Technical Report
Feb 05, 2026This report presents EuroLLM-22B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-22B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. Across a broad set of multilingual benchmarks, EuroLLM-22B demonstrates strong performance in reasoning, instruction following, and translation, achieving results competitive with models of comparable size. To support future research, we release our base and instruction-tuned models, our multilingual web pretraining data and updated EuroBlocks instruction datasets, as well as our pre-training and evaluation codebases.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
Multilingual Contextualization of Large Language Models for Document-Level Machine Translation
Apr 16, 2025

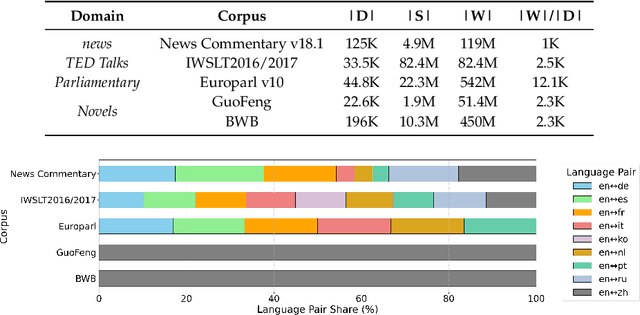
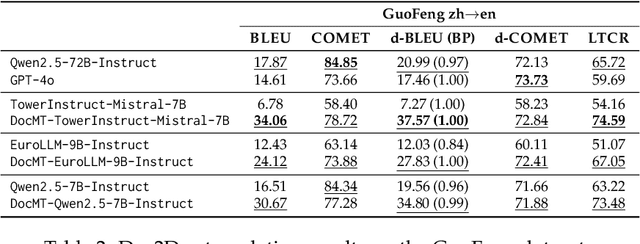
Large language models (LLMs) have demonstrated strong performance in sentence-level machine translation, but scaling to document-level translation remains challenging, particularly in modeling long-range dependencies and discourse phenomena across sentences and paragraphs. In this work, we propose a method to improve LLM-based long-document translation through targeted fine-tuning on high-quality document-level data, which we curate and introduce as DocBlocks. Our approach supports multiple translation paradigms, including direct document-to-document and chunk-level translation, by integrating instructions both with and without surrounding context. This enables models to better capture cross-sentence dependencies while maintaining strong sentence-level translation performance. Experimental results show that incorporating multiple translation paradigms improves document-level translation quality and inference speed compared to prompting and agent-based methods.
Fine-Grained Reward Optimization for Machine Translation using Error Severity Mappings
Nov 08, 2024
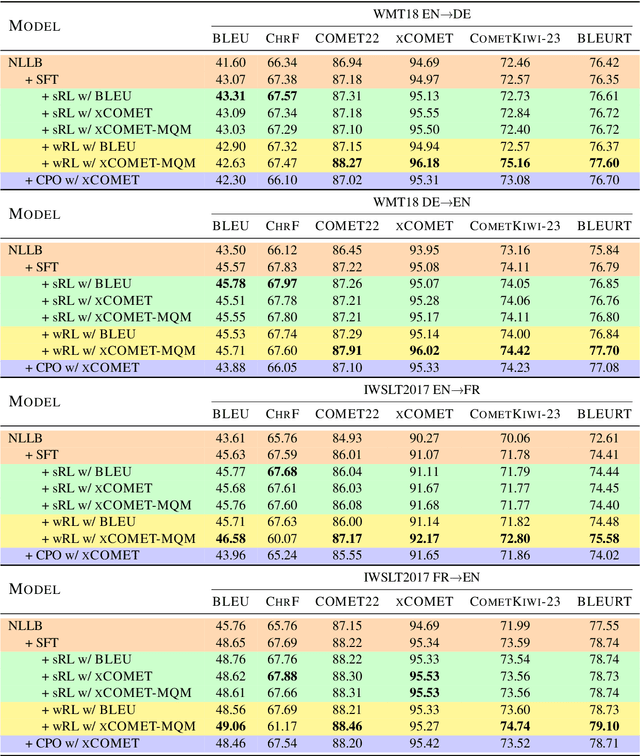
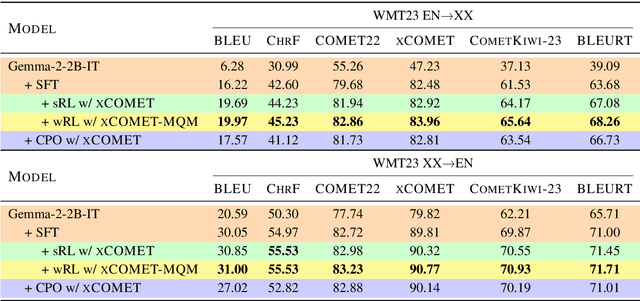
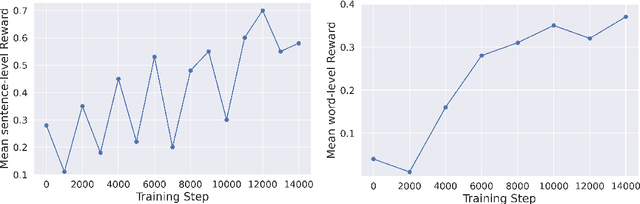
Reinforcement learning (RL) has been proven to be an effective and robust method for training neural machine translation systems, especially when paired with powerful reward models that accurately assess translation quality. However, most research has focused on RL methods that use sentence-level feedback, which leads to inefficient learning signals due to the reward sparsity problem -- the model receives a single score for the entire sentence. To address this, we introduce a novel approach that leverages fine-grained token-level reward mechanisms with RL methods. We use xCOMET, a state-of-the-art quality estimation system as our token-level reward model. xCOMET provides detailed feedback by predicting fine-grained error spans and their severity given source-translation pairs. We conduct experiments on small and large translation datasets to compare the impact of sentence-level versus fine-grained reward signals on translation quality. Our results show that training with token-level rewards improves translation quality across language pairs over baselines according to automatic and human evaluation. Furthermore, token-level reward optimization also improves training stability, evidenced by a steady increase in mean rewards over training epochs.
Aligning Neural Machine Translation Models: Human Feedback in Training and Inference
Nov 15, 2023



Reinforcement learning from human feedback (RLHF) is a recent technique to improve the quality of the text generated by a language model, making it closer to what humans would generate. A core ingredient in RLHF's success in aligning and improving large language models (LLMs) is its reward model, trained using human feedback on model outputs. In machine translation (MT), where metrics trained from human annotations can readily be used as reward models, recent methods using minimum Bayes risk decoding and reranking have succeeded in improving the final quality of translation. In this study, we comprehensively explore and compare techniques for integrating quality metrics as reward models into the MT pipeline. This includes using the reward model for data filtering, during the training phase through RL, and at inference time by employing reranking techniques, and we assess the effects of combining these in a unified approach. Our experimental results, conducted across multiple translation tasks, underscore the crucial role of effective data filtering, based on estimated quality, in harnessing the full potential of RL in enhancing MT quality. Furthermore, our findings demonstrate the effectiveness of combining RL training with reranking techniques, showcasing substantial improvements in translation quality.