 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Contextualization of Large Language Models for Document-Level Machine Translation
Paper and Code
Apr 16, 2025

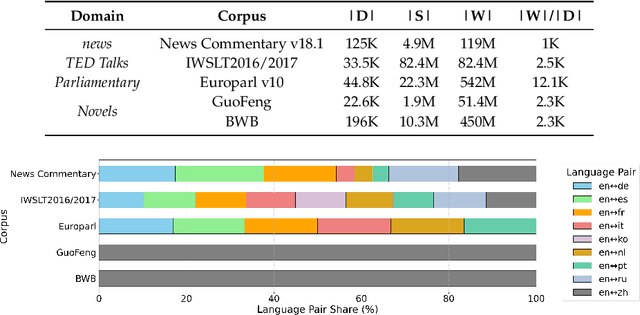
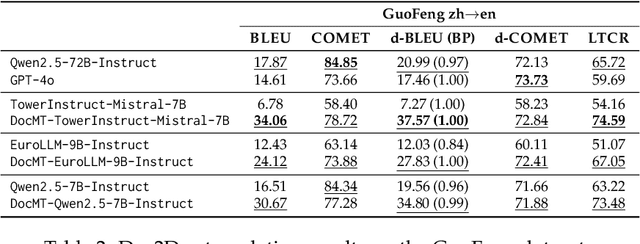
Large language models (LLMs) have demonstrated strong performance in sentence-level machine translation, but scaling to document-level translation remains challenging, particularly in modeling long-range dependencies and discourse phenomena across sentences and paragraphs. In this work, we propose a method to improve LLM-based long-document translation through targeted fine-tuning on high-quality document-level data, which we curate and introduce as DocBlocks. Our approach supports multiple translation paradigms, including direct document-to-document and chunk-level translation, by integrating instructions both with and without surrounding context. This enables models to better capture cross-sentence dependencies while maintaining strong sentence-level translation performance. Experimental results show that incorporating multiple translation paradigms improves document-level translation quality and inference speed compared to prompting and agent-based methods.